



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Introduction
I have the experience of do the neural network to train the images before in the AI course with CNN and RNN. Now I want to get access of the voice recognition. I learn the procedures in details from the textbook to get to set up the training model of wake words. And then I learned to modify the and edit the program so that it can recognize other words and do reaction after heard the words.
Objective
Build a small application to recognize the words "left" and "right" by training on a dataset of speech commands. Once the application listened and recognized the words, it will do reaction by lighting the LED light.
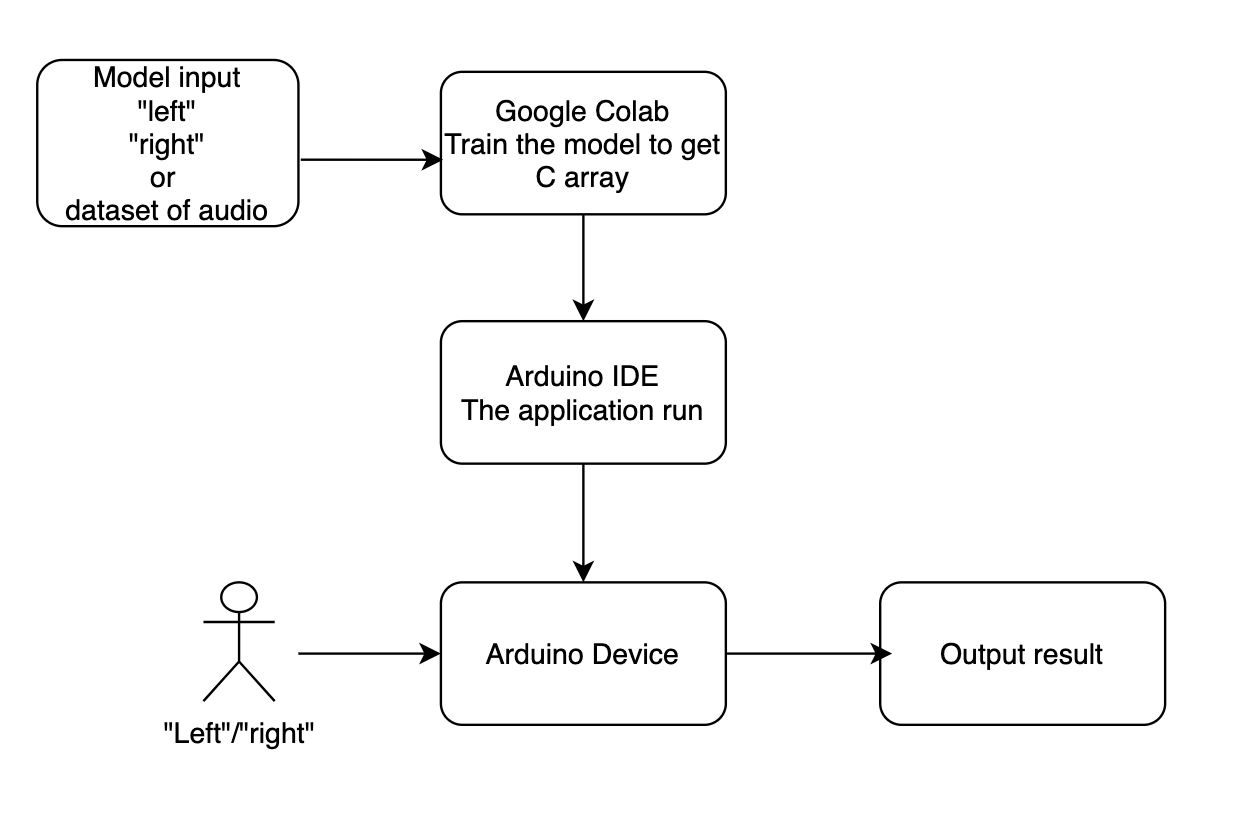
Application Architecture
- Derive the audio data set of the input for training.
- Create architecture and add model code.
- The detection responder toggles the coresponding color of the light of the model output.
The project contains the model input with a dataset of Speech Commands.
- "silence"
- "unknown"
- "left"
- "right"
Swap the array of the class and match the labels with the model's output tensor elements in order.
Step
- Use Google Colaboratory service to build, train and convert the model. Load the notebook and run in Google Colaboratory.
- Derive the script of code by access to Examples -> TensorFlowLite -> micro_speech.
- Edit and save the files so that the application can recognize "left", "right", "silence" and "unknown", upload its to the board.
- Open the monitor in Arduino IDE and say word "left", "right" and any other words to see the changes of the IED light of the board.
Result




{kind=link}
Comments
Please log in or sign up to comment.