
Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
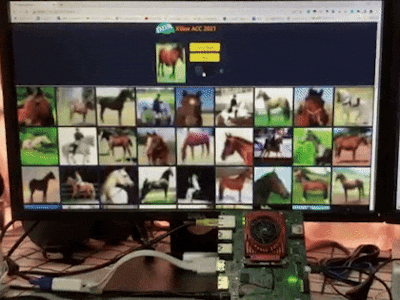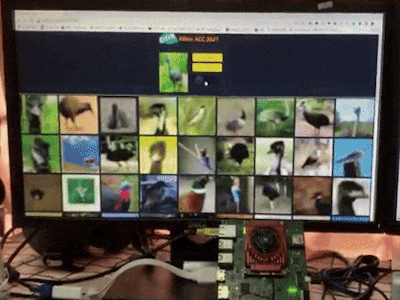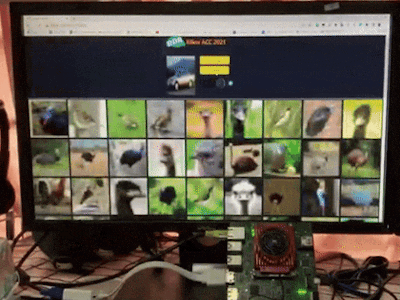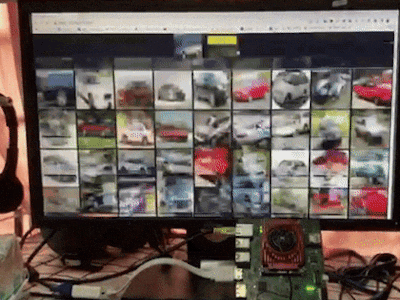
Search by image aims at finding objects in a collection that are close to a given query image according to high dimensional features. It has been widely adopted in search engines like Google and Taobao as well as recommendation systems to help people do more with what they see in daily life. For example, people can easily find items in an outfit they like, learn more about landmarks, buy what they see, and identify that cute dog in the park.
As shown in Figure 1, systems are usually composed of two stages to measure the similarity between images: 1. represent images as feature vectors by embracing deep neural networks; 2. perform the vector search to obtain the nearest instances from large-scale groups. Both stages are computationally intensive especially when the image database is large. Therefore, it is crucial to accelerate the search by image engines to meet low latency and low energy consumption requirements on edge platforms.
KV260 made a perfect match with the search engine, the feature vector extraction and graph matching can be offloaded and accelerated by the programmable logic while the image dataset management and user-friendly query interfaces can be implemented on the powerful ARM cores.
This project combines the AMD-Xilinx DPU accelerator and the customized graph-based feature vector search accelerator to construct an efficient AI-driven search by image engine on KV260 for building an image similarity search application.
System DesignOverview
As shown in Figure 2, our system contains three major components.
- First, it adopts the AMD-Xilinx DPU to accelerate the model inference for the feature extraction phase in real-time.
- Second, we customize the accelerator for the graph search algorithm to perform real-time and efficient image feature matching even with a large-scale image set.
- Lastly, to ease the interaction with users, we develop a web framework, by which the user can upload the query image and review the returned results from their mobile phones or computers.
Next, we shall introduce details of each component.
The DPU-accelerated Neural Network
Our system adopts deep hashing methods to achieve effective yet condensed data representation. Figure 3 exemplifies a deep hashing architecture, Hash-MinigoogleNet, where a hash layer follows the last layer of minigooglenet to project the data feature learned from the neural network into the hash space, and the generated hash code can be directly used to index the relevant data structures and get rid of the complex data preprocessing stage. The inference of this model is offloaded to the DPU accelerator in the PL part of KV260.
Customized Graph Search Accelerator
While there are many existing feature vector search algorithms, we adopt the graph-based vector search algorithm KGraph because graph-based approaches demonstrate superior performance in latency and accuracy and are widely adopted at Facebook (FAISS) and Microsoft (SPTAG).
The intuition of graph-based vector search methods is that a neighbour’s neighbour is likely to be a neighbour. Figure 4 demonstrates its processing flow. Given a query q, navigational vertices P, graph-based vector search starts from evaluating the distance of the navigational vertex p in P to q and then conducts a search in the graph G from P to iteratively check neighbours’ neighbours in the graph to update the true neighbours of the query q.
Based on the above algorithm, this project customizes a graph search accelerator to perform a low-latency graph search. As shown in Figure 5, the graph search accelerator mainly consists of a graph index buffer, the bitmap filter module, hamming distance computing module, and result buffers. The controller module obtains the uncheck vertex from the result buffer to inform the CDMA module read the edge list information from DRAM to the graph index buffer.
In addition, to simplify the data reading process and the design of the controller module, as shown on the left side of the figure, we choose to merge the graph index structure with the feature vector and place them into the DRAM memory. During the execution of the graph search accelerator, we can acquire the feature vector information while reading the neighbour information.
