



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
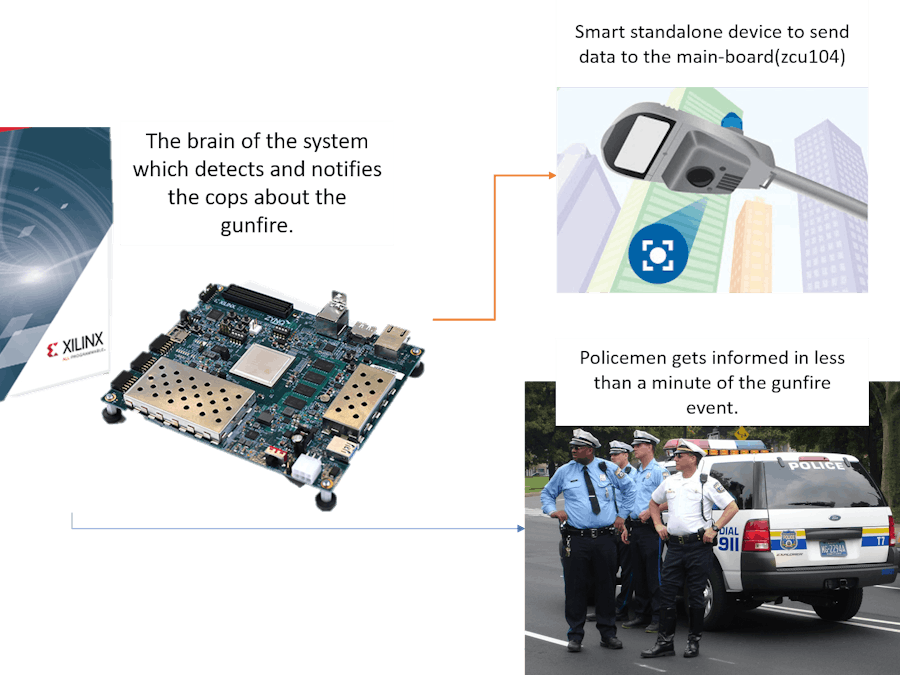
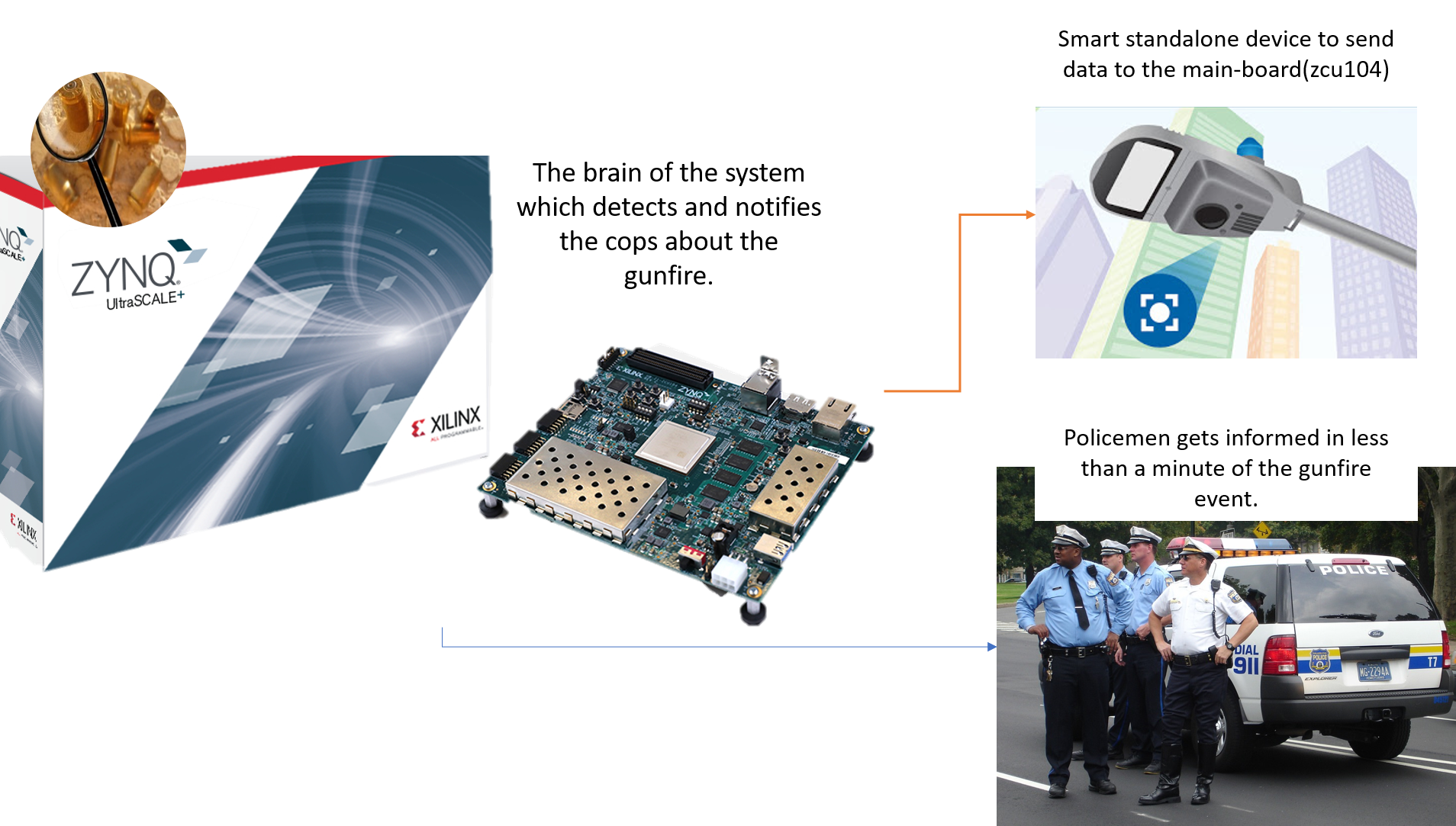
This project demonstrates how to build a device using the Xilinx ZCU104 development kit to solve most of the problems faced by government authorities like Police, Ambulance Services, etc. The device uses Machine Learning algorithms to check for the gunfire and notifies it to the authorities with precise information like the number of times the gun was fired, which gun was used for firing, location, direction, and the frames captured from the camera. The project also demonstrates how we can provide more insights into the community, locality to these authorities just by collecting and utilizing the data got from our device. I got inspiration from news, articles like school shootings, gunfire in public, gun injuries account for $2.8 billion in the emergency room and hospital charges in the United States each year, so I found a call within me as an active member of this innovative, committed community.
After experiencing the threat of a school shooting, as well as the changes in the school via countermeasures, students continue to experience the trauma. In several peer‐reviewed articles on mental health consequences of school shootings by Lowe & Galea, it is shown that mass shootings can bring on the onset of PTSD and continued depression. In the cities that are home to these kinds of events, the town can experience continued paranoia and an exaggerated sense of fear. Lowe & Galea continue to say that continued research is necessary to pinpoint the exact mental symptoms that occur in the victims of school shootings.
On average only 20% of gunfire incidents are reported to the police. This means police are working with an 80% deficit in intelligence as it relates to gun violence and are unable to respond to the majority of shootings. Even when gunfire is reported to police, there are several minute delays in getting information to the police. Also, the reported location of the gunfire is often vague or inaccurate due to limitations in human hearing. The result is that critical time is lost getting the police to the actual crime scene. Moreover, teenagers are at higher risk.
Problems due to late reporting of gunshots
