_Ef94KquCCP.gif?auto=format%2Ccompress&gifq=35&w=400&h=300&fit=min)


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Fall has become a major cause of injury for senior citizens, it has become the most frequent cause of death for those who are age 65 and above.
High-tech adoption for senior citizens seem to be really lacking, as many products are created at hackathons but very few makes it to the market. And tech products targets senior citizens tends to be expensive due to use cases and market availability.
Luckily, with help of advancement of AI and image classification, object detection, we can build AI within existing cameras to help detecting falls for senior citizens. This way it's relatively inexpensive to install these cameras across senior living spaces
We are planning to use normal camera combined with Nvidia Jetson Nano, this is enough to run near real time AI which includes object detection which can calculate the falling of the person. The camera can be streamed through anywhere, the caretaker will receive a text message whenever a fall is detected and the senior can not get up at that time. Appropriate help will be called upon before major incident happens.
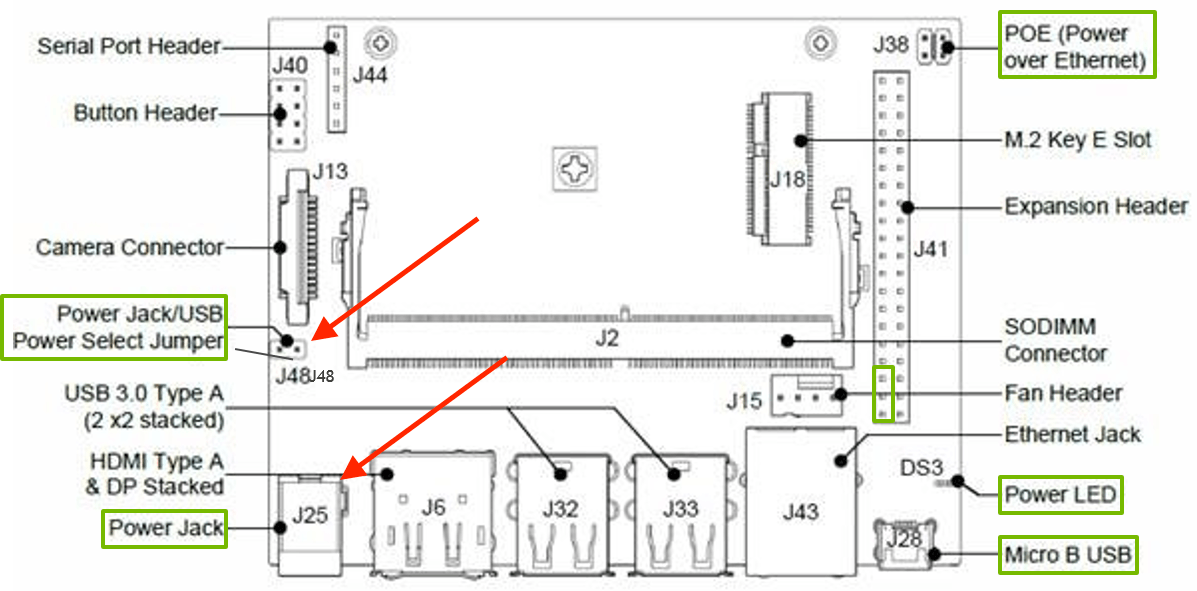
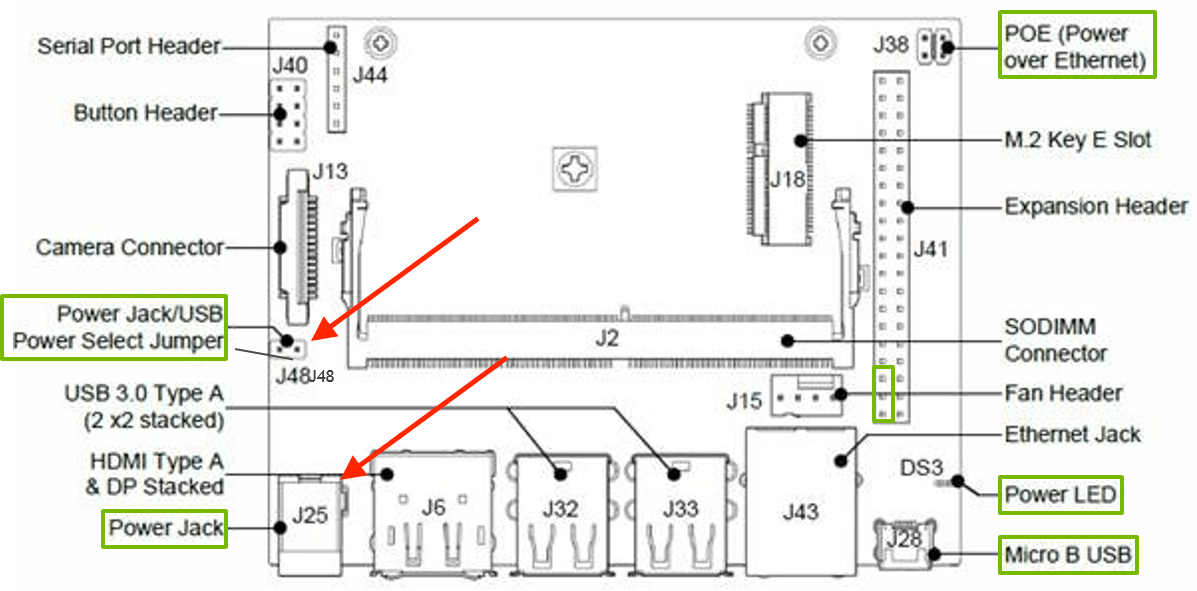
The equipment needed is a Jetson Nano, Camera. Make sure you have at least 5v/2.5 amp power supply, between camera. Personally I've tried 2.1amp and it was not enough. Also, use the power jack over the micro usb power, this has proven to be much more stable. You first need to place a Jumper on J48, then the power jack on J25 would work. I've tried up to 5v/6amp and it was fine.
