


Hardware components | ||||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
| ||||||
The project underlines the process using Intel® Distribution of OpenVINO™ Toolkit to use Deep Learning inference to recognize new Drugs. The project uses an Algorithm for simple identification or classification of Drug Structure using web app.
Figure 1: Overview of the Model
This article examines how the solution is built using deep learning and computer vision algorithms powered by the Intel® Distribution of OpenVINO™ toolkit Model Optimizer.
Use Case for the Application· Early drug discovery is an essential part of the pharmaceutical sector.
The entire Drug discovery process during Clinical Trials takes a lot of time because there are multiple phases of testing namely Phase 1, Phase 2, and Phase 3 trials. Most of the time drugs compound fails to test at Phase 2 and Phase 3. The traditional process involves basic research to uncover targets that may be susceptible to attack, such as a disease-related protein receptor on the surface of particular cells. Then, scientists use techniques like high-throughput screening to see which compounds bind the target. After that, various methods of biological and chemical testing are used to fine-tune the structure or test other features, such as a compound’s ability to reach the target in an organism.
The starting target is very essential in terms of drug discovery so Scientists and Biologists believe that utilizing Machine Learning techniques will help streamline the process into more rigorous testing. Using advanced computational tools and simulations to create new molecules as well as faster processing and AI will help us generate more medicines and also allow better medicines to come in.
This methodology will help us to identify the new drugs and virtual molecules in terms of Drug discovery. The goal is to generate virtual molecules on demand and identify and classify them accordingly.
What we are trying to findWe are using Deep Learning, Computer Vision, and AI methods to classify and identify virtual molecules which helps us to make a decision and reduce the time for unnecessary walk-through for the entire clinical trial process as described above.
The process relates to the method for scientific experimentation especially used in drug discovery and relevant to the fields of biology and chemistry. Using robotics, data processing/control software, liquid handling devices, and sensitive detectors, high-throughput screening allows a researcher to quickly conduct millions of chemical, genetic, or pharmacological tests. Through this process, one can rapidly identify active compounds, antibodies, or genes that modulate a particular biomolecular pathway. The results of these experiments provide starting points for drug design and for understanding the non-interaction or role of a particular location.
Which Drugs to Start with and Why?Now that we are clear on what we want to achieve, the next thing would be to make a decision on which drugs to start with. We started with some common occurrences of diseases and started with drugs that cure and assist in certain places. We zeroed it down to three common diseases one with common bacterial infection and the drug that helps in curing it is Cyclacillin which is a cyclohexylamido analog of penicillanic acid. It is used for the treatment of bacterial infections caused by susceptible organisms.
The next drug on which we focused is used for treating Asthma. According to WHO some 235 million people currently suffer from asthma. And it’s most common in children. Appropriate management of asthma can enable people to enjoy a good quality of life. That’s why focusing on such drugs is of real importance.
The common drug was Salbutamol. Salbutamol is a short-acting, selective beta2-adrenergic receptor agonist used in the treatment of asthma and COPD.
Our third drug is Levobupivacaine which is used for local anesthesia including infiltration, nerve blocking, ophthalmic, epidural, and intrathecal anesthesia in adults; and infiltration analgesia in children.
1. Salbutamol (Used For: Treating Common Bacterial infection)
2. Cyclacillin (Used For Treating Asthma)
3. Levobupivacaine (Used For Analgesia for Surgery)
Overview and ArchitectureAs illustrated above, the primary objective of the project is to identify drugs, given their molecular structure correctly and with the utmost precision. The output of the model is the correctly identified name of the drug along with the degree of confidence/accuracy. The input can be an image, video, or live camera feed of the molecular structure of the drug
When training a robust classifier, the training images should have random objects in the image along with the desired objects, as well as a variety of backgrounds and lighting conditions. In some images, the desired object should be partially obscured, overlapped with something else, or only halfway in the picture. This article uses the package icrawler, which is provided by pypi. For details, go to icrawler pypi.
To install icrawler, run the following command on the Anaconda* prompt:
pip install icrawler
Next, import the icrawler package and write a small snippet of code in Python to fetch the images from Google*.
