



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
The development of an application that utilizes advanced technology like multimodal models to help blind people understand and experience the world would solve a crucial problem, opening up opportunities for greater freedom and autonomy. This application function by capturing the question and an image with the device's camera, processing it through a trained AI model, and generating a detailed description of the answer, that it would be read for the blind person using a text to speech model, enabling users to grasp important information such as the presence of people, objects, and surroundings. Imagine a world where a blind person can take a picture of their food and understand what's on their plate, or of a building and get a sense of its architecture and surroundings.
My solution assists visually impaired individuals by providing image question answering capabilities. It utilizes a multimodal AI model, a speech-to-text model, and a text-to-speech engine. Here's how it works:
- The user activates the microphone using a push button and records their speech. If the user says "Take a photo, " the solution captures an image using a USB camera. Otherwise, it uses the last captured image and the recorded speech.
- The image and speech are then sent to the multimodal AI model. This model processes the visual data, extracting information about objects, scenes, and environments. It also analyzes the speech to understand the user's question.
- The processed information is then converted into a comprehensive and detailed answer to the user's question. This answer is passed to the text-to-speech engine, which converts it into an audio output.
- The audio output is played back to the user, providing them with the requested information. The solution then waits for another activation, ready to assist with the next query or command.
- By combining computer vision, speech recognition, and natural language processing technologies, this solution empowers visually impaired individuals to understand their surroundings and obtain relevant information through a simple and accessible interface.
The NVIDIA Jetson Nano Orin Developer Kit efficiently process the images and generate descriptions on the user's device in around a minute, without an internet connection, everything is done in the Jetson Orin Nano 8Gb.
Before we can use our Jetson Nano Orin we have to prepare it for that. We need a microSD card (32GB UHS-1 minimum recommended). Here is the guide with the steps https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#intro
We have to install a Jetpack. Visit this link https://developer.nvidia.com/embedded/jetpack
There are two methods:
- SD Card Image Method flash the microSD card and then insert in the Jetson Nano Orin
- NVIDIA SDK Manager Method. Using a linux PC connected to the Jetson Nano in Force Recovery Mode, transfer the information to the microSD card here are the steps. https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html
To put Jetson Nano in Force Recovery Mode, you have to jumper from “FC REC” to “GND”. Pin 3 and 4 from the J50 Button Header and the power on.
I tried the first method but it didn´t work so I finally use the second one. I installed JetPack 6.0 Developer Preview
RAM Optimization
My Jetson Nano is equipped with 8GB of RAM, which is substantial for a microcontroller. However, it falls short for operating a Large Language Model (LLM). Therefore, adherence to the provided instructions is necessary.
https://www.jetson-ai-lab.com/tips_ram-optimization.html
Disable misc services
sudo systemctl disable nvargus-daemon.serviceIt’s essential to set up SWAP, which usually corresponds to the board’s memory capacity. Execute the following commands to deactivate ZRAM and establish a swap file:
sudo systemctl disable nvzramconfig
sudo fallocate -l 16G /ssd/16GB.swap
sudo mkswap /ssd/16GB.swap
sudo swapon /ssd/16GB.swapThen add the following line to the end of /etc/fstab to make the change persistent:
/ssd/16GB.swap none swap sw 0 0Installation Instructions and Dependencies
We have to install two applications ffmpeg and espeak
sudo apt-get install ffmpeg
sudo apt-get install espeak- ffmpeg is a a complete, cross-platform solution to record, convert and stream audio and video. We are going to use it to record speech
- espeak is a compact open source software speech synthesizer
To further enhance the model's performance and responsiveness, we installed PyTorch with GPU support. PyTorch is a popular deep learning framework that utilizes GPUs to accelerate computations, significantly improving the model's processing speed.
UForm, is a multimodal AI library, we are going to use one of theirs models.
To install UForm and PyTorch on Jetson Nano, follow these steps:
- Install UForm:
pip install uform- Install PyTorch with GPU support (JP 6.0.0):
The default pytorch library doesn´t support GPU devices, so you have to install a version that supports it, following this guide:
or running:
wget https://developer.download.nvidia.cn/compute/redist/jp/v60dp/pytorch/torch-2.2.0a0+81ea7a4.nv23.12-cp310-cp310-linux_aarch64.whl
sudo pip install torch-2.2.0a0+81ea7a4.nv23.12-cp310-cp310-linux_aarch64.whl- Torchvision compatibility
To execute the Uform LLM, it is necessary to have torchvision 0.16. Therefore, we must downgrade to this version using the following command:
pip install torchvision==0.16Install pyttsx3
pip install pyttsx3pyttsx3 is a text-to-speech conversion library in Python. Unlike alternative libraries, it works offline
With these installations complete, we are ready to integrate our code into the Jetson Nano system and utilized to provide descriptive image information to blind individuals.
OVERVIEWThe flowchart illustrates the following steps:
- The program starts by loading the necessary models for automatic speech recognition (ASR) and vision tasks.
- It captures an initial picture using the connected camera.
- The program enters a loop where it waits for a button press.