The User-Friendly Interaction
To provide a better demo experience, we also develop an end-to-end web application for users to interact with the accelerated search by image engine. That's to say, users could play with our system with their browsers either on a computer or mobile phone.
The flow of the web service is shown in Figure 6. First, we save the retrieved images uploaded by the user, then invoke the DPU to get the hash feature values of the image, and subsequently, invoke the graph search accelerator to retrieve the final similarity results. Finally, it returns similar images to the user through the internet.
Performance EvaluationInference Speed
We evaluated the hash-minigooglenet inference performance on PYNQ with DPU B4096@300 MHZ. The measured inference latency is 1.5039ms. This is a 20.58X speedup overCPU (Intel Xeon Platinum 8163) and a 4.99X speedup over GPU (Nvidia P100) on the model inference on Caffe.
CPU GPU AMD-Xilinx DPU (B4096@300MHz)
30.95276 ms 7.51 ms 1.5039msFeatureVector Search Latency
We measured the search latency when running the graph search application on the KV260 board using the CIFAR-10 dataset. We compared it with the Brute Force solution and graph search solution on the CPU (Intel Xeon Platinum 8163 ) using the same dataset. As shown in Figure 7, the customized accelerator delivers up to 23.645X speedup compared to CPU graph search solution and 43.96X speedup compared to brute force search solution based on CPU (Intel Xeon Platinum 8163 ). Meanwhile, the accuracy of our graph accelerator is better than that of the CPU.
Let's start with a hand-on-hand Demo to see how powerful is our system.
Prerequisites
- Set up the board, flash the SD card with the KV260 Vision AI starter Kit Image according to the official guide, and connect the KV260 board to the Internet.
- Download the prepared files of the system Demo File in the attachment file, copy them to the board and unzip it.
Run the Demo
- Register the accelerator to the board by executing the following commands.
cd dpu_kgraph
cp -r ./Web /home/petalinux/
mkdir /home/petalinux/userupload
cp -r ./cifar10 /home/petalinux/
sudo mkdir /lib/firmware/xilinx/kgraph_dpu
cp system.dtbo system.bit.bin shell.json /lib/firmware/xilinx/kgraph_dpu
sudo xmutil listapps
sudo xmutil unloadapp
sudo xmutil loadapp kgraph_dpu- Configure the web framework. Replace every IP address in
dpu_kgraph/Web/a_test.htmlwith your board IP address. For example, my board IP is192.168.137.219,the following commands must be required.
vim dpu_kgraph/Web/a_test.html
# execute the replace all command in vim
:%s/192.168.137.55 (the original address in the file )/192.168.137.219/g- Start the Engine and Query the Database
chmod 777 ./run.sh ./kgraph_dpu
sudo ./run.shType your_board_address:50080 in the Web Browser on devices under the same network with your board to access services and enjoy the demo. See the recorded demo video below.
Step-by-Step DeploymentWe now present the detailed deployment process of our system in terms of both hardware and software aspects.
The hardware mainly focuses on:
- how to use VIVADO to integrate a custom graph search accelerator and build a platform to generate the corresponding XSA file;
- how to use Vitis to integrate Xilinx's DPU neural network accelerator based on the XSA file.
The software side mainly includes:
- how to train, quantize, and deploy neural network models to DPU;
- how to construct a graph index for the graph search accelerator;
- how to develop graph search applications to enable user access from the Internet.
As shown in Figure 8, the hardware development mainly contains two steps:
Step-1. Develop Hardware platform via Vivado:
- Launch Vivado and Create a Vivado Project: Select Kria KV260 Vision AI Starter Kit, and click connections select Vision AI Starter Kit carrier card and click ok. The project should be configured to an extensible Vitis platform.
- As shown in Figure 9. Add MPSoC, Clocking, and Reset IP to build a platform for adding DPU kernel in Vitis project.
Integrate the customized graph search accelerator (Figure 10, and Figure 11), we also provide the Verilog code of the graph search accelerator, you can check it in the attachment file and GitHub project.
- Export Hardware XSA file. As shown in Figure 12, firstly, click the platform setup tab. Secondly, select the AXI port, clock, and interrupt tab. Thirdly, enable the port and interface used by DPU. Finally, export the hardware xsa file.
