




Software apps and online services | ||||||
 |
| |||||
In today's market, numerous products like Google Home, Amazon Alexa, and Apple Home are available to assist with everyday tasks. These smart devices provide innovative ways to interact with the internet and manage intelligent home systems. However, they have several significant limitations:
- Limited Customization: Current smart devices restrict users' ability to tailor the device's functionality to their specific needs and preferences.
- Lack of Emotional Intelligence: These devices lack the ability to understand and respond to the emotional states of users
- Inadequate Support for Multiple Users: Many smart home systems struggle to effectively manage multiple users. They often fail to differentiate between individuals, leading to confusion and miscommunication.
- Poor Accessibility for Children: Existing products are not well-designed for interaction with children. They often lack age-appropriate content and fail to consider the unique ways in which children communicate and interact with technology.
These limitations collectively contribute to a problem where smart home devices fall short of providing a fully satisfactory and inclusive user experience. Users are left with devices that do not fully meet their individual needs or adapt to their specific contexts, diminishing the potential benefits of smart home technology.
We need to provide a new solution that addresses these shortcomings by offering advanced customization, emotional intelligence, robust multi-user support, and enhanced accessibility for children. This solution should be capable of recognizing individual users, understanding their emotional states, and adapting to the specific environmental context. By doing so, it will deliver a more personalized, empathetic, and inclusive smart home experience, ultimately improving user satisfaction and engagement.
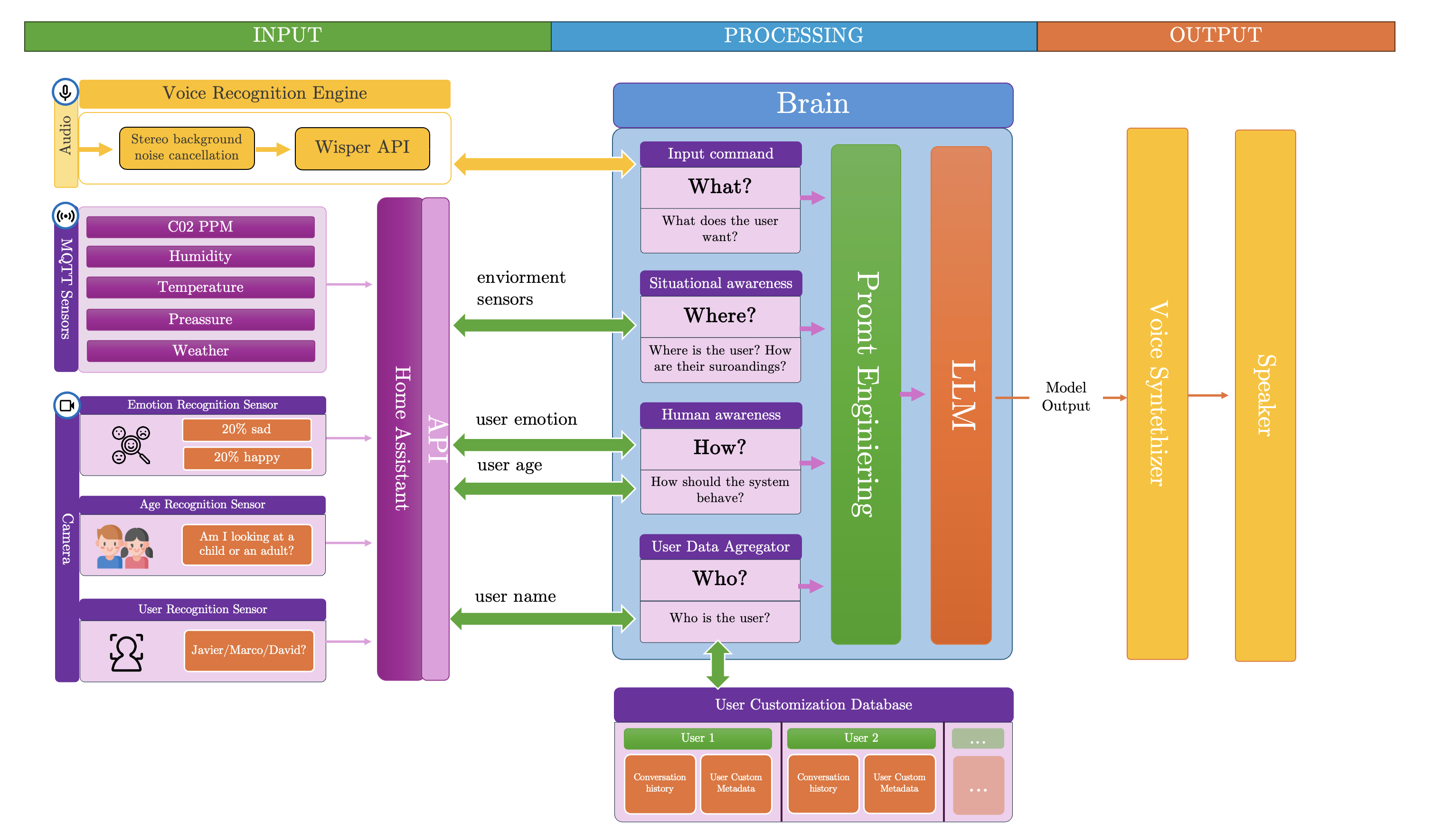
What is our solution?To address these issues, we developed NextAssistant: an intelligent, adaptable, and proactive home assistant. NextAssistant is designed to understand who is speaking, how the person is feeling, and the environment in which they are located. By integrating user-specific recognition and emotional analysis with real-time environmental data from room sensors, NextAssistant offers a truly personalized and responsive smart home experience.