The command shown below uses a keyword for the web crawler to gather all the results from Google Images* search service and saves them in .jpeg format on the disk. Provide the number of desired images as an input to the code.
from icrawler.builtin import GoogleImageCrawler
for keyword in ['Hibiscus rosa-sinensis', Marigold]:
google_crawler = GoogleImageCrawler(parser_threads=2,
downloader_threads=4,storage={'root_dir':
'images_new/{}'.format(keyword)})google_crawler.crawl(
keyword=keyword, max_num=300, min_size=(200, 200))Make sure the images are each less than 200KB, and their resolution does not exceed 720x1280. The larger the images, the longer it will take to train the classifier. Use a Python script to reduce the size of the images.
Label PicturesHere’s the fun part: labeling the desired objects in every picture. LabelImg is a useful tool for this purpose; its GitHub* page has clear instructions on how to install and use it.
1. LabelImg GitHub Documentation
Point LabelImg to your \images\train directory, and then draw a box around the object in each image. Repeat the process for all the images in the \images\test directory. This process will take a while!
LabelImg saves an .xml file containing the label data for each image. These .xml files will be used to generate TensorFlow records, which are among the inputs to the TensorFlow trainer. As each image is labeled and saved, there will be one .xml file for each image in the \test and \train directories.
Here are 400 images for each class of drug, split for training and testing.
Capture Frames for ProcessingFor any application that involves the use of image, video, or live camera feed, it is necessary to capture the frames. This process is easy and straightforward to do using OpenCV. Once the frames are captured, iterate through each frame, and pass it through the recognition engine for detection.
To provide an image as an input to the model, use the code described below:
import cv2
IMAGE_NAME = 'test1.jpg'
# Grab path to current working directory
CWD_P # Path to image
PATH_TO_IMAGE = os.path.join(CWD_PATH,IMAGE_NAME)ATH = os.getcwd()
image = cv2.imread(PATH_TO_IMAGE)
image_expanded = np.expand_dims(image, axis=0)To provide videos as an input to the model, use the following code:
import cv2
# Initialize webcam feed
video = cv2.VideoCapture(0)
ret = video.set(3,1280)
ret = video.set(4,720)The above piece of code captures the video frames. The third line is the one that must be inside a loop as it captures frames.
The above piece of code captures the video frames. The third line is the one that must be inside a loop as it captures frames.
Drugs Identification Using TensorFlow ClassifierFirst, include all the required packages:
# Import packagesimport os
import cv2
import numpy as np
import tensorflow as tf
import sys# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")# Import utilites
from utils import label_map_util
from utils import visualization_utils as vis_util# Name of the directory containing the object detection module we're usingMODEL_NAME = 'inference_graph'# Grab path to current working directory
CWD_PATH = os.getcwd()# Path to frozen detection graph. pb file, which contains the model that is used for object detection.PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,'frozen_inference_graph.pb')# Path to label map filePATH_TO_LABELS = os.path.join(CWD_PATH,'training','labelmap.pbtxt')Include in the classifier code how many classes of pathological diseases to recognize. For this experimental research purpose, we are targeting three drugs: Salbutamol ,Cyclacillin and Levobupivacaine.
# Number of classes the object detector can identify
NUM_CLASSES = 3Next, load the TensorFlow model:
# Load the Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')sess = tf.Session(graph=detection_graph)# Define input and output tensors (i.e. data) for the object detection classifier# Input tensor is the image
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')# Output tensors are the detection boxes, scores, and classes
# Each box represents a part of the image where a particular object was detecteddetection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')# Each score represents level of confidence for each of the objects.
# The score is shown on the result image, together with the class label.detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')# Number of objects detected
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
Load the input and view the output window initiated by the model:
# Initialize webcam feed
video = cv2.VideoCapture(0)
ret = video.set(3,1280)
ret = video.set(4,720)while (True):
# Acquire frame and expand frame dimensions to have shape: [1, None, None, 3]
# i.e. a single-column array, where each item in the column has the pixel RGB value
ret, frame = video.read()
frame_expanded = np.expand_dims(frame, axis=0)
# Perform the actual detection by running the model with the image as input
(boxes, scores, classes, num) = sess.run([detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict= {image_tensor: frame_expanded})# Draw the results of the detection (aka 'visulaize the results')
vis_util.visualize_boxes_and_labels_on_image_array(
frame,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.60)
# All the results have been drawn on the frame, so it's time to display it.
cv2.imshow(Drug Discovery, frame)
# Press 'q' to quit
if cv2.waitKey(1) == ord('q'):
break
# Clean up
video.release()
cv2.destroyAllWindows()Now that training is complete, the last step is to generate the frozen inference graph (. pb file) which creates a frozen_inference_graph.pb file in the \object_detection\inference_graph folder. The. pb file contains the object detection classifier.