Step-2. Create Vitis platform based on XSA file:
- Launch Vitis and Create Vitis platform project based on the Vivado hardware XSA file.
source <Vitis_Install_Directory>/settings64.sh
vitis &- Create Vitis DPU application project based on Vitis platform project. (Figure 14 and Figure 15). And add Vitis DPU kernel to the project. (Figure 16)
//Add Vitis-AI repository
//Download the Vitis-AI cross compile environment including library and sdk
wget https://www.xilinx.com/bin/public/openDownload?filename=sdk-2021.1.0.0.sh -O sdk-2021.1.0.0.sh
wget https://www.xilinx.com/bin/public/openDownload?filename=vitis_ai_2021.1-r1.4.0.tar.gz -O vitis_ai_2021.1-r1.4.0.tar.gz
chmod +x sdk-2021.1.0.0.sh
./sdk-2021.1.0.0.sh
tar -xzvf vitis_ai_2021.1-r1.4.0.tar.gz -C ./sysroots/cortexa72-cortexa53-xilinx-linux/
/**** Noted that the Xilinx also provide a host cross compiler setup.sh to configure the above environment ****/
wget https://raw.githubusercontent.com/Xilinx/Vitis-AI/1.4/setup/mpsoc/VART/host_cross_compiler_setup.sh
./host_cross_compiler_setup.sh- Update DPU configuration for KV260. The configuration includes architecture (Figure 17), DPU clock, and connectivity (Figure 18). Note that since the KV260 provides hardware resources that need to be partially allocated to the graph search accelerator, the remaining hardware resources allow us to configure the DPU to B1152. this problem can be solved by using a SOM board with more resources.
/*====== Architecture Options ======*/
`define B1152
`define URAM_ENABLE
`ifdef URAM_ENABLE
`define def_UBANK_IMG_N 5
`define def_UBANK_WGT_N 17
`define def_UBANK_BIAS 1
`elsif URAM_DISABLE
`define def_UBANK_IMG_N 0
`define def_UBANK_WGT_N 0
`define def_UBANK_BIAS 0
`endif
`define DRAM_DISABLE
`ifdef DRAM_ENABLE
`define def_DBANK_IMG_N 1
`define def_DBANK_WGT_N 1
`define def_DBANK_BIAS 1
`elsif DRAM_DISABLE
`define def_DBANK_IMG_N 0
`define def_DBANK_WGT_N 0
`define def_DBANK_BIAS 0
`endif
`define RAM_USAGE_LOW
`define CHANNEL_AUGMENTATION_ENABLE
`define DWCV_ENABLE
`define POOL_AVG_ENABLE
`define ELEW_MULT_DISABLE
`define RELU_LEAKYRELU_RELU6
`define DSP48_USAGE_HIGH
`define LOWPOWER_DISABLE
`define MPSOC
```The software consists of the offline stage and the online web service stages. There are six steps in the offline stage, as shown in Figure 19.
We need to first train the neural network, then quantize it, compile it, and deploy it to the DPU. Then, we generate the corresponding feature vector for each image in the image dataset (hash coding is used in this project) using DPU on the KV260 board and build the graph index based on the hash coding of the images using kgraph software. In order to conform to the input format of the graph search accelerator, we fuse the hash coding with the graph index to generate a binary file that conforms to the graph search accelerator. More details about the offline stage and online stage are shown as follows:
Step-1.Train the neural network:
- we can leverage train.sh file to train the hash-minigooglenet using the CIFAR-10 dataset. When the training step is done, the training log file and caffemodel are generated. From the log file (Figure 20), we can get the accuracy of the model.
docker pull bvlc/caffe:gpu
docker attach "the docker id of bvlc/caffe:gpu"
cd {$github project}/Model_Development/DeepBinaryCode/
make all -j 32
cd examples/CIFAR10
./train.sh
or
../../build/tools/caffe train -solver solver.prototxt --weights googlenet.caffemodel -gpu 3 2>&1 | tee DPU_log.txtStep-2. Quantize googlenet neural network:
- From Step-1, we can get the hash-minigooglenet caffemodel, and we can rename it to float.caffemodel and rename hash-minigooglenet.prototxt to float.prototxt. Meanwhile, we need to prepare the calibration dataset for Vitis ai quantizer. We provide the quantization.sh in the attachment file.
docker pull vitis-ai-gpu:1.4.0
docker attach "the docker id of vitis-ai-gpu:1.4.0"
cd {$github project}/Model_Development/DeepBinaryCode/DPU
./quantization.sh
or
vai_q_caffe quantize \
-model ./float.prototxt \
-weights ./float.caffemodel \
-keep_fixed_neuron \
-method 0 \
-test_iter 10 \
-gpu 0When the quantization is down, deploy.prototxt and deploy.caffemodel are generated in the quantize_results file.
Step-3. Compile hash-minigooglenet neural network:
- First, Before compiling the deploy.caffemodel generated from Step-3, we need to prepare arch.json file of customized DPU architecture.