How it works from a user perspective?When the user positions himself in front of the camera-microphone module, NextAssistant seamlessly identifies them, accessing their personal data folder which contains their name, response preferences, age and some other useful information. Additionally, it discerns the user's emotional state and assesses environmental factors, like C02 levels. Following this, NextAssistant prompts the user if he requires assistance. Once the user responds or requests a specific task, NextAssistant tailors its responses with personalized parameters for the specific user, ensuring an optimized user experience.
NextAssistant's internal workings are divided into three phases: Input, Processing, and Output. In the Input phase, data is gathered from the Voice Recognition Engine (VRE), which records the user request, and from sensors connected to our custom Home Assistant instance (HA) running in Docker. This sensors include MQTT environment sensors, our custom User Recognition Sensor (USR), and our custom User Emotion Recognition Sensor (UERS). In the Processing phase, all input is preprocessed by the Prompt Engineering Module (PEM), which also gathers data from the user database to create an appropriate prompt that is passed to the Large Language Model (LLM). The LLM then generates an appropriate and personalized response, which is converted into voice by the Voice Synthesizer Engine (VSE) and played through speakers. Lets take a deep dive in the technology stack used by NextAssistant:
Input phase
During the input phase, we utilize environmental sensors for monitoring various parameters including CO2 levels, barometric pressure, temperature, pressure, and humidity. These sensors transmit their data via MQTT to our bespoke Home Assistant Instance, seamlessly hosted within Docker for simplified setup. Additionally, we've developed three custom sensors:
- User Recognition Sensor: Leveraging a camera feed, this sensor employs facial recognition techniques to identify individuals interacting with the camera. By employing image transformations, we enhance facial features for accurate recognition.
Since we are already using the camera, let's do some image classification. Instead of training a model for every possible classification problem, we have one general purpose model. Its name is CLIP, and it returns the probabilities that some caption is associated with the image. So, for example, to classify between dogs and cats you would enter "a photo of a dog" vs "a photo of a cat". This makes our vision module extremely customizable, as the user can change the predicted classes simply by editing the txt file. We demonstrate our system's vision performance through real time face emotion classification and age group classification.
- Emotion Recognition Sensor: The input is a camera feed and it's able to identify the primary emotion of the user looking at the camera. This is just an application of CLIP using the labels of happy and sad.
- Age Recognition Sensor: For Age Recognition we also use CLIP. This time we feed it labels such as young man, old man.
Our custom sensors are Restful Home Assistant Sensors. These sensors are executed with Flash python, that provides a convenient API which Home Assistant can access in a convenient way.
Processing phase
To process user input and generate suitable responses, we first craft an appropriate prompt and then transmit it to our chosen Language Model (LM), Llama2.
Output phase
Once the LLM has generated the personalized response for the user, it undergoes processing by the Voice Synthesizer Module. This module receives the text and produces a voice output that feels natural to the user, achieved through a custom model known as Tacotron. Tacotron is a state-of-the-art neural network architecture designed specifically for text-to-speech synthesis, ensuring high-quality and natural-sounding speech. The audio generated by Tacotron is then played through the speakers, providing the user with a seamless interaction experience.
Technical details about the AI models used in this projectWe wanted to play into the home assistant fantasy, so we made sure our solution would be capable of speaking and listening. Armed with realistic text to speech neural models like Whisper, our system is able to communicate in a (hopefully) natural way. The audio models surpassed our expectations, and they were even able to clone Lex Fridman's voice just with a 30-minute clip. Under the hood, everything is processed by Gemma 2B, Google's latest LLM.
The LLM is also able to answer questions about the different sensors it is hooked up to. All the sensor information is aggregated at the beginning of the prompt, so the system is aware about what is happening around the house. We first classify if the user question is about the house, using few shot prompting. If the question has something to do with the sensors, we add all the information for the LLM to use.
Perhaps the most interesting feature about our system is the user recognition capabilities. Our system, Nextassistant, is able to know who it is talking with through face recognition. How this works is actually quite fascinating and involves a couple of transformations to map the faces to known ones. Once the user has been identified, the model uses the prompt preferences and general information previously stored about him.
In order to handle all of these kinds of data properly, we used custom Home Assistant instance. It is hosted on Docker and has access to all the regular sensors, temperature, CO2... But more importantly, we add our own sensors, one for facial recognition, emotion recognition... In order to add these custom sensors we created restful.
Since we are already using the camera, let's do some image classification! Instead of training a model for every possible classification problem, we have one general purpose model. Its name is CLIP, and it returns the probabilities that some caption is associated with the image. So for example, to classify between dogs and cats you would enter "a photo of a dog" vs "a photo of a cat". This makes our vision module extremely customizable, as the user can change the predicted classes simply by editing the txt file. We demonstrate our system's vision performance through real time face emotion classification and age group classification.
The Team and our Sarajevo EESTECH Hackaton 2024 experienceSpanish Team ❤️🤝 Gen AI
We are Javier, Marco, and David, passionate students in Computer Science and AI. This event was a great learning opportunity for us! Our team had not deployed generative AI before, but after this challenge, we are convinced of its capabilities. We had a lot of fun at the EESTech Hackathon 2024 🎉, hosted at HulkApps Headquarters in Sarajevo. Every organizer took care of our well-being during the 24 hours of the hackathon. Thanks to their commitment, we were able to give 100% as a team. Thank you! 🙌😊




{kind=link}
Comments
Please log in or sign up to comment.