- When the button is pressed, it transcribes the audio input from the microphone.
- If the transcribed input is "Take a photo.", the program captures a new picture.
- If the transcribed input is not "Take a photo.", the program generates an output based on the input question and the current image using the vision model.
- The generated output is written to a file.
- The program uses a text-to-speech engine to say the generated output aloud.
- The loop repeats, waiting for another button press.
The flowchart shows the main logic of the program, including the interaction between the button press, microphone input, image capture, and the generation of output based on the input and image.
STEPSSpeech to text Capture
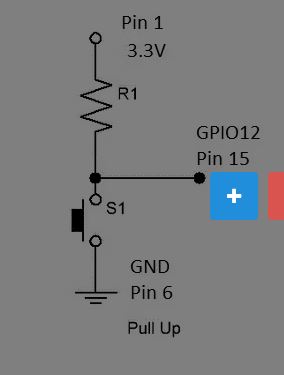
In order to record speech we use a push button connected to the Jetson Nano's pin 15. This code implements a button-triggered speech acquisition system using the GPIO (General Purpose Input/Output) interface on a Jetson Nano. It enables users to capture speech from a microphone connected to the Jetson Nano via a USB port. The microphone is integrated in the webcam. Upon button press, the code triggers speech capture, convert it to text.
GPIO Initialization: The code initializes the GPIO pins, setting the button pin (GPIO12) as an input and setting the initial state to 1 (released).
It is necesary a pullup resistance using the 40 pin header. We use Pin 1, 3.3V, pin 6 GND, a 1Kohm resistance and pin 15. This is the schema and the real implementation using a "hat" to plug in the Jeson Nano Pin Header. I have to use two 500ohm resistances.
Button Detection: The system continuously monitors the state of the button input. When the button is pressed, its state changes from the default value 1 to a value y 0. This transition in the button's state triggers the speech acquisition process.
Speech Acquisition: After detecting the button press, the system initiates the speech acquisition process using the microphone. It starts recording the user's speech and converts the recorded audio into text format using a speech-to-text engine or model.
In this section we use "openai/whisper-tiny.en" model that can be downloaded from https://huggingface.co/openai/whisper-tiny.en
Whisper is a pre-trained model for automatic speech recognition (ASR) and speech translation. Trained on 680k hours of labelled data, Whisper models demonstrate a strong ability to generalise to many datasets and domains without the need for fine-tuning. Whisper was proposed in the paper Robust Speech Recognition via Large-Scale Weak Supervision by Alec Radford et al. from OpenAI. The original code repository can be found here.
This checkpoint is an English-only model, meaning it can be used for English speech recognition. Multilingual speech recognition or speech translation is possible through use of a multilingual checkpoint.
To transcribe audio samples, the model has to be used alongside a WhisperProcessor.
The WhisperProcessor is used to:
- Pre-process the audio inputs (converting them to log-Mel spectrograms for the model)
- Post-process the model outputs (converting them from tokens to text)
Once downloaded the model works offline
ASR_MODEL_ID = "openai/whisper-tiny.en"
asr_model = pipeline("automatic-speech-recognition", model=ASR_MODEL_ID, device="cuda")Image Acquisition: If the user says "Take a photo, " the system initiates the image acquisition process using a webcam or a connected camera. The camera captures the current frame, which is then stored as a JPEG image file. After the image is captured, the system waits for the user to provide their speech input or query related to the image.
Once the desired image and the user's prompt have been obtained, the next step is to perform Visual Question Answering (VQA).
Visual Question Answering on Jetson Nano
To extract meaningful information from an image and answer user questions, we employ Visual Question Answering (VQA) using a multimodal model trained on a vast dataset of images and their accompanying descriptions.
vision_model = AutoModel.from_pretrained(VISION_MODEL_ID, trust_remote_code=True).to("cuda")
processor = AutoProcessor.from_pretrained(VISION_MODEL_ID, trust_remote_code=True)Given the limited resources of the Jetson Nano, we selected the uform-gen2-qwen-500m model from Hugging Face, optimized for resource-constrained devices. This small generative vision-language model comprises:
- A CLIP-like ViT-H/14 for image understanding.
- A Qwen1.5-0.5B-Chat model for language generation.
The model was pre-trained on an internal image captioning dataset and fine-tuned on public datasets like SVIT, LVIS, and VQA.
To ensure efficient execution on the Jetson Nano, we leverage PyTorch's torch.compile() function for Just-In-Time (JIT) compilation and optimization.
vision_model = torch.compile(vision_model) # Compile the vision model for better performanceThe multimodal model analyzes the captured image and user prompt, generating a detailed answer about the image.
After this piece of code we have the answer in text format.
Text-to-Speech Conversion
I attempted to utilize a Transformer model, specifically the "facebook/mms-tts-eng" model from Hugging Face (https://huggingface.co/facebook/mms-tts-eng), for text-to-speech (TTS) purposes. While the generated speech sounded more natural compared to the output from the pyttsx3 library, the model introduced a significant delay of approximately 30 seconds before processing the text input. In my opinion, the marginal improvement in speech quality does