${Vitis_project_path}/kgraph_dpu_system_hw_link/Hardware/dpu.build/link/vivado/vpl/prj/prj.gen/sources_1/bd/design_1/ip/design_1_DPUCZDX8G_1_0In our project, the arch.json file for KV260 DPU with B1152 configuration has content:
{"fingerprint":"0x1000020F6012203"}Secondly, we can get the deploy.prototxt and deploy.caffemodel. Based on the arch.json, we can compile hash-minigooglenet model for DPU. Due to the sigmoid layer cannot deploy on DPU and the fully connected layer does not use in the inference stage, we need to remove the sigmoid layer and FC layer in deploy.prototxt. Then we run compile.sh to get the.xmodel file.
cd Model_Development/DeepBinaryCode/DPU/
./compile.sh
or
vai_c_caffe \
--prototxt ./quantize_results/deploy.prototxt \
--caffemodel ./quantize_results/deploy.caffemodel \
--arch ./arch.json \
--output_dir . \
--net_name googlenetWhen the compiler is done, the googlenet.xmodel is generated and we can deploy this model on DPU.
Step-4.1. Generate hash code using Xilinx DPU on the KV260 board:
- In this step, we deploy googlenet.xmodel on DPU using the KV260 board. Meanwhile, we leverage DPU to extract the hash code of images in the CIFAR-10 dataset. The code for this step:
void runDPU(std::unique_ptr<vart::Runner> &runner, std::string image_file_name) {
auto input_tensors = runner->get_input_tensors();
auto output_tensors = runner->get_output_tensors();
// create runner and input/output tensor buffers;
auto input_scale = vart::get_input_scale(input_tensors);
auto output_scale = vart::get_output_scale(output_tensors);
// prepare input tensor buffer
CHECK_EQ(input_tensors.size(), 1u) << "only support googlenet model";
auto input_tensor = input_tensors[0];
auto height = input_tensor->get_shape().at(1);
auto width = input_tensor->get_shape().at(2);
auto input_tensor_buffer = create_cpu_flat_tensor_buffer(input_tensor);
// prepare output tensor buffer
CHECK_EQ(output_tensors.size(), 1u) << "only support googlenet model";
auto output_tensor = output_tensors[0];
auto output_tensor_buffer = create_cpu_flat_tensor_buffer(output_tensor);
uint64_t data_in = 0u;
size_t size_in = 0u;
std::tie(data_in, size_in) = input_tensor_buffer->data(std::vector<int>{0, 0, 0, 0});
cv::Mat input_image = read_image(image_file_name);
CHECK(!input_image.empty()) << "cannot load " << image_file_name;
int8_t* data = (int8_t*)data_in;
cv::Mat image2 = cv::Mat(height, width, CV_8SC3);
cv::resize(input_image, image2, cv::Size(height, width), 0, 0, cv::INTER_NEAREST);
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
for (int c = 0; c < 3; c++) {
float tmp = ((float)image2.at<cv::Vec3b>(h, w)[c]) - mean[c];
data[h*width*3+w*3 + c] = (int8_t) ( tmp * input_scale[0]); //in BGR mode
}
}
}
auto v = runner->execute_async({input_tensor_buffer.get()}, {output_tensor_buffer.get()});
auto status = runner->wait((int)v.first, -1);
CHECK_EQ(status, 0) << "failed to run dpu";
generateHash(output_tensor_buffer.get(), output_scale[0]);
}
int main(int argc, char* argv[]) {
const auto image_file_name = std::string(argv[1]); // std::string(argv[2]);
const auto model_name = std::string(argv[2]);
auto runner = InitDPU(model_name);
const std::string cifar10_path = "../cifar10/";
ReadImagePath(cifar10_path + "train.txt");
for(int i = 0; i < images.size(); i++) {
runDPU(runner, cifar10_path + images[i]);
}
WriteHashCodeToFile("train_hash_code.txt");
return 0;
}
static void generateHash (vart::TensorBuffer* tensor_buffer, float scale) {
auto sigmoid_input = convert_fixpoint_to_float(tensor_buffer, scale);
std::cout << "output size = " << sigmoid_input.size() << std::endl;
float *sigmoid = new float[48];
int i = 0;
for(auto val : sigmoid_input) {
sigmoid[i] = 1. / (1. + exp(-val));
i++;
}
uint64_t hashcode = 0;
int *Hash_code = new int[48];
for (int i=0; i<48; i++) {
Hash_code[i] = sigmoid[i] > 0.5? 1 : 0;
hashcode = sigmoid[i]>0.5? (hashcode | ((uint64_t)1 << (63-i))): ((hashcode & (~((uint64_t)1 << (63-i)))));
}
printf("val = %#018"PRIx64"\n", hashcode);
hash_code.emplace_back(int_array_to_string(Hash_code, 48));
}Step-4.2. Prepare the files for the KV260 board:
- Since Kria SOM uses xmutil to load applications, we need to prepare the related files to deploy our application.
