

Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
 |
| |||||
| ||||||
Application of stock prediction based on deep learning algorith
(1 Guilin University of electronic technology,guilin,china)
AbstractThis work uses LSTM neural network to predict financial stock time series. Stock data is nonlinear and non-stationary, and traditional econometric models cannot achieve the optimal prediction effect, so more advanced models are needed to accurately describe such nonlinear financial time series. In recent years, with the continuous development of deep learning, there are also corresponding neural network models for stock prediction, such as BP neural network and RNN neural network. The results are not ideal, and the RNN neural network can’t be long-term memory, and has the problem of fast gradient descent and can’t get the optimal solution. LSTM neural network can store and remember the long-term dependence of time series, which is a better model for stock prediction. In addition, this paper uses CPU, GPU and XILINX VCK5000 board to accelerate the computation of LSTM neural network respectively, and explores the acceleration effect of CPU, GPU and FPGA.
key words: LSTM;VCK5000
IntroductionIn recent years, scholars have begun to explore the applicability of relevant algorithms of deep learning in financial time series data prediction. For example, deep learning recurrent neural network (RNN) is used to predict stock price, and good prediction effect is achieved. RNN is a neural network that processes time series data, including sequence correlation, that is, in the learning process, the current state will contain all the historical information of the previous time series. However, the standard RNN structure may have the problem of gradient disappearance or explosion, and it is difficult to learn the long-term dependence of sequences. LSTM neural network with long and short term memory module solves the problem of long term dependence of sequence, and has achieved great success in the application of sequential data such as sequential text translation.
Stock data is not only affected by many factors, but also has complex nonlinear dynamic interaction among the factors. As a result, financial time series data becomes a complex system with sequence correlation, non-stationarity and nonlinear characteristics.
This paper introduces the algorithm implementation scheme and accelerated implementation process, including the implementation process of CPU, GPU and VCK5000 board.
- Objective of the algorithm
The goal of the algorithm is to predict the price of a stock in 10 days.
- Obtaining Data
Use Python's pandas_datareader library to retrieve 10 years of data for a stock from a financial data site.
Input data includes open price, close price, high price, low price and volume.
The data set is divided into two parts, one is training set, the other is test set. Training set accounted for 90%, test set accounted for 10%.
- Data standardization
StandardScaler class in Sklearn, a machine learning tool based on Python language, is used for data standardization processing. In addition, dirty data needs to be processed.
- Neural network stacking
This work uses LSTM neural network design, LSTM structure as shown in the figure above. It mainly includes:
Forget gate: Information by which the forgetgate ft determines culling from a cell.
ft=σ(Wfht-1,xt+bf)
Where σ is the RELU activation function, Wf is the input weight, bf is the bias parameter, xt is the input vector, and ht-1 is the state of the hidden layer at t-1.
Input gate: The previous information is selected into the input gate, and the task at this level is to decide which information needs to be updated and how much.
gt=σ(Wght-1,xt+bg)
Ct'=tanh(Wcht-1,xt+bc)
Ct=ft⨂Ct-1+gt⨂Ct'
Output gate: after finishing the screening of the first two gates, the output gate is finally passed to determine which information needs to be output. There is a switch to control the output in the output date.
Ot=σ(Woht-1,xt+bo)
ht=Ot⨂tanh(Ct-1)
- Neural network structure designed
The designed neural network stack is shown in the figure above.the number of LSTM layer, full connection layer and neural units are determined after the training process.
- training
The training objective was to find the best combination of memory days, LSTM layers, full connection layers and neural units.
The training flow chart is shown in the figure below. Each combination of memory days, LSTM layers, full connection layers and number of neurons is trained for 50 epochs. The model is saved to the file after each 50 epochs through checkpoint callback function, and the best model is finally found.
Parameters of each layer of the optimal model found after training are as follows:
CPU
Implementation steps:
(1) Install Anaconda3 and create and activate the environment.
(2) Install related dependency packages.
(3) install tensorflow2.4 CPU version.
(4) Model training.
(5) Find the optimal model and apply the optimal model to stock prediction.
