




Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
| ||||||
 |
| |||||
| ||||||
 |
| |||||
Sparky Vision is designed as an innovative tool to assist individuals with visual impairments, enabling them to engage with printed and digital media. It's a hands-free device that converts visual content such as books, graphs, and images into audible information. Unlike Braille, which can be limiting for spontaneous reading or for navigating new environments, Sparky Vision provides immediate verbal translation of the content in front of the user.
This technology is not just a study aid; it’s a companion for learning, designed to make education more accessible to everyone. It allows for quick and easy understanding of complex materials, making study sessions more productive. The ultimate goal of Sparky Vision is to ensure that learning and accessing information is a seamless process for everyone, regardless of their visual abilities.
IntroductionWelcome to Sparky Vision, an assistive AI technology that opens up a new world of possibilities for individuals with visual impairments. This document introduces Sparky Vision, a cutting-edge tool that transforms visual information into audible content. With its advanced features, Sparky Vision makes books, graphs, images, and research papers more accessible than ever before.
At its core, Sparky Vision is a user-friendly, hands-free device powered by AI that detects and interprets visual materials, instantly converting them into audible format. It's designed to operate intuitively, requiring minimal input from the user, which makes learning and accessing information straightforward and efficient.
Peek into DemoAccessibility FeaturesSparky Vision is designed to be user-friendly for all, especially for those who have visual impairments. It starts by welcoming users with a friendly audio greeting as they approach, thanks to its motion sensor. As it works, Sparky Vision keeps users informed with audio updates—like when a book is detected or content is being processed—so they always know what's happening. We’ve also thought about how someone would place a book; that's why there's a special spot marked with raised 'Lego' bumps. By feeling for this shape, users can position their materials perfectly every time, making the experience smooth and predictable.
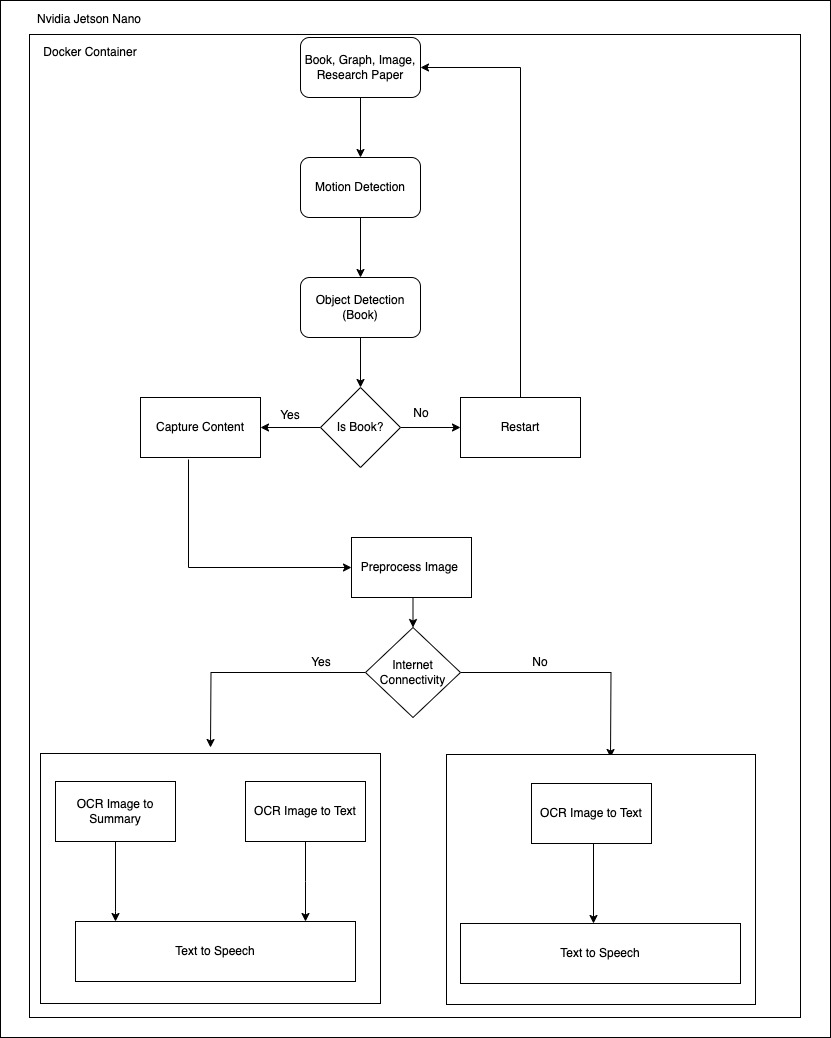
Technology OverviewNvidia Jetson Nano: Powers the AI, providing edge computing capabilities for real-time processing.