1. generate shell.json
{
"shell_type" : "XRT_FLAT",
"num_slots": "1"
}2. generate system.dtbo: First, open pl.dtsi. Second, update firmware-name = "system.bit.bin". Third, complile pl.dtsi with command dtc -@ -O dtb -o system.dtbo./Petalinux/dt_output/pl.dtsi. This step can refer to offical guide
3. generate system.bit.bin
cd KV260_Vitis/kgraph_dpu_system/Hardware/kgraph
echo 'all:{system.bit}'>bootgen.bif
bootgen -w -arch zynqmp -process_bitstream bin -image bootgen.bifStep-4.3. Copy the files to the board:
- In order to run the application, we need to copy dpu.xclbin, googlenet.xmodel, kgraph_dpu, shell.json, system.bit system.bit.bin, system.dtbo to KV260 board. Meanwhile, we also need to copy the library related to DPU.
#Running on KV260 board
sudo mkdir /lib/firmware/xilinx/kgraph_dpu
cd /home/petalinux/kgraph_dpu
cp system.dtbo system.bit.bin shell.json /lib/firmware/xilinx/kgraph_dpu
sudo xmutil listapps
sudo xmutil listapps
sudo xmutil loadapp kgraph_dpuStep-4.4. Run kgraph_dpu application for hash code extraction on KV260:
- When the application is done, the train_hash_code.txt file is generated.
* Run kgraph_dpu
#Running on target board
chmod +x kgraph_dpu
env LD_LIBRARY_PATH=samples/lib XLNX_VART_FIRMWARE=dpu.xclbin ./kgraph_dpuStep-5. Generate a graph index for vector search:
- The customized graph search accelerator needs a graph index to perform graph search. Thereby, this step aims to generate a graph index using train_hash_code.txt based on a modified kgraph framework.
//dpu_knn_hamming.cpp
Matrix<uint64_t> hash_code(50000,1);
Matrix<uint64_t> query_code(10000,1);
vector<int> hamming_result;
vector<std::string> database_label;
vector<std::string> query_label;
ifstream infile_database,infile_database_label,infile_query,infile_query_label;
infile_database.open("kv260_train_hash_code.txt");
infile_database_label.open("../data/cifar10/train-label.txt");
infile_query.open("kv260_test_hash_code.txt");
infile_query_label.open("../data/cifar10/test-label.txt");
unsigned dim = hash_code.dim();
VectorOracle<Matrix<uint64_t>, uint64_t const*> oracle(hash_code,
[dim](uint64_t const *a, uint64_t const *b) {
count_hamm ++;
uint64_t r = popcount64d(*a^*b);
return r;
});
KGraph::SearchParams Sparams;
Sparams.K = 50 ;
Sparams.S = 100;
KGraph *kgraph = KGraph::create();
{
KGraph::IndexParams params;
params.L = 25;
kgraph->build(oracle, params, NULL);
kgraph->save("kv260_hamming_index",1);
}When./dpu_knn_hamming is done, the graph index kv260_hamming_index is generated.
cd kgraph
./dpu_knn_hammingStep-6. Fuse hash code with graph index:
- as mentioned in the Customized Graph Search Engine Design section, we choose to merge the graph index structure with the feature vector and place them into the DRAM memory. Thereby, we need to fuse hash code with graph index to generate a new graph index file. We provide the dpu_train_hash2bin file to convert the kv260_hamming_index file to a binary file. And we provide the kv260_bin file to fuse hash code with graph index in the kv260_hamming_index file.
./dpu_tran_hash2bin
./kv260_binWhen ./dpu_tran_hash2bin and kv260_bin are done, the final graph index kv260_out_end.bin used by the graph search accelerator is generated. The kv260_out_end.bin file can be read by a customized graph search accelerator.
