


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
| ||||||
Navigating in a previously unseen environment is a challenging task within the field of robotic learning, as the agent has to perform localization, mapping and path proposing in real-time. Further, providing an intuitive interface for the users to guide the agent, such as natural language instructions, can make the task more difficult. However, it is a valuable area of study. In this research, the agent is tasked to navigate to the specified goal location using its forward-facing RGBD image observations and a goal query provided in natural language.
Research in 3D scene graphs (3DSG) ([1], [2]) offers valuable insights for our mapping approach. 3DSG can hierarchically organize multiple levels of semantic meanings as nodes, including floors, places, and objects. The edges in a 3DSG can represent relationships between objects and the traversability between locations. Additionally, the real-time 3DSG construction approach presented by [2] suggests the feasibility of integrating 3D scene graphs into our navigation task.
This detailed semantic structure can serve as a mental map for the agent, facilitating query-to-point reasoning. For example, given a goal query like “I want to go to sleep, where should I go?” and the current 3D scene graph, the LLM can guide the agent towards the appropriate point.
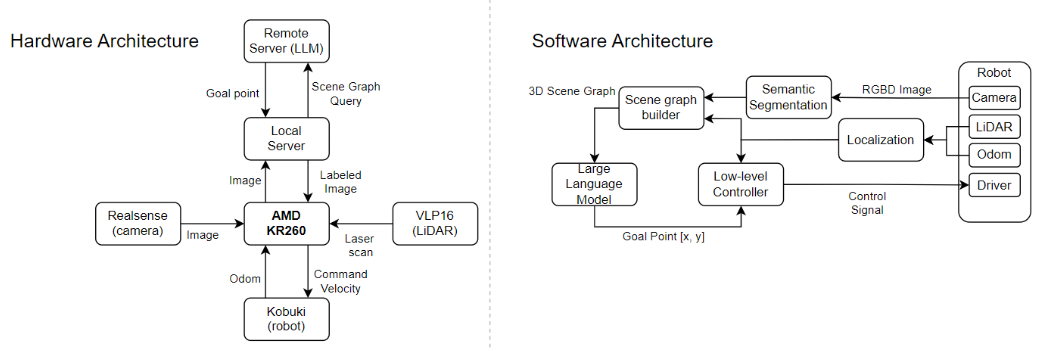
There are 3 main components in our architecture: (1) The AMD KR260 acts as a core component that processes the inputs from several sensors, and updating the 3D scene graph. (2) A local server response for semantic segmentation module. (3) A LLM to reason the 3DSG based on the given query, and output the location the agent should go to.
Compared to Hydra ([2]), our approach supports processing language queries, different from traditional navigation pipeline, which should input a specific goal by user, our pipeline significantly enhancing the flexibility of the user interface. Moreover, Hydra's semantic segmentation method will limit its scene understanding capabilities across diverse environments.
Initially, we aimed to address our navigation task using Reinforcement Learning (RL) methods due to their proven performance in obstacle avoidance and their ability to learn from various inputs (in our case, RGBD images, natural language, and the 3DSG).However, we found that RL methods are unstable during training, largely due to the sparsity of reward signals, and the noisy nature of real-world observations. Consequently, we transitioned from RL methods to 3DSG-based methods.
ArchitectureIn our hardware architecture, various components work together to enable the robot to navigate and interact with its environment efficiently. The AMD KR260 serves as the core component, interfacing with multiple sensors including the Realsense camera, VLP16 LiDAR, and the Kobuki wheeled robot. The KR260 processes input from these sensors, utilizing SLAM to construct a basic 2D costmap for navigation and building a 3D scene graph from labeled images. Due to the high computational load, a local server is employed for semantic segmentation, sending the labeled images back to the KR260 to build a semantic 3D scene graph. The scene graph is encoded into a hierarchical YAML file, which is then queried by a remote server hosting a Large Language Model (LLM) with goal descriptions such as "I want to go to bed." The LLM processes these queries and returns a goal point, which the KR260 uses to navigate the robot to the desired location.
Our software architecture consists of four main modules. The low-level control module receives goal points and control signals to direct the robot's movements. The segmentation module processes RGBD images from the robot's sensors (camera, LiDAR, odometry) and identifies different objects and regions in the environment. The scene graph (SG) builder module constructs a 3D scene graph from the segmented data, representing spatial relationships and object attributes. Finally, the language query module, powered by a large language model, interprets high-level instructions and converts them into goal points for the low-level controller, enabling the robot to understand and execute complex tasks. Later, we will introduce our implementation details in the following paragraph.
Implementation detailsFirst, we use sensors to determine our robot's location. Our method employs the VLP16 LiDAR and wheel encoder on the robot for localization. For convenience, we use a ready-made SLAM (Simultaneous Localization and Mapping) package called Cartographer ROS, released by Google, with some modifications to suit our robot. Once set up, this SLAM module takes input from the LiDAR scans and wheel encoder odometry, producing a 2D costmap of the current environment presented in the image below.
