



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
In this article, we will introduce the Reinforcement Learning Coach and see how it is utilized as a framework for implementing Reinforcement Learning scenarios. Finally, we will look at a mechanism through which we connect Reinforcement Learning Coach with theOpenVINO toolkit. The main application of using theOpenVINO toolkit is to optimize the models created during the Reinforcement Learning training process. After doing the optimization process we, in turn, will use inference engine to render the application on different Intel targeted systems so that we can visualize the entire trained simulation. We will see how different parameters are used in Reinforcement Learning Coach.
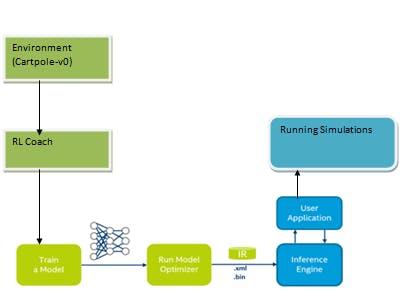
The next figure shows the entire process.
Intel Distribution of OpenVINO Toolkit utilization
1) Generate the *.xml and *.bin file (IR) from Model Optimizer of OpenVINO Toolkit.
2) Intel OpenVINO helps us first to create the required *.xml and *.bin from the checkpoint files saved while training in Reinforcement Learning Coach.Next using the inference engine from OpenVINO toolkit we are able to focus on the last simulation reached at most acceptable simulation(We are capturing gifs of multiple checkpoints as the Reinforcement Learning Coach does the training,as we can tell from the time spent at training that the last step it performed was the accepted one we can show this part as the stable part of our simulation performed)for Cartpole environment for stability and showcase that part of simulation.
System Requirement
1) Ubuntu 16.04
2)16 GB ram
3) 4th Generation Intel processors and beyond.
Running experiments on RL CoachEverything we do in Reinforcement Learning Coach is using some experiment or other.
One of the most important parts of running the experiment is using a pre-set mechanism.
The preset uses a predefined experiment parameter.
Preset allows us to make the interaction between agents and the environment much easier and with a process to apply different parameters to make the job easier for us.
Reinforcement Learning coach is very easy to use from the terminal window.The steps, as we will see are very easy to understand and follow along.
i.e.
coach –pNow after that, we need to pass in the environment in which we would be implementing the coach framework.The environments mentioned are nothing but simulations that be trained using different values of the coach.
For environments, we will look at Atari as well as Cartpole environments.
installation of Reinforcement learning Coach
For the walkthrough, we need the same version of python that is 3.5 and Tensorflow 1.11 as I did.It is mentioned in the documentation too that we need to have Python 3.5 installed using Ubuntu 16.04 and with a lot of trials and experiments I found that Tensorflow 1.11 is the supported one.
First of all, we need to have only Python 3.5 installed.
One more essential part
We will have to install the exact version TensorFlow installed nothing more or less than that. The version is 1.11.0
First of all install anaconda client for Ubuntu 16.04
Installation of Anaconda IDEWe can use curl to download the version of the Anaconda ide.
curl -O https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh
After that, we need to run the script
bash Anaconda3–5.0.1-Linux-x86_64.sh
We will hit ENTER to continue.
We will have to approve the license term to yes.
Then a prompt will come we will hit enter to accept the installation in the default location.
Next, it will ask to add code to the path we need to click on yes.
Creation of Anaconda Python 3.5 environmentIn the next step, we will install python 3.5 in an Anaconda environment.
conda create -n py35 python=3.5 anacondaAfter a successful installation, we need to activate the environment.
source activate py35The major part of the installation and the pre-requisites are defined and shown stepwise in the Reinforcement Learning Coach link.You can have a look,I am sharing the link below.
https://github.com/NervanaSystems/coach#installation
Tweaking the requirements.txt file.
On tweak, we need to make in the requirements.txt file the dependency for TensorFlow needs to be set up as
TensorFlow == 1.11.0
Then we will run pip3 install –r requirements.txt
This updated txt file will take care of the dependency and install the required version of TensorFlow that is 1.11.0
Note:-
To install Coach 0.11.0 we should have
Python 3.5
TensorFlow 1.11.0
Now we will use the following command inside the cloned folder that is “coach”.
pip3 install -e .This will install Coach.
After installation Coach we will check the presets available the command to check it is
coach –lLet us look at some example environments for simulations that we will be working on.
Cartpole –v0Cartpole — known also as an Inverted Pendulum is a pendulum with a center of gravity above its pivot point. It’s unstable, but can be controlled by moving the pivot point under the center of mass. The goal is to keep the cart pole balanced by applying appropriate forces to a pivot point.
The Cartpole environment scenario for RL Coach
A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart. The pendulum starts upright, and the goal is to prevent it from falling over. A reward of +1 is provided for every time step that the pole remains upright. The episode ends when the pole is more than 15 degrees from the vertical, or the cart moves more than 2.4 units from the center.
More details can be found below
https://gym.openai.com/envs/CartPole-v0/
using deep reinforcement learning, we implement a system that could learn to play many classic Atari games with human (and sometimes superhuman) performance.
More details can be found here in the link below.
https://gym.openai.com/envs/Breakout-v0/
using coach -l shows us all the presets available in RL Coach
Now we will look at the open vino toolkit. The major thing that needs to be covered is how the TensorFlow checkpoint file is accessed in the open vino toolkit. The model optimizer does the job for us with the TensorFlow framework. Let’s look at it now.
First of all, we need to install the pre-requisites for TensorFlow.
Within the folder
<INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisitesWe need to run the shell script.
install_prerequisites_tf.shAs we will be saving the file in *.meta format we have to follow the following procedure.