Docker Container: Utilizes an Nvidia PyTorch base image to create a reliable and reproducible environment for running Sparky Vision.
Motion Detection: Initiates interaction, waking Sparky Vision when a user is near using sensitive motion sensors.
Object Detection: Implemented using the ssdlite320_mobilenet_v3_large model, fine-tuned to detect books with high accuracy.
Image Capture & Preprocessing: Handles automatic acquisition of visual content and prepares it for analysis.
OCR (Optical Character Recognition): Tesseract-OCR translates images of text to machine-encoded text for processing.
Summarization: Employs Google's GEMINI model to generate concise summaries from the detected text when online.
Text-to-Speech: Google Cloud Text-to-Speech provides natural-sounding audio online, while pyttsx3 serves as the offline voice response system.
Python Libraries: Incorporates libraries such as pytesseract, numpy, pandas, and more for various functionalities from image processing to data manipulation.
Internet Connectivity: Checks for an internet connection to decide between online summarization or offline text conversion.
Auditory Feedback: Gives users step-by-step voice updates during the process, enhancing the understanding of Sparky Vision's status.
User Interaction Design: Includes physical 'Lego-like' reference points to guide users in correctly placing books for scanning.
My problems and Resolutions- For better text recognition, upgraded from a low-quality Logitech C270 webcam to a higher-resolution camera.
- Encountered detection issues with the Raspberry Pi camera; it wasn’t recognized by the device.
- Faced version compatibility problems with PyTorch; resolved by using a specific Nvidia Docker image for PyTorch.
- Encountered multiple installation dependencies with Python libraries; streamlined the process with a Dockerfile.
- Experienced issues with CUDA device recognition on an old SD card; re-flashing a new SD card solved the problem.
- Had trouble with client library inconsistencies; switched to using API services as a workaround.
Preparation: Ensure you have a 64GB (32 also works but docker images taking up space for me) microSD card and a Mac with the ability to read and write to SD cards.
Download Image:
Go to the NVIDIA Jetson Nano Developer Kit SD Card Image page.
Download the image to your Mac.
Flash SD Card with Etcher:
Download and install Etcher from balena.io/etcher.
Open Etcher.
Click “Select image” and navigate to your downloaded image file.
Insert microSD Card:
Insert your microSD card into your Mac.
If a pop-up appears telling you the disk is not readable, select “Eject.”
Select Target and Flash:
Etcher should automatically detect your microSD card as the target. If not, click “Select drive” to choose the correct device.
Click “Flash!” and wait for the process to complete. It may take around 10 minutes.
Ignore this message
Flashed!!!
Boot up
Insert MicroSD in Jetson Nano device
Follow these straight forward setup, you know the drill
Device Initialization: The process begins with the Nvidia Jetson Nano, powered by a Docker container which provides a consistent and isolated environment for running the AI models.
Detection Phase:
- Motion Detection: The system first detects if there is motion in front of the camera, indicating a user is present.
- Object Detection: If motion is detected, the system then identifies whether the object in front of the camera is a book (or possibly other materials like graphs, images, or research papers).
Content Processing:
- Capture Content: If a book is confirmed, the system captures the content of the page.
- Preprocess Image: The captured image goes through preprocessing to enhance it for better text recognition.
Connectivity Check:
- Internet Connectivity: The system checks if there is an internet connection available.
OCR and Output:
If internet is available:
- OCR to Summary: The image is converted to text, and then a summary is generated.
If internet is not available:
- OCR to Text: The system still converts the image to text but skips the summarization step.
- Text to Speech: Finally, the text (or summary, if internet was available) is converted into speech output for the user to hear.
Sparky Vision is created to help people with visual impairments hear and understand printed materials like books and graphs. It's built on the small but mighty Nvidia Jetson Nano and uses smart AI to recognize and talk out loud what's in front of it. The design is simple to use; you just walk up to it, and it starts working, keeping you updated with sound. This tool is all about making reading and learning easier for those who need audio to access information, making it a game-changer for education and daily life.