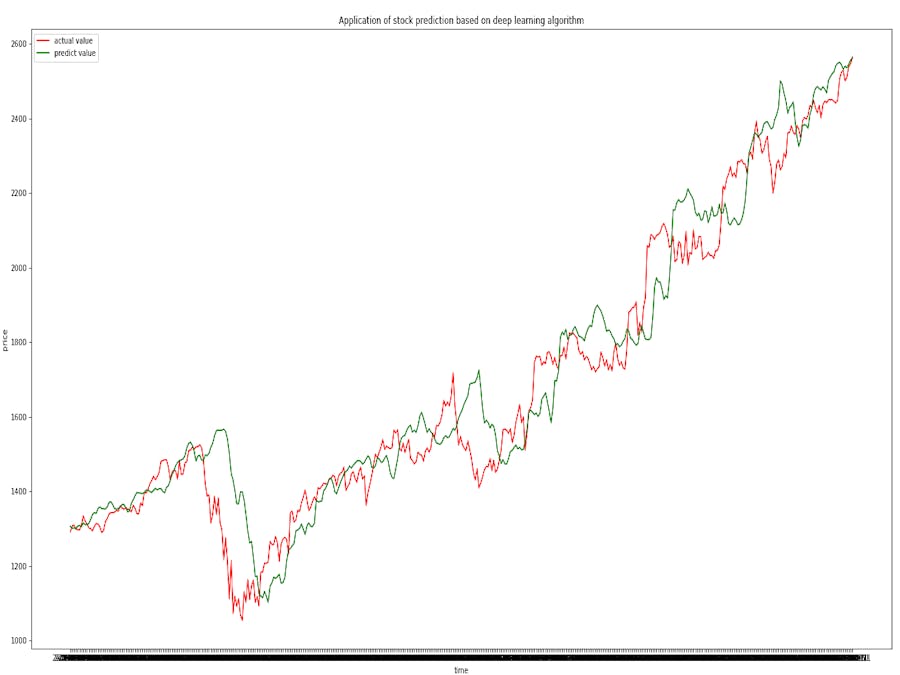
The final result is as follows:
Based on the CPU, The prediction using the test set takes 0.31s.
GPU
Implementation steps:
(1) On the basis of CPU steps, create a new environment to install CUDA toolkit and the corresponding VERSION of cuDNN.
(2) install tensorflow2.4 GPU.
(3) The optimal model is used for stock forecasting.
Based on the GPU, The prediction using the test set takes 0.04s.
VCK5000
- System adaptation and board self-check
(1) ubuntu18.04 was installed, and related dependencies were installed.
(2) Plug in the VCK5000 board card and self-check. The related process is shown as follows.
There is a GEN3 x8 mismatch between the VCK5000 board card and my host, so it can only reach the speed of GEN2 x8.
Run VITIS AI DEMO
- Install docker.
Run VITIS AI DEMO, the effect is as follows:
After familiar with the board and some tortuous problem solving, I can finally successfully run the VCK5000 Demo.
Deployment Scheme
The RNN-based DPU of VCK5000 is shown in the figure above. The essence is GEMM operation with int8 precision. There are 5*8 AI engines in total, and each AI engine provides 32*64*32 GEMM operation, that is, a DPU can calculate 32*320*256 matrix.
Based on this, I need to focus on the following things:
1. Realize the LSTM neuron and encapsulate the input and output of the LSTM neuron.
2. Encapsulate the optimized LSTM neural network function, determine the input and dimensions of each level, and allocate the use of DPU.
3. Reduce quantization error.
4. Learn VCK5000's method of GEMM operation through DPU as well as tanH and RELU operation.
SummaryBased on my host, it is found in actual measurement that GPU is about 6 times faster than CPU when running TensorFlow for LSTM network calculation. It should be noted that this result is not universal, because my CPU and GPU model are specific.
After checking many official materials related to VITIS AI, it is a pity that VITIS AI can’t deploy Sequence model at present, and VCK5000's tools for LSTM are not supported. After a long time of research and attempts, it is difficult to implement deployment.
I have studied the VCK5000 board in detail, it doesn’t support RNN compilation and quantization tools, can only be manually implemented. If I want to implement LSTM in VCK5000, I will most likely need to implement the network model of LSTM myself. If the model I trained in tensorflow needs to be transplanted to VCK5000, I need to know the detailed implementation and quantization of TENSORFLOW's encapsulation function deeply. No matter in VITIS or VITIS AI, it is very difficult in a short period of time. I am also curious to see how much speed the VCK5000 will improve over LSTM networks.
The way ahead is so long without ending, yet high and low I'll search with my will unbending.
CodeSince Github is not available in China, can use: https://pan.baidu.com/s/1AyZMkoQVb1TLHxVMFzmu-A Enter Code:7kj3
钟景成
 Jinger Zeng
Jinger Zeng
Comments