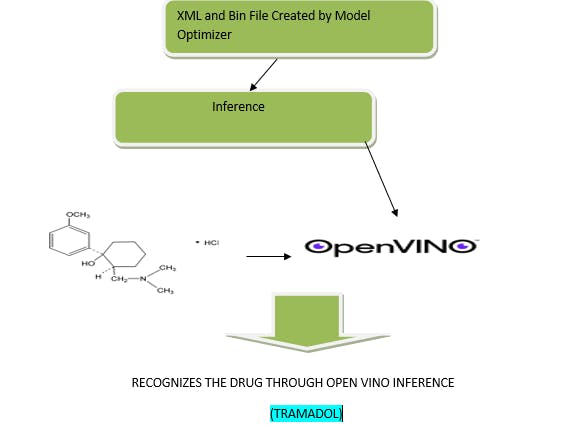
The next focus is on using the Intel® Distribution of OpenVINO™ toolkit to run interfaces. The classifier algorithm helps to identify the drug correctly. First, optimize the model to create an *.xml and *.bin file.
Use the mo.py script from the <INSTALL_DIR>/deployment_tools/model_optimizer directory to run the model optimizer and convert the model to the intermediate representation (IR).
Note: Some models require using additional arguments to specify conversion parameters, such as — scale, — scale_values, — mean_values, — mean_file. To learn when to use these parameters, refer to Converting a Model Using General Conversion Parameters.
The mo.py script is the universal entry point that can deduce the framework that has produced the input model by a standard extension of the model file:
· .caffemodel — Caffe* models
· .pb — TensorFlow* models
· .params — MXNet* models
· .onnx — ONNX* models
· .nnet — Kaldi* models.
Since the model is built on TensorFlow and the frozen inference graph is already generated (. pb file) as mentioned previously, use that particular file and run the mo.py script.
This approach uses a model optimizer to fine-tune the model for a user application to consume. The .xml and .bin files generated from the model optimizer are consumed by the inference engine using the Python API, which is essentially a wrapper built on top of C++ core codes.
Characteristics and Architectural Details:1. Architecture: The model is having two variants, one built in Faster RCNN and the other in SSD Mobile net (ssd_mobilenet_v2_coco). Final one is on the SSD Mobile net, as SSD Mobile net model is well supported by both Intel® Distribution of OpenVINO™ Toolkit and TensorFlow Lite.
2. Back-end Framework: Intel® Optimization for TensorFlow*
3. OpenCV for the Computer Vision Algorithm building.
4. Dataset: High Quality Images taken from Google Images using Web Crawling. This is one of the bottleneck’s I am facing. Since going into the fields and clicking images is one of the most tedious and time-consuming approach that’s why I went for the images available on the internet. But, for my present approach I need high quality and a huge amount of data, as the classes are increasing. I will gather the images and create my own Dataset. In future that can be open sourced so that people can use that.
5. Log Loss: I am able to drop down the log loss up-to 0.0135 at a step count of 42,916 after 18 hours of training. In terms of accuracy, as the inference shows that it ranges between 85–90%, depending upon the image or image that has been provided for the inference.
6. Model Optimization and Inference on hardware running Intel® architecture is being carried out by Intel® Distribution of OpenVINO™ Toolkit.
Sample Images from the Test InferenceObserve how the model has successfully identified the different classes of drugs:
· Salbutamol
The above image from the test run shows that the model successfully identifies the drug Salbutamol given the molecular structure as input. It creates a bounding box and displays the name of the drug along with the accuracy in percentage. The above drug is Salbutamol and is correctly identified by the model. It also shows the accuracy of detection in percentage; in this case, the recognition accuracy is 89%.
· Cyclacillin
As shown in the above image, the model identifies the other class of drug correctly and accurately as well. The above drug is Cyclacillin, it is widely used for treatment of bacterial infections caused by susceptible organisms. It is correctly identified by the model as shown on the above image. The accuracy of this test case is 88%.