For further instruction, you can follow this video by JetsonHacks on youtube
Step 2: Getting darknet and running yolov3For this part of the project we decide to darknet which uses yolo V3. YOLOv3 is extremely fast and very accurate. In mAP measured at.5 IOU YOLOv3 is on par with Focal Loss but about 4x faster. Speed and accuracy can be traded off through the size of the model.
This article will guide you through a pre-trained model from yolo which makes the project much more simpler and no training is required. We need to first change
git clone https://github.com/pjreddie/darknet.git
cd darknet
vi MakeileWe first need to change the options in Makefile
GPU=1
CUDNN=1
OPENCV=1After that's done we can do
makeThis would compile the project, after that we need to download the pretrained weight and run the detector, we are using yolov3-tiny
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg ./yolov3-tiny.weights data/dog.jpgNow that this is running, we can move this to webcam
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weightsThis step is a bit complicated, we first need to setup a few things right. First, we need to get opencv 3.4.6, as 4.0+ is having problem with tensowflow, in order to insure that every AI framework works this is the best option. Follow JK Jung's blog on how to get this done is probably he best option, it's located at https://jkjung-avt.github.io/opencv-on-nano/
After installing opencv 3.4.6 we can load darknet. yolov3 is too large for Jetson Nano's memory, however we can implement yolov3-tiny.weight to get this done. Following python code is what essentially making this work. Formatted code can be accessed through code section.
from ctypes import *
import cv2
import sys
sys.path.append('python')
import darknet as dn
import time
import math
import random
def sample(probs):
s = sum(probs)
probs = [a/s for a in probs]
r = random.uniform(0, 1)
for i in range(len(probs)):
r = r - probs[i]
if r <= 0:
return i
return len(probs)-1
def c_array(ctype, values):
arr = (ctype*len(values))()
arr[:] = values
return arr
class BOX(Structure):
_fields_ = [("x", c_float),
("y", c_float),
("w", c_float),
("h", c_float)]
class DETECTION(Structure):
_fields_ = [("bbox", BOX),
("classes", c_int),
("prob", POINTER(c_float)),
("mask", POINTER(c_float)),
("objectness", c_float),
("sort_class", c_int)]
class IMAGE(Structure):
_fields_ = [("w", c_int),
("h", c_int),
("c", c_int),
("data", POINTER(c_float))]
class METADATA(Structure):
_fields_ = [("classes", c_int),
("names", POINTER(c_char_p))]
lib = CDLL("/home/ai/workspace/darknet/libdarknet.so", RTLD_GLOBAL)
lib.network_width.argtypes = [c_void_p]
lib.network_width.restype = c_int
lib.network_height.argtypes = [c_void_p]
lib.network_height.restype = c_int
predict = lib.network_predict
predict.argtypes = [c_void_p, POINTER(c_float)]
predict.restype = POINTER(c_float)
set_gpu = lib.cuda_set_device
set_gpu.argtypes = [c_int]
make_image = lib.make_image
make_image.argtypes = [c_int, c_int, c_int]
make_image.restype = IMAGE
get_network_boxes = lib.get_network_boxes
get_network_boxes.argtypes = [c_void_p, c_int, c_int, c_float, c_float, POINTER(c_int), c_int, POINTER(c_int)]
get_network_boxes.restype = POINTER(DETECTION)
make_network_boxes = lib.make_network_boxes
make_network_boxes.argtypes = [c_void_p]
make_network_boxes.restype = POINTER(DETECTION)
free_detections = lib.free_detections
free_detections.argtypes = [POINTER(DETECTION), c_int]
free_ptrs = lib.free_ptrs
free_ptrs.argtypes = [POINTER(c_void_p), c_int]
network_predict = lib.network_predict
network_predict.argtypes = [c_void_p, POINTER(c_float)]
reset_rnn = lib.reset_rnn
reset_rnn.argtypes = [c_void_p]
load_net = lib.load_network
load_net.argtypes = [c_char_p, c_char_p, c_int]
load_net.restype = c_void_p
do_nms_obj = lib.do_nms_obj
do_nms_obj.argtypes = [POINTER(DETECTION), c_int, c_int, c_float]
do_nms_sort = lib.do_nms_sort
do_nms_sort.argtypes = [POINTER(DETECTION), c_int, c_int, c_float]
free_image = lib.free_image
free_image.argtypes = [IMAGE]
letterbox_image = lib.letterbox_image
letterbox_image.argtypes = [IMAGE, c_int, c_int]
letterbox_image.restype = IMAGE
load_meta = lib.get_metadata
lib.get_metadata.argtypes = [c_char_p]
lib.get_metadata.restype = METADATA
load_image = lib.load_image_color
load_image.argtypes = [c_char_p, c_int, c_int]
load_image.restype = IMAGE