Project setupGetting Started
To get started with Sparky, follow these steps:
1. Clone the Repository
Open your terminal and clone the Sparky repository:
bash git clone https://github.com/divyachandana/Sparky.git2. Navigate to the Sparky Directory
Change directory to the Sparky repository:
cd sparkyRun with Docker
To simplify setup and usage, Sparky can be run within a Docker container.
3.1. Build the Docker Container
Build the Sparky Docker container using the provided Dockerfile:
sudo docker build -t sparky .3.2. Run the Docker Container
Run the Sparky Docker container with the following command:
This Docker command is running a container named "sparky" with
Nvidia GPU support (`--runtime nvidia`),
giving access to camera (`--device /dev/video0:/dev/video0`), and
audio devices (`--device /dev/snd:/dev/snd`).
It's mapping port 8888 on the container to port 8888 on the host (`-p 8888:8888`), and mounting the local directory `/home/dc/Documents` to `/workspace` in the container (`-v /home/dc/Documents:/workspace`).
Additionally, it's launching Jupyter Lab without authentication (`--allow-root --NotebookApp.token='' --NotebookApp.password=''`).
sudo docker run --runtime nvidia -it --rm \
--privileged \
-p 8888:8888 \
--device /dev/video0:/dev/video0 \
--device /dev/snd:/dev/snd \
-v /home/dc/Documents:/workspace \
sparky \
jupyter lab --ip=0.0.0.0 --allow-root --NotebookApp.token='' --NotebookApp.password=''This command sets up the container environment with necessary permissions and volume mappings, and launches Jupyter Lab with Sparky's functionality.
4. Access Jupyter Lab
Once the container is running, access Jupyter Lab in your web browser by navigating to http://localhost:8888.
5. Start Using Sparky
You're now ready to start using Sparky
6. For headless mode:
- Find IP Address:
To find the IP address of your Jetson Nano, open the terminal and run this command:
hostname -i- Power up Device:
Connect your Jetson Nano to a power bank to turn it on.
- Access via SSH:
On another device, open the terminal.
Type in the username of your Jetson Nano followed by its local IP address:
ssh [username]@[host_ip_address]When prompted, enter the password. This will let you remotely access your Jetson Nano.
Steps InvolvedThe SparkVision system starts by detecting user presence through its motion sensor, greeting them to initiate interaction. It then prompts for and verifies the presence of a book. Once a book is detected, SparkVision captures an image of the page and enhances it to improve text clarity for OCR (Optical Character Recognition). The OCR converts the image of the text into editable text, which is then encoded into Base64 format for processing. If an internet connection is available, SparkVision summarizes the text; otherwise, it proceeds to convert the raw text into speech. The text-to-speech conversion is played out loud for the user to hear. The final step involves running all the modules to ensure a smooth operation.
Steps in Detail
Step 1:motion_sensor_detection function is set up to monitor a motion sensor connected to the GPIO pin 23 of the Jetson Nano. When motion is detected, it plays a greeting audio file to welcome the user and proceeds with the rest of the process.
# Step 1: Motion Sensor Detection and Greeting
def motion_sensor_detection():
SENSOR_PIN = 23 # Adjust pin according to your setup
GPIO.setmode(GPIO.BOARD) # Use physical pin numbering
GPIO.setup(SENSOR_PIN, GPIO.IN)
try:
while True:
if GPIO.input(SENSOR_PIN):
# Print greeting message when motion is detected
#print("Helloo, I'm Sparky. Your AI assistant. I'm here to assist you with your books, papers, research papers, images, graphs, pictures.")
play_audio('greetings.mp3')
time.sleep(11)
# Return True to indicate motion detection
return True
else:
# Print message when no motion is detected
print('No motion detected')
# Sleep to avoid continuous looping
time.sleep(2) # Adjust the sleep time as needed
finally:
# Clean up GPIO pins after use
GPIO.cleanup()prompt_for_book function prompts if the placed object is book or not in front of the camera. Upon detection, an audio file is played to confirm the book's presence.
# Step 2: Prompt for Book Detection
def prompt_for_book():
detected = False
# Keep prompting until a book is detected
while not detected:
# Capture image and check for book object
image_path = capture_image('detect_object.jpg')
detected = check_for_book_object(image_path)
# If book is detected, return image
if detected:
play_audio('book.mp3')
time.sleep(5)
return capture_image()
else:
# Prompt user to place a book in front of the camera
print("Please place a book or paper in front of the camera.")