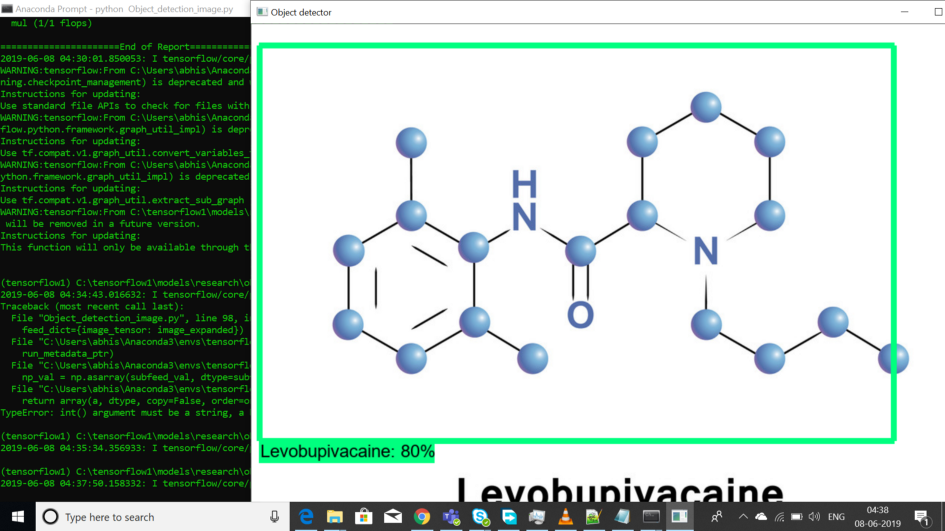
· Levobupivacaine:
As shown in the above image, the model identifies the third drug correctly and accurately as well. The above structure resembles the drug Levobupivacaine. It is a local or regional anesthesia or analgesia for surgery, for oral surgery procedures, for diagnostic and therapeutic procedures, and for obstetrical procedures. It is correctly identified by the model as shown on the above image. The accuracy of this test case is again 80%.
ConclusionIdentifying drugs is a no easy task when we are taking molecular structures as the only feature. These molecular structures are very closely resembled and looks very similar to each other. Thus, extracting features and separating them into different classes is quite difficult for a computer. Our model is successful in doing this hard task.
The above illustrates the importance of drug identification and drug discovery in the modern world healthcare and pharmaceutical practice and how this solution shows accurate results in identifying the drugs correctly, given the molecular structures. The model gives a good use case of deep learning and computer vision; introducing a computer vision recipe using the model optimizer and inference engine of the Intel® Distribution of OpenVINO™ toolkit. Model Optimization helps us in getting good frames per second (FPS) while doing inference on live video feed.
Additional Resources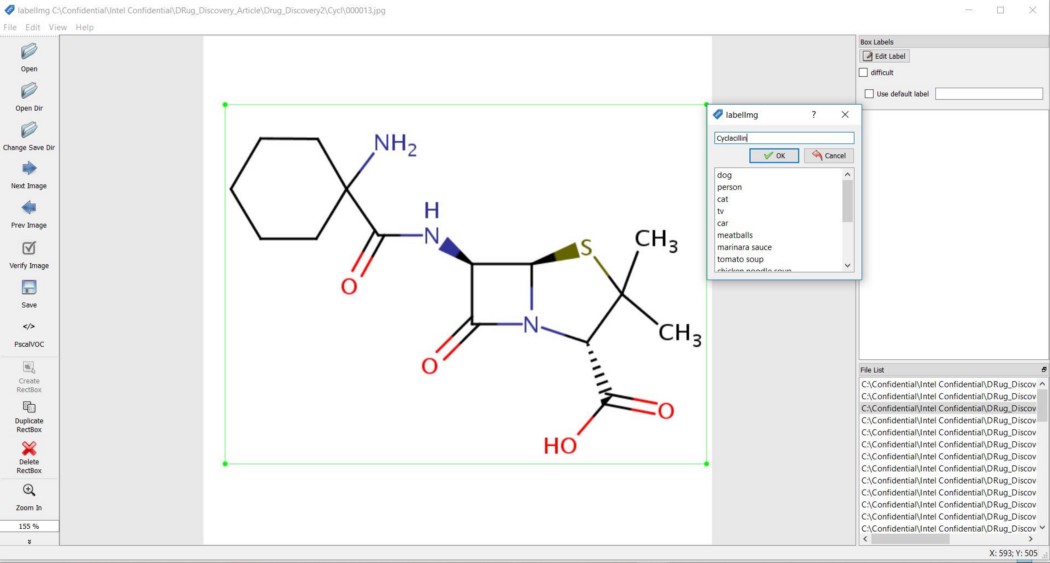
{kind=link}
{kind=link}


Comments
Please log in or sign up to comment.