rgbgr_image = lib.rgbgr_image
rgbgr_image.argtypes = [IMAGE]
predict_image = lib.network_predict_image
predict_image.argtypes = [c_void_p, IMAGE]
predict_image.restype = POINTER(c_float)
def array_to_image(arr):
arr = arr.transpose(2,0,1)
c = arr.shape[0]
h = arr.shape[1]
w = arr.shape[2]
arr = (arr/255.0).flatten()
data = dn.c_array(dn.c_float, arr)
im = dn.IMAGE(w,h,c,data)
return im
def detect(net, meta, image, thresh=.24, hier_thresh=.5, nms=.45):
im = load_image(image, 0, 0)
num = c_int(0)
pnum = pointer(num)
predict_image(net, im)
dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, None, 0, pnum)
num = pnum[0]
if (nms): do_nms_obj(dets, num, meta.classes, nms);
res = []
for j in range(num):
for i in range(meta.classes):
if dets[j].prob[i] > 0:
b = dets[j].bbox
res.append((meta.names[i], dets[j].prob[i], (b.x, b.y, b.w, b.h)))
res = sorted(res, key=lambda x: -x[1])
free_image(im)
free_detections(dets, num)
return res
def isFall(w,h):
if float(w)/h>=1.1:
return True
else:
return False
#open the input video file
cap=cv2.VideoCapture(0)
# load network and weights
net = dn.load_net("cfg/yolov3-tiny.cfg", "yolov3-tiny.weights", 0)
meta = dn.load_meta("cfg/coco.data")
res=[]
frame_number=0
while True:
# Grab a single frame of video
ret, frame = cap.read()
frame_number += 1
# Quit when the input video file ends
if not ret:
break
'''
# detect per 2 frame
if frame_number%2==0:
continue
'''
# append all the coordinate of the detected person to res
# im = array_to_image(frame)
start=time.time()
cv2.imshow('Fall detection',frame)
cv2.imwrite('check.jpg',frame)
r = detect(net, meta, 'check.jpg')
#print('the whole running time is: '+str(time.time()-start))
res=[]
for item in r:
if item[0]=='person' or item[0]=='dog' or item[0]=='cat' or item[0]=='horse':
res.append(item)
# if multiple exist, and there also contains person, preserve person only!
#print('--------------')
#print(res)
if len(res)>1:
for item in res:
if item[0]=='person':
res=[]
res.append(item)
break
# get the max rectangle
result=[]
maxArea=0
if len(res)>1:
for item in res:
if item[2][2]*item[2][3]>maxArea:
maxArea=item[2][2]*item[2][3]
result=item
elif len(res)==1:
result=res[0]
#draw the result
if(len(result)>0):
print(result)
# label the result
left=int(result[2][0]-result[2][2]/2)
top=int(result[2][1]-result[2][3]/2)
right=int(result[2][0]+result[2][2]/2)
bottom=int(result[2][1]+result[2][3]/2)
#whether fall?
if isFall(result[2][2],result[2][3]):
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# Draw a label with a name below the face
cv2.rectangle(frame, (left, bottom - 25), (right, bottom), (0, 0, 255))
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, 'Warning!!!', (left + 6, bottom - 6), font, 0.5, (255, 0, 0), 1)
else:
cv2.rectangle(frame, (left, top), (right, bottom), (255, 0, 0), 2)
cv2.imshow('Fall detection',frame)
# Hit 'q' on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# All done!
cap.release()
cv2.destroyAllWindows()Upon running the code we should be able to see the fall detection live with our camera.
Now that we can detect falling, we can easily send a SMS to user's phone, we will first have to install
Through installing twilio we may run into trouble on getting some libraries to work, which we will have to get it through on Jetson-Nano, first we have to install openssl on aarch64
sudo apt-get install build-essential libssl-dev libffi-dev python-dev
pip install cryptographyAfter that we can install
sudo pip install twilioAfter that's installed we can do twilio for easy intergration.
import twilio
from twilio.rest import Client
account_sid = 'yourid'
auth_token = 'yourauth'
client = Client(account_sid, auth_token)
message = client.messages.create(
from_='+1{your_twilio_number}',
body='Warning from Guardian Camera AI, Peter has fell, please contact him to make sure he is ok',
to='+1{yourphone}'
)
print(message.sid)Now that everything is built, we can see the demo :)
One more thingThe cameras is installed through living quarters and public places, but there are also places where cameras do not catch. Additional wearables such as Senior Guardian Frame glasses can be used in combination to detect falls, which adds more safety features for senior citizens. The wearable glass is documented at https://www.hackster.io/Nyceane/senior-guardian-frame-018843







{kind=link}
Comments