int main()
{
struct uint48_t hash_code[50000];
uint32_t graph[50002][25];
load_graph("kv260_hamming_index",graph);
string s;
ifstream infile_database;
infile_database.open("kv260_train_hash_code.txt");
int j = 0;
while(getline(infile_database,s)) {
deleteAllMark(s," ");
uint64_t result = 0LL;
uint8_t i=0;
for(auto iter = s.begin(); iter != s.end();++iter) {
string str;
str = *iter;
if(str.compare("0")==0) {
result = set_bit(result,(uint8_t)i,(uint8_t)0);
} else if(str.compare("1")==0) {
result = set_bit(result,(uint8_t)i,(uint8_t)1);}
i++;
}
result = result >> 16;
hash_code[j].data = result;
j++;
}
ofstream out("kv260_init_input_data_test.bin",ios::binary|ios::trunc);
vector<string> string_hash;
for(int i =0; i<50002;++i) {
for(int j=0; j<25; ++j) {
stringstream ss;
ss<<setfill('0')<<setw(sizeof(uint32_t)*2)<<std::hex<<graph[i][j];
ss<<setfill('0')<<setw(sizeof(uint32_t)*3)<<std::hex<<hash_code[graph[i][j]].data;
string sss = ss.str();
string push;
transform(sss.begin(),sss.end(),push.begin(),::toupper);
push = boost::to_upper_copy<std::string>(sss);
cout<<"push="<<push<<endl;
string com("00000000");
string comp(sss.substr(0,8));
cout<<comp<<endl;
if(comp.compare(com) == 0) {
cout<<push.c_str()<<" "<<endl;
}
cout<<sss<<" "<<endl;
char buffer[buffersize];
char data[datasize];
strcpy(buffer,push.c_str());
*(buffer+buffersize-1) = '\0';
charArray2intArray(buffer,data);
out.write(data,datasize);
}
}
out.close();
return 0;
}
#include<stdio.h>
#include<stdlib.h>
int main() {
FILE *input = fopen("kv260_init_input_data_test.bin","rb");
FILE *output = fopen("kv260_out_temp.bin","wb");
FILE *outa = fopen("kv260_out_end.bin","wb");
if(input==NULL||output==NULL) {
printf("error \r\n");
}
fseek(input,0L,SEEK_END);
int length = ftell(input);
char *weight = (char *)malloc(length);
char *weight_new = (char *)malloc(length+50002*6);
rewind(input);
fread(weight,length,1,input);
printf("length is %d ", length);
int i,j,l;
j=0;
for(i=0;i<length;i++) {
if(i%250==0&&(i!=0)) {
for(l=0;l<6;l++) {
*(weight_new+j) = 0;
j++;
}
*(weight_new+j) = *(weight+i);
j++;
} else {
*(weight_new+j) = *(weight+i);
j++;
}
}
fwrite(weight_new,(length+50002*6),1,output);
fclose(output);
printf("\n---------stage 2------------\n");
FILE *new_input = fopen("kv260_out_temp.bin","rb");
fseek(new_input,0L,SEEK_END);
int new_length = ftell(new_input);
char *new_weight = (char *)malloc(new_length);
char *new_weight_new = (char *)malloc(new_length);
char *new_weight_change = (char *)malloc(new_length);
rewind(new_input);
fread(new_weight,new_length,1,new_input);
for(i=0;i<new_length/4;i++) {
//printf("%02x ",*(weight+i));
*(new_weight_new+4*i) = *(new_weight+4*i+3);
*(new_weight_new+4*i+1) = *(new_weight+4*i+2);
*(new_weight_new+4*i+2) = *(new_weight+4*i+1);
*(new_weight_new+4*i+3) = *(new_weight+4*i);
}
j=0;
printf("length is %d ",new_length);
for(i=0;i<new_length/4;i++) {
if(i%16==0&&i!=0)
j=j+16;
int one = j*8 + 60 - 4*i;
int two = j*8 + 61 - 4*i;
int three = j*8 + 62 - 4*i;
int four = j*8 + 63 - 4*i;
*(new_weight_change+4*i) = new_weight_new[one];
*(new_weight_change+4*i+1) = new_weight_new[two];
*(new_weight_change+4*i+2) = new_weight_new[three];
*(new_weight_change+4*i+3) = new_weight_new[four];
}
fwrite(new_weight_change,new_length,1,outa);
fclose(input);
fclose(new_input);
fclose(outa);
}As shown in Figure 22, we developed a web service based on the web framework CROW, which runs on the ARM CPU, together with the application that controls the DPU and the application that controls the graph search accelerator, to provide Image Similarity Search Services to users. Users can access this service by using Web Browser on a mobile phone or Desktop computer.
Step-7. Develop Image Similarity Search application:
- We provide the code file related to the web framework (main.cpp), DPU control (dpu.cpp), and graph search accelerator control (accelerator.cpp) in the attachment.
cd ./KV260_Vitis/code/src/- Main.cpp. This code snippet implements the web service, as well as the DPU and the graph search accelerator invocation. First, the code snippet CROW_ROUTE(app, "/upload") takes the image uploaded by the user and saves it in the userupload folder. Second, the code snippet DPU_hash(query_image_path) calls the DPU to read the user uploaded image and then get the hash feature vector. Subsequently, the code snippet Run_KGraph(hash_code) writes the hash feature vector to the registers of the graph search accelerator and calls the graph search accelerator to retrieve similar images. Finally, the result is back to the user via the network (CROW_ROUTE(app, "/img/<string>")).