# Sleep to allow time for placing the book
time.sleep(5) # Adjust the sleep time as necessaryThis process loads a pre-trained SSD (Single Shot MultiBox Detector) MobileNet model, which is efficient for edge devices like the Jetson Nano, which is ready to detect objects in images(we need to detect book). The check_for_book_object function processes an input image: it resizes, normalizes, and converts it into a tensor suitable for the model.
The function checks the model's predictions to see if a 'book' is recognized, indicated by the class ID (typically 84 in COCO dataset). If a book is detected, it returns True.
# Step 3: Check for Book Object
def check_for_book_object(image_path):
# Define transformation for the image
transform = T.Compose([
T.Resize(320),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# Load and transform image
img = Image.open(image_path).convert("RGB")
img = transform(img).unsqueeze(0) # Add batch dimension
img = img.to(device)
# Detect objects in the image
with torch.no_grad():
prediction = model(img)
# Check if 'book' is among the detected classes (class ID for 'book' may vary)
labels = prediction[0]['labels'].tolist()
return any(label == 84 for label in labels) # 84 is often the class ID for 'book' in COCO datasetcapture_image function activates the first connected camera to take a high-resolution picture.
# Step 4: Capture Image
def capture_image(image_path='page.jpg'):
# Initialize the camera
cap = cv2.VideoCapture(0) # Assumes the first camera is the one you want to use
# Set the resolution (adjust the values based on your camera's supported resolution)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
# Warm-up time for the camera
time.sleep(2)
# Capture multiple frames to allow the camera to auto-adjust
for i in range(5):
ret, frame = cap.read()
if ret:
# Save the final frame
cv2.imwrite(image_path, frame)
# Release the camera
cap.release()
return image_pathThe name suggests enhance_for_ocr make tweaks to the image so that it's more viewable for OCR process. Rotates it 90 degrees clockwise to ensure the orientation matches the expected input for OCR processing, converts the image to grayscale, increasing brightness will improve the quality of the text present in the image
# Step 5: Enhance Image for OCR
def enhance_for_ocr(image_path, brightness_value=20):
# Read the image
image = cv2.imread(image_path)
# Rotate the image
rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# Convert to grayscale
gray_image = cv2.cvtColor(rotated, cv2.COLOR_BGR2GRAY)
# Create a numpy array with the same shape as the grayscale image
brightness_array = np.full(gray_image.shape, brightness_value, dtype=np.uint8)
# Increase brightness
brightened_image = cv2.add(gray_image, brightness_array)
# Save the image ready for OCR
corrected_image_path = 'corrected_image.jpg' # Define the path for the corrected image
cv2.imwrite(corrected_image_path, brightened_image)
time.sleep(1)
return brightened_imageThis step converts it into text using OCR. Tesseract analyzes the image and returns the recognized text as a string.
# Step 6: Convert Image to Text using OCR
def image_to_text(image_array):
# Convert numpy array to PIL image
image = Image.fromarray(image_array)
# Use Tesseract to perform OCR on the image
text = pytesseract.image_to_string(image)
# Encode the text to UTF-8 and decode to ASCII
return text.encode('utf-8').decode('ascii', 'ignore')This step converts an image file into a Base64 encoded string, for the image to text summary conversion using Google's Gemini API
# Step 7: Convert Image to Base64 Encoding
def image_to_base64(image_path):
# Open the image file in binary mode and read its contents
with open(image_path, "rb") as image_file:
# Encode the binary data as base64 and decode it as a string
encoded_string = base64.b64encode(image_file.read()).decode()
return encoded_stringThis step is to generate a summary of the text found in the image. This is done by sending a request to a Google API that utilizes the GEMINI model for content generation.
