

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
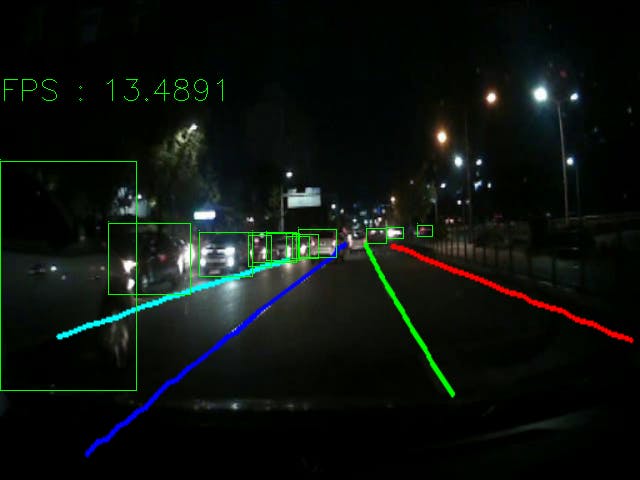
Current Advanced driving assistance systems (ADAS) are driven by Convolutional Neural Networks (CNN) based algorithms owing to their superior performance when compared to traditional algorithms. However these algorithms are only as good as the data on which they are trained upon. Since majority of datasets capture labelled information in well lit conditions, algorithms trained on them perform poorly in other conditions such as during night, rain, fog or snow as can be observed from images below.
As this is an undesirable characteristic, thus there are two ways to overcome such scenarios. (1) Retrain all CNN algorithms on a diverse dataset that captures all environmental information while having the labels for objects and lane. (This is an expensive and time consuming process.) (2) Add another CNN that enhances an image, as a preprocessing stage. In this project, I follow the latter and only consider the case of night driving conditions with ADAS algorithm including object and lane detection. These constraints are set by me to simply limit the scope of this work.
I summarize the tasks to be performed in this project-
- Lane Detection
- Object Detection
- Image Enhancement
Popular object detection algorithms that run in real time rely on a single stage approach wherein they predict offsets for predefined anchor boxes along with categories of objects that are enclosed within them. The Xilinx AI model zoo provides some pretrained models for object detection based on SSD, Densebox and Yolo algorithms. While there exists a model for lane detection via VPGnet, the model isnt available due to compilation issues.
The issue arises that present available models would result in utilization of two algorithms for performing object detection and lane detection and thus reducing inference rate of the complete pipeline. However with a proper formulation, these two tasks can be performed by a single CNN.
- Since the performance of CNN depends on quality of training data, the training process needs to be elaborated. For this project we used Cityscapes dataset and used the semantic segmentation ground truth to generate lane lines and object anchors. The total training time was around 4 days on a system with Titan RTX GPU (primarily to leverage the 24GB memory for increasing the batch size to 16 and image resolution of 512 (W) x 256 (H) x 3). For this project I used ResNet18 pretrained on ImageNet dataset and compressed further by incorporating channel reordering (from ShuffleNet) and using Squeeze Excitation Network.
The optimized network runs at around 10fps on ultra96-v2 depending on its temperature, with the fps on each frame denoting the inverse processing time for that frame. The images were captured at 640 x 480 px from the web camera and directly fed to CNNs after downsampling by 2. Thus for all the tasks the CNN works on 320 x 240 px image. Allowing us to improve the inference rate while maintaining accuracy.
If the cooling is not sufficient the platform crashes.
One of the benefits of using anchor based approach is the ability of generating lane lines in the absence of lane markers, which is where leading SoTA lane detection algorithms fail. (More details in github)
Lane and Object detection Performance of proposed ADAS CNN in standard condition
Now we have the ADAS model, and its failure demonstrated in above picture. I proceed towards constructing the enhancement network. Unlike the ADAS network that follows an encoder based formulation, to predict offsets for lanes and objects based on predefined anchors. The image enhancement network follows an encoder-decoder framework to recover regions within an image that are not visible and thus these features cannot be used. This is the primary reason behind poor performance of ADAS algorithms under low light conditions.