vector<string> run() {
uint64_t hash_code;
vector<string> result_file_path;
auto dpu_start = system_clock::now();
hash_code = DPU_hash(query_image_path);
auto dpu_end = system_clock::now();
auto dpu_duration = (duration_cast<microseconds>(dpu_end - dpu_start)).count();
cout << "[DPU Time]" << dpu_duration << "us" << endl;
std::cout << "----DPU for hashcode extraction end-----" << std::endl;
printf("hash_code = %#018"PRIx64"\n", hash_code);
printf("hash_code = %"PRIx32"\n", (uint32_t)(hash_code>>32));
printf("hash_code = %"PRIx32"\n", (uint32_t)(hash_code));
unsigned int *Result_ID;
auto kgraph_start = system_clock::now();
Result_ID = Run_KGraph(hash_code);
auto kgraph_end = system_clock::now();
auto kgraph_duration = (duration_cast<microseconds>(kgraph_end - kgraph_start)).count();
cout << "[KGraph Time]" << kgraph_duration << "us" << endl;
for(int i=0;i<100;i++) {
result_file_path.push_back(baseImagePath + cifar10_file_path.at(Result_ID[i]));
printf("result=%d\n",Result_ID[i]);
}
delete[] Result_ID;
return result_file_path;
}
int main(int argc, char **argv) {
printf("== START: AXI FPGA test ==\n");
init();
KGraph_Open();
crow::SimpleApp app;
crow::mustache::set_base(".");
CROW_ROUTE(app, "/")
([]{
crow::mustache::context ctx;
return crow::mustache::load("./Web/a_test.html").render();
});
CROW_ROUTE(app, "/test")
([](const crow::request& /*req*/, crow::response& res){
string key= "Access-Control-Allow-Origin";
string value = "*";
res.add_header(key,value);
crow::json::wvalue x;
vector<string> result;
result = run();
vector<string>::iterator it;
int i=0;
for(it = result.begin();it != result.end() ; it++) {
string str = (*it).c_str();
replace(str.begin(),str.end(),'/','+');
x["img_path"][i] = str;
i=i+1;
}
vector<string>(result).swap(result);
res.write(crow::json::dump(x));
res.end();
//return crow::response(x);
});
CROW_ROUTE(app,"/img/<string>")
([](string a){
replace(a.begin(),a.end(),'+','/');
crow::response res;
std::ostringstream os;
std::ifstream fi_1(a,std::ios::binary);
os << fi_1.rdbuf();
res.set_header("Content-Type","image/jpeg");
res.write(os.str());
return res;
});
CROW_ROUTE(app, "/upload")
.methods("GET"_method, "POST"_method)
([](const crow::request& req)
{
string tokens[6] ={"name=\"","\"; filename=\"","\"\r\n","Content-Type: ","\r\n\r\n","\r\n------WebKitFormBoundary"};
int position[6];
for(int i=0;i<6;i++) {
position[i] = req.body.find(tokens[i]);
}
string name = req.body.substr(position[0]+tokens[0].length(),position[1]-position[0]-tokens[0].length());
string filename = req.body.substr(position[1]+tokens[1].length(),position[2]-position[1]-tokens[1].length());
string ContentType = req.body.substr(position[3]+tokens[3].length(),position[4]-position[3]-tokens[3].length());
string filecontent = req.body.substr(position[4]+tokens[4].length(),position[5]-position[4]-tokens[4].length());
string final_string = req.body.substr(position[5]);
query_image_path = "/home/petalinux/userupload/" + filename;
std::ofstream file(query_image_path, std::ios::binary);
file.write(reinterpret_cast<const char*>(filecontent.c_str()),filecontent.length());
file.close();
return "aa";
});
app.port(50080)
.multithreaded()
.run();
KGraph_Close();
printf("== STOP ==\n");
return 0;
}- Dpu.cpp. We first preprocess the user-uploaded images and write the data into the memory (cv::resize). Then, we start the Xilinx DPU to get the hash feature vector. Since the Xilinx DPU is unable to handle the sigmoid layer. Thereby, we read the output of the hash layer and leverage the ARM CPU to calculate the output of the sigmoid function (generateHash). Finally, we determine the hash value by judging the output value of the sigmoid function. hashcode = sigmoid[i]>0.5? (hashcode | ((uint64_t)1 << (63-i))): ((hashcode & (~((uint64_t)1 << (63-i)))))
uint64_t runDPU(std::unique_ptr<vart::Runner> &runner, std::string image_file_name) {
auto input_tensors = runner->get_input_tensors();
auto output_tensors = runner->get_output_tensors();
// create runner and input/output tensor buffers;
auto input_scale = vart::get_input_scale(input_tensors);
auto output_scale = vart::get_output_scale(output_tensors);
// prepare input tensor buffer
CHECK_EQ(input_tensors.size(), 1u) << "only support googlenet model";
auto input_tensor = input_tensors[0];
auto height = input_tensor->get_shape().at(1);
auto width = input_tensor->get_shape().at(2);
auto input_tensor_buffer = create_cpu_flat_tensor_buffer(input_tensor);