In this case, a model consists of three or four files stored in the same directory:
model_name.meta
model_name.index
model_name.data-00000-of-00001 (digit part may vary)checkpoint (optional)To convert such TensorFlow model:
Go to the <INSTALL_DIR>/deployment_tools/model_optimizer directory
Run the mo_tf.py script with a path to the MetaGraph .meta file to convert a model:
We have just shown the process it will implement when we create the checkpoint.
Let’s go back to the coach environment again.
To run a preset we will have to use
coach -r -p <preset_name>The parameter –r is used for rendering the scene while training.
The most important command that we need in order to integrate theReinforcement Learning coach with OpenVINO is to use it to save thetraining process after a definitive time interval which saves checkpoints for the undergoing training.
coach –s 60“using –s”
Checkpoint_save_secs
This allows coach to save checkpoints for the model.We can also specify the time.This is indeed important because we know coach uses the TensorFlow backend. These checkpoint files are directly referenced in the open vino toolkit as we can create an optimized model from it.
FoldersThere is a specific way how the training process is being saved on for any matter in our local PC when we run the coach. Everything that happens with the coach training and time interval save process is saved in theExperiments folder.
Reinforcement Learning Coach training process with an environmentIn this section, we will start a training process with Reinforcement Learning Coach and save the checkpoint for utilization for the Model Optimizer. The training environment used here is Breakout.
Let us start the training process for the Reinforcement Learning coach on Atari game with level as a breakout.
(py35) abhi@abhi-HP-Pavilion-Notebook:~$ coach -r -p Atari_NEC -lvl breakout -s 60
Please enter an experiment name: Atari_NEC
Creating graph — name: BasicRLGraphManager
Creating agent — name: agent
WARNING:tensorflow:From /home/abhi/anaconda3/envs/py35/lib/python3.5/site-packages/rl_coach/architectures/tensorflow_components/heads/dnd_q_head.py:76: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims insteadsimple_rl_graph: Starting heatupHeatup — Name: main_level/agent Worker: 0 Episode: 1 Total reward: 1.0 Exploration: 0.1 Steps: 52 Training iteration: 0Heatup — Name: main_level/agent Worker: 0 Episode: 2 Total reward: 0.0 Exploration: 0.1 Steps: 76 Training iteration: 0Heatup — Name: main_level/agent Worker: 0 Episode: 3 Total reward: 0.0 Exploration: 0.1 Steps: 98 Training iteration: 0We save the model periodically after 60 steps
We will now see how we used the OpenVINO Toolkit. The saved model is accessed through the OpenVINO toolkit.
(py35) abhi@abhi-HP-Pavilion-
Notebook:/opt/intel/computer_vision_sdk_2018.4.420/deployment_tools/model_optimizer$ python mo_tf.py — input_meta_graph ~/experiments/Atari_NEC/17_01_2019–03_29/checkpoint/0_Step-605.ckpt.meta
Model Optimizer arguments:
Common parameters:- Path to the Input Model: None
- Path for generated IR: /opt/intel/computer_vision_sdk_2018.4.420/deployment_tools/model_optimizer/.- IR output name: 0_Step-605.ckpt- Log level: SUCCESS
- Batch: Not specified, inherited from the model- Input layers: Not specified, inherited from the model- Output layers: Not specified, inherited from the model- Input shapes: Not specified, inherited from the model- Mean values: Not specified- Scale values: Not specified- Scale factor: Not specified- Precision of IR: FP32- Enable fusing: True- Enable grouped convolutions fusing: True- Move mean values to preprocess section: False- Reverse input channels: FalseTensorFlow specific parameters:- Input model in text protobuf format: False- Offload unsupported operations: False- Path to model dump for TensorBoard: None- List of shared libraries with TensorFlow custom layers implementation: None- Update the configuration file with input/output node names: None- Use configuration file used to generate the model with Object Detection API: None- Operations to offload: None- Patterns to offload: None- Use the config file: NoneModel Optimizer version: 1.4.292.6ef7232dAn XML and a bin are generated by a model optimizer that can be used for inference for a later time.
Inferring using our modelAs we have generated the XML and the bin for final inference we have to share them with parameter –m the path to the XML bin file generated as well as using the Algorithm for the Reinforcement learning approach using –i option so that we can run the simulation with best-performing checkpoints from the Reinforcement Learning coach that is generated with build target setup for CPU.
./rl_coach -m <xmlbin path> -i <algorithm> -d CPU
./rl_coach -m <xmlbin path> -i <algorithm> -d CPU
As we run the inference we will be able to pull up the best possible result for balancing for Cartpole or the breakout game.We are saving a gif for each result that we get so in this case the best result of all the gifs file is shown.
The Cartpole balancing act before and after the training process after inference being implemented.
The gifs below show the progress before training and after training.
After Training
In the first part of the article, we have seen how Reinforcement Learning Coach works
We have touched on the installation process and pre-requisites
With principles related to Reinforcement Learning, we have touched on different experiment scenarios.
The experiment scenarios that we have used for simulation are the Cartpole
Using Reinforcement Learning Coach we found an acceptable model for the simulation process and the checkpoint.
These checkpoint optimal results were in turn converted to intermediate reference (IR) using Intel Distribution of OpenVINO toolkit Optimization process.
Using the inference engine we generated the visualization for the best-optimized simulation.
We have used OpenVINO Toolkit with Reinforcement Learning Coach to show the simulation for the experiment.
The article gives us the scope to work on adifferent experiments with Reinforcement Learning Coach and generate different optimized simulations for it.
{kind=link}


Comments
Please log in or sign up to comment.