# Step 8: Summarize Text in Image
def summarize_text_image(base64_string):
google_api_key = "YOUR_GOOGLE_API_KEY_HERE" # Replace with your Google API key
url = f'https://generativelanguage.googleapis.com/v1beta/models/gemini-pro-vision:generateContent?key={google_api_key}'
# Prepare the JSON payload
payload = {
"contents":[
{
"parts":[
{"text": "what is in this image?"},
{
"inline_data": {
"mime_type":"image/jpeg",
"data": base64_string # Use the Base64 string obtained from Step 7
}
}
]
}
]
}
# Make the POST request
headers = {'Content-Type': 'application/json'}
response = requests.post(url, headers=headers, data=json.dumps(payload))
# Extract and return the response text
if response.status_code == 200:
result = response.json()
return result['candidates'][0]['content']['parts'][0]['text']
else:
return f"Error: {response.status_code}, {response.text}"the function calls the Google Text-to-Speech API to generate speech from the combined text. The audio content received in response is saved to a file specified by summary_file_path
# Step 9: Convert Text to Speech
def text_to_speech(text, summary):
# Combine text and summary
full_text = f"{text} Summary for the page is {summary}"
# Initialize TextToSpeechClient
client = texttospeech.TextToSpeechClient.from_service_account_json(service_account_file)
# Set up synthesis input with the combined text
synthesis_input = texttospeech.SynthesisInput(text=full_text)
# Set voice selection parameters
voice = texttospeech.VoiceSelectionParams(language_code="en-US", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL)
# Set audio configuration
audio_config = texttospeech.AudioConfig(audio_encoding=texttospeech.AudioEncoding.MP3)
# Synthesize speech
response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config)
# Write audio content to file
with open(summary_file_path, "wb") as out:
out.write(response.audio_content)
# Print confirmation message
print(f"Audio content written to file {summary_file_path}")play_audio function is designed to automatically play an audio file specified by the file_path parameter.
# Step 10: Play Audio
def play_audio(file_path):
# Display and play audio file
return display(Audio(file_path, autoplay=True))pyttsx3 library works offline for text to speech conversion.
# Step 11: Offline Text-to-Speech
def offline_text_speak(text):
# Initialize text-to-speech engine
engine = pyttsx3.init() # object creation
# Set speech rate
rate = engine.getProperty('rate')
engine.setProperty('rate', 100)
# Set voice (0 for male, 1 for female)
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[1].id) # 1 for female
# Speak the text
engine.say(text)
# Run and wait for speech to finish
engine.runAndWait()
# Stop the engine
engine.stop()Check connectivity to ensure Sparky works online and offline
# Step 12: Check Internet Connection
def check_internet_connection():
try:
# Send a request to Google to check internet connectivity
response = requests.get('http://www.google.com', timeout=1)
# Return True if the response status code is 200 (OK)
return response.status_code == 200
except requests.ConnectionError:
# Return False if there's a connection error
return FalseThe Final Step integrates all the previous components. This step effectively leverages both online and offline resources to provide the user with accessible content
# Final Step
if motion_sensor_detection():
image_array = enhance_for_ocr(prompt_for_book())
play_audio('processing.mp3')
text = image_to_text(image_array)
if check_internet_connection():
print("Device has internet connection.")
summary = summarize_text_image(image_to_base64(corrected_image_path))
text_to_speech(text, summary) # Convert summary to speech
play_audio(summary_file_path)
else:
print("Device does not have internet connection.")
offline_text_speak(text)Audio Output listen here : https://github.com/divyachandana/Sparky/blob/main/final_output_1/summary.mp3
Picture
Audio Output Listen here:
https://github.com/divyachandana/Sparky/blob/main/final_output_4/summary.mp3
GraphAudio output Listen here:
https://github.com/divyachandana/Sparky/blob/main/final_output_2/summary.mp3
Research PaperAudio output Listen here:
https://github.com/divyachandana/Sparky/blob/main/final_output_3/summary.mp3
The next version of Sparky introduces multilingual support for both OCR and text-to-speech functionalities. Enables users from diverse linguistic backgrounds to access and interact with printed materials in their native languages, broadening the impact and usability. And also add Voice assistant for two way communication and it will be easy for users to deep dive into complex information.
ConclusionIn conclusion, SparkVision stands as a pioneering tool designed to transform the way individuals with visual impairments engage with the world of printed and digital media. By harnessing the power of AI and cutting-edge technology, it offers a new dimension of accessibility and learning, paving the way for endless possibilities in education and daily life.
Glossary- AI : Artificial Intelligence
- OCR (Optical Character Recognition): Software that converts images of text into machine-encoded text.
- Nvidia Jetson Nano: A small, powerful computer designed for AI development and applications.
- Docker: A platform used to create, deploy, and run applications in containers.
- GPIO (General Purpose Input/Output): Pins on a computer board used to interact with other electronic components.
- Tesseract-OCR: An open-source OCR engine for various operating systems.
- Pyttsx3: A text-to-speech conversion library in Python that works offline.
- Base64 Encoding: A method for encoding binary data into a string of ASCII characters.
- Text-to-Speech: Technology that converts written text into spoken words.
- API (Application Programming Interface): A set of rules that allows different software entities to communicate with each other.
- SSD (Single Shot MultiBox Detector): An algorithm for object detection in images.







{kind=link}
Comments
Please log in or sign up to comment.