// prepare output tensor buffer
CHECK_EQ(output_tensors.size(), 1u) << "only support googlenet model";
auto output_tensor = output_tensors[0];
auto output_tensor_buffer = create_cpu_flat_tensor_buffer(output_tensor);
uint64_t data_in = 0u;
size_t size_in = 0u;
std::tie(data_in, size_in) = input_tensor_buffer->data(std::vector<int>{0, 0, 0, 0});
cv::Mat input_image = read_image(image_file_name);
CHECK(!input_image.empty()) << "cannot load " << image_file_name;
int8_t* data = (int8_t*)data_in;
cv::Mat image2 = cv::Mat(height, width, CV_8SC3);
cv::resize(input_image, image2, cv::Size(height, width), 0, 0, cv::INTER_NEAREST);
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
for (int c = 0; c < 3; c++) {
float tmp = ((float)image2.at<cv::Vec3b>(h, w)[c]) - mean[c];
data[h*width*3+w*3 + c] = (int8_t) ( tmp * input_scale[0]);
}
}
}
auto v = runner->execute_async({input_tensor_buffer.get()}, {output_tensor_buffer.get()});
auto status = runner->wait((int)v.first, -1);
CHECK_EQ(status, 0) << "failed to run dpu";
return generateHash(output_tensor_buffer.get(), output_scale[0]);
}
uint64_t DPU_hash(std::string ImagePath) {
if(ImagePath == "") {
std::cout << "--error!, image is empty--" << std::endl;
}
std::cout << "----start execute DPU for hashcode extraction-----" << std::endl;
auto runner = InitDPU("./model/googlenet.xmodel");
return runDPU(runner, ImagePath);
}
uint64_t generateHash (vart::TensorBuffer* tensor_buffer, float scale) {
auto sigmoid_input = convert_fixpoint_to_float(tensor_buffer, scale);
std::cout << "output size = " << sigmoid_input.size() << std::endl;
float *sigmoid = new float[48];
int i = 0;
for(auto val : sigmoid_input) {
sigmoid[i] = 1. / (1. + exp(-val));
i++;
}
uint64_t hashcode = 0;
for (int i=0; i<48; i++) {
hashcode = sigmoid[i]>0.5? (hashcode | ((uint64_t)1 << (63-i))): ((hashcode & (~((uint64_t)1 << (63-i)))));
}
printf("val = %#018"PRIx64"\n", hashcode);
return hashcode;
}- Accelerator.cpp. We first write the hash feature code generated by Xilinx DPU to the register of the graph search accelerator. Then, We start the retrieval process by writing to the graph search accelerator's registers write_reg(SLV_REG0_OFFSET, 0x00000002); and poll the completion register to check if the retrieval process has completed (while(1) {if(read_reg(SLV_REG0_OFFSET) == 0x00000000)...}).
unsigned int * Run_KGraph(uint64_t hash_code) {
unsigned int* KGraph_Res = new unsigned int[500];
write_reg(SLV_REG1_OFFSET, (uint32_t)(hash_code >> 32));
write_reg(SLV_REG2_OFFSET, (uint32_t)(hash_code));
write_reg(SLV_REG3_OFFSET, 0x000000C8); // K value
printf("------Accelerator start---------------\n");
write_reg(SLV_REG0_OFFSET, 0x00000002);
write_reg(SLV_REG0_OFFSET, 0x00000000);
usleep(10000);
int j = 0;
while(1) {
if(read_reg(SLV_REG0_OFFSET) == 0x00000000) {
printf("----acceleartor end------\n");
break;
}
}
ptr = memcpy(KGraph_Res,kg_result_vaddr,KGRAPH_RESULT_SIZE);
printf("result:");
int i=0;
for(i=0;i<100;i++) {
printf("result=%d\n",KGraph_Res[i]);
}
return KGraph_Res;
}In summary, we demonstrate how to accelerate the search by image engine on KV260. In particular,
- We leverage the AMD-Xilinx DPU to accelerate the model inference of the computationally intensive feature extraction phase. There is a 20.58xspeedup to CPU (Intel Xeon Platinum 8163) and 4.99x speedup to GPU (Nvidia P100) on the model inference on Caffe.
- We customize a graph search accelerator to provide low latency in the feature vector matching phase. It delivers a 16.83X speedup compared to CPU based graph search solution and a 39.65X speed-up compared to the brute force search solution on the CPU (Intel Xeon Platinum 8163 ). It also achieves higher search accuracy compared to graph search solutions on the CPU.
- We deploy a web framework on KV260 Board and combine the code that controls the AMD-Xilinx DPU and graph search accelerator with the web framework. In this way, the user can upload the query image and review the returned results from their mobile phones or computers.
- In this article, we also provide deployment details from both hardware and software aspects, such that readers can get started with the system easier.
In the future, we plan to extend the project to more scenarios such as video retrieval, recommendation systems, and dialogue systems.
We are sincerely grateful to AMD-Xilinx and Hackster for giving us the opportunity and support for this project.




Comments