- For the enhancement network, LOL dataset was used. Since this network acts as a preprocessing step, it should be lightweight. Thus a modified UNet with Squeeze-Excitation Networks was used. This model was trained for 200 epochs and took 1 day to train. The resultant network achieved the SoTA performance on the LOL dataset with PSNR - 26.73 db, SSIM - 0.89 and NIQE score of 3.17.
The optimized network runs at 16 fps when deployed on Ultra96-v2, however there are some noise artifacts that can be observed in the videos. This arises from reduction in model performance owing to optimization. The following image illustrates the change in image quality before and after the application of enhancement network.
The combined networks when run on the v2, provides a maximum inference rate of 4 fps. The main bottleneck was switching between fetching and loading the weights associated with each network as both the weights couldnt be stored in memory together. This could be sorted by threading and a better quantization and pruning approach but I skipped it for now.
Optimization and Fine-tuning -
Optimization of CNNs is necessary to reduce the number of parameters and computational cost by pruning and quantization. While these benefits are critical this also results in model performance deteriorating in conditions present in long tail conditions. While this could be solved by leveraging SoTA methods on network pruning, the time cost associated with the validation made me drop this portion for this project. Xilinx also provides an AI Optimizer but it is associated with commercial license, so I used EagleEye implementation to prune the ADAS and Enhancement CNNs and then processed the model within Vitis-AI framework. Since the process is long and tedious, I plan on including the steps in the associated github repo.
Flowchart of the proposed project -
The software pipeline followed in this project is as follows,
HardwareSetup -
Step 1 - Setup Instructions
There are a lot of excellent tutorials on setting up the ultra96-v2. I'll link them here along with their tasks.
- Basic Setup for creating the bootable SD card.
- Vitis AI installation on Host Computer, since it is based on dockers, it doesnt need any significant user interference.
Step 2 - Connections
The connections are simple, and showcased in the picture below. Its strongly recommended to be careful with battery during charge and recharge cycles.
Step 3 - Fixing the setup on the vehicle
Step 4 - Running the Code (Follow the Github Repo)
Demonstration Results -- Reference Video to understand default ISP and frame transitions
All cameras come with a minimalist signal processing pipeline including gamma correction, white balance, demosaicing, denoising and other proprietary algorithms. The following videos demonstrate camera performance under different conditions such as well lit and dark.
NOTE : This project utilized 3 different cars thus there is a noticable viewpoint change arising from different rearview mirror.
Similarly for dark conditions the default ISP results in the following video
- Joint Lane and Object Detection in Well Lit Conditions
- Joint Lane and Object Detection in DarkConditions
- Image Enhancement with Lane and Object Detection in Well Lit Conditions
Since there is no filter to determine when the enhancement network would be applied, it is applied in all conditions. Thus we need to examine its effect on underlying ADAS algorithms.
- Image Enhancement with Lane and Object Detection in DarkConditions
- In this project I deployed my custom Joint Lane and Object detection algorithm and to improve the performance integrated a lightweight enhancement CNN.
- The enhancement network improves visible features but bleeds the colors as well. I believe that can be solved by a simple data augmentation technique.
- Downsampling Images by 2, hurts model performance at the cost of improved inference rate. Hence a better processor such as Jetson Xavier NX would be better for 30 fps inference at native 640 x 480 px resolution. Although that is out of scope for this project, I would be exploring that direction and updating the github repo accordingly.
- The work on repositories is still in progress, as I am currently writing papers corresponding to these works that require comparison with corresponding state of the art (SoTA), I will be updating repos accordingly.
- The repos towards their completion would contain the trained models for both SoTA and proposed algorithms and would be updated for different datasets.
- Right now the priority is to finish writing the papers. The training and inference code will be made available along with the papers.









{kind=link}
Comments