Once the robot's position is determined, we control it based on the current costmap. In our project, navigation is achieved using Nav2, an open-source package. We customize some configuration files to suit our robot. With these adjustments in place, we can use the navigation module to guide the robot to a specific position provided by the user.
To construct a fully semantic 3D scene graph with a broad set of labels and zero-shot capabilities, we use LSeg-minimal as our language-driven semantic segmentation model. LSeg operates by taking both label text and an image as input, and then generating semantic segmentation based on the provided label text. This means the segmentation labels are determined dynamically from the input text, allowing for flexible segmentation across various environments without the need for fine-tuning. This flexibility makes LSeg particularly effective for adapting to different scenarios and accurately labeling the scene based on contextual text input. By plugging LSeg as our segmentation model, it is convenient for us to deploy our robot in different rooms or simulator settings.
After setting up our segmentation model, we integrate LSeg into our system as a ROS node. This node accepts an RGB image and multiple text labels as input and produces a labeled image as output. With the robot's location determined, we combine the labeled RGB image and depth image from a RealSense camera to build our scene graph. For this purpose, we use an open-source project called Hydra as our scene graph builder. However, the original Hydra implementation had difficulty working in different environments because its segmentation works poorly. To solve this, we replaced Hydra's original segmentation with our LSeg model, which we had already integrated into ROS. Additionally, we modified some configuration settings to suit our robot better. This setup allows us to create accurate and adaptable 3D scene graphs for various environments.
Although the 3D scene graph data structure in Hydra is managed entirely within C++ classes, this format is not ideal for direct input to a language model. We believe that a hierarchical YAML file, which presents the scene graph in a more readable format, is better suited for understanding by large language models. To facilitate this, we’ve implemented a feature in Hydra to generate a YAML file from the scene graph. This YAML file is then sent from the KR260 robot to a remote server running the llama-3.1-70B language model. After the model processes the file and provides a target goal pose based on a language query, the resulting goal point is used by the robot’s navigation module to guide it to the desired location. Here is an example of our output YAML formation
building:
id: B(0)
room:
id: R(0)
objects:
- O(4) table [6.5674, 3.4567, 1.23]
- O(2) chair [3.1245, 1.2390, 2.11]
- O(1) table [1.2223, 5.1278, 1.19]
- O(12) light [2.7871, 1.3333, 3.46]
room:
id: R(2)
objects:
- O(16) chair [1.2789, 3.4567, 1.11]
- O(22) bed [7.8901, 1.2233, 3.45]
- O(32) table [3.4545, 1.6789, 2.11]Below is the complete list of workspaces along with a brief introduction to each workspace.
- hydra_ws: Generate the scene graph.
- kobuki_ws: Bring up the kobuki robot.
- realsense_ros1_ws: Setup the Intel Realsense camera.
- ros1_bridge_ws: Message exchanging between ROS1 noetic and ROS2 humble.
- vlplidar_ws: Setup the VLP-16 LiDAR.
- llm_query_ws: Query the LLM.
Step 1: Open the ros1_bridge
Please modify the ROS_HOSTNAME and ROS_MASTER_URI in the "ros1_bridge_ws/docker/compose.yaml" based on your computer setup. Then, use the following command to build the Docker image and create the Docker container to tun the ros1_bridge.
docker compose upStep 2: Bring-up the Robot
Run the script to bring up Kobuki, VLP-16, and Realsense. You may need to modify some settings based on your robot configuration.
cd scripts/
./run.shStep 3: Generate the 3D Scene Graph with LLM Guidance
After building the package in hydra_ws, use the following command to generate the 3D scene graph. Then, use the query script in llm_query_ws to query the LLM with the current scene graph.
# In hydra workspace container
roslaunch hydra_ros run_sg.launch
# In LLM query workspace container
python3 query.pyWe have tested our work in the simulator, and it functions perfectly. However, in real-world settings, the constructed scene graph is problematic. Our analysis shows that the network connection is overloaded due to the need to send images from the KR260 board to the local server. We may try to solve this problem in the future by moving the model to the robot, thereby avoiding the need to send large amounts of data from the robot to the local server.
ReferencePaper survey
- [1]: 3D Scene Graph: A structure for unified semantics, 3D space, and camera
- [2]: Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization
- [3]: Open Scene Graphs for Open World Object-Goal Navigation
Github/Package Link
- Cartographer ROS: https://google-cartographer-ros.readthedocs.io/en/latest/
- LSeg: https://github.com/krrish94/lseg-minimal
- Hydra: https://github.com/MIT-SPARK/Hydra
- Nav2: https://github.com/ros-navigation/navigation2
- LSeg-minimal: https://github.com/krrish94/lseg-minimal
- Hydra: https://github.com/MIT-SPARK/Hydra
{kind=link}



Comments
Please log in or sign up to comment.