- Police and other government authorities have less opportunity to arrive at the scene quickly to identify suspects and witnesses or render lifesaving aid it even makes it extremely limited.
- For community members who live where gunfire occurs, the lack of a precise and consistent response from police can fuel a negative perception of law enforcement, and a belief that they don’t care.
- Persistent gunfire in a community carries a heavy social, psychological, and economic toll.
The important measure taken while making this project was collecting data efficiently and patiently, once the data is collected the job becomes a lot easier (You are bound to fail if you don't collect correct data to feed your hungry ML frameworks). For the data collection part, I used the gunfire audio from shooting games (like CS and Valorant).
The backbone of this project is that you need to tune your device after every stage. So let's get started, enjoy learning with Machine Learning.
Technical Overview:Gun violence is an urgent, complex, and multifaceted problem. It requires evidence-based, multifaceted solutions. Over 13,000 people are murdered with a gun every year in the United States. The majority of these shootings take place in cities, where violence is further concentrated spatially, racially, and within groups, gangs, or cliques.
Theme: Intelligent Video Analytics
1) City Surveillance:
"I want other people to know that no one is exempt from gun violence. It can happen to anyone at any time. No place is truly safe. Even if you do all the right things—if your son does all the right things—it still might not be enough." - Pam Bosley
With the increase in the rate of gun availability 24/7 surveillance system is needed so that the police and other officials can arrive at the spot to control the situation. Moreover, an advanced surveillance system can even help in forensics and contribute to justice. Previously police would receive the information about the gunshot from the people at the spot or if anyone finds a shot body. Now, we can use machine learning to detect the gunshot within seconds and inform the police in less than a minute. This step will control gun violence and make the local masses more loyal toward government officials. Using the correct analysis the machine would auto-suggest the police when and how much weapon is to be needed at the spot, and thus can save resources, efforts and will lead to a less panic situation in the society.
You can check this website for more problems faced by my local masses because of gun violence.
https://www.americanprogress.org/issues/guns-crime/reports/2018/05/04/450343/americas-youth-fire/
https://en.wikipedia.org/wiki/Gun_violence_in_the_United_States
2) Determining the direction and distance of the sound source.
To address the problem, I investigated the potential benefits of adding a microphone array to the system, which consists of multiple microphones that can simultaneously capture audio. As the audio is captured, digital signal processing (DSP) algorithms can be applied to cancel out echoes, determine the direction of individual sound sources, reduce background noise, etc. These are providing a much-needed boost to the performance of voice-enabled devices.
Check these links for further details:
https://medium.com/kkbankol-events/raspberry-pi-15662c3ca881
https://www.hindawi.com/journals/js/2017/6782176/
We can even make the device more smart and precise with different techniques like delocalization of audio signals.
3) Audio classification for Gunshot Detection.
We will prepare the dataset of a gunshot sound with specific labels namely rifles, SMG, pistol, revolver. We can even access more information from the data like the number of bullets fired and the type of gun. We are purposely using video and audio files from games like Valorant as there is less noise and moreover is easily available for a game lover like me.
4) Image Classification for gun detection and 3D reconstruction for knowing the exact location of the firing point.
We can use different cameras and sensors to get the exact location of the culprit and would help for the forensics and also to trace back the exact cause for the open firing.
Let's see our audio data and try to understand the variations so that we can train our model.
import librosa
from scipy.io import wavfile as wav
import numpy as np
filename = 'smg0.wav'
librosa_audio, librosa_sample_rate = librosa.load(filename)
scipy_sample_rate, scipy_audio = wav.read(filename)
print('Original sample rate:', scipy_sample_rate)
print('Librosa sample rate:', librosa_sample_rate)#plt
import matplotlib.pyplot as plt
# Original audio with 2 channels
plt.figure(figsize=(12, 4))
plt.plot(scipy_audio)Some more code snippets can be seen in the images attached.
The full code is attached at the end. And I have used the game video for this project so a similar video is to be needed for the input. We can even tune the model with a much better dataset of real guns and real environments like crowded places and many more.
Let's see our image dataset and train our model.
How can the idea be revenue-generating? Why Xilinx FPGA is better for this project?Since, a similar idea is being used in 20 cities by ShotSpotter, Inc and the idea has resulted in a decrease in the rate of homicide by 75%. The company is almost generating approximately $45 million.
NEWARK, Calif., Nov. 09, 2020 (GLOBE NEWSWIRE) -- ShotSpotter, Inc. (NASDAQ: SSTI), the leader in acoustic gunshot detection and precision policing solutions that help law enforcement officials and security personnel prevent and reduce gun violence, reported financial results for the third quarter ended September 30, 2020.
- Revenues increased 14% to $11.4 million from $10.0 million for the third quarter of 2019.
- Gross profit increased 8% to $6.4 million (57% of revenues) from $6.0 million (60% of revenues) for the third quarter of 2019.
- Net income increased 27% to $566,000 from $446,000 for the third quarter of 2019.
- Adjusted EBITDA1 increased 44% to $3.3 million from $2.3 million for the third quarter of 2019.
- Realized 3 new “go-live” square miles of coverage and 6 square miles of attrition during the quarter, bringing the total live miles to 758 at the end of the quarter.
- Maintained a strong balance sheet with $28.7 million in cash and cash equivalents at the end of the quarter, and $20 million available on its line of credit.
- Subsequent to quarter-end, signed a definitive agreement to acquire LEEDS, LLC, a leading investigative case management software provider, with the transaction expected to close in November 2020. Upfront consideration of $17.0 million includes $15.0 million in cash and $2.0 million in ShotSpotter common stock, plus a potential earnout of $5.0 million over the next two years.
Full-year 2020 revenue guidance narrowed and slightly increased to a range of $44.5 million to $45.0 million, representing 10% growth at the midpoint compared to full-year 2019. The company’s revenue guidance for full-year 2020 excludes any contribution from LEEDS, LLC.
FPGA is a better option because of the following reasons:
- Latency: How long does it take to compute something?
FPGAs are good at this. - Connectivity: What input/output can we connect and with which bandwidth?
FPGAs can directly be connected to inputs and can offer very high bandwidth. - Engineering cost: How much effort does it cost to express the computation?
The engineering cost is typically much higher than for instruction based architectures, so the advantages must really be worth it. - Energy efficiency: How much energy does it cost to compute something?
This is often listed as a large benefit of FPGA.

{kind=link}

Comments
Please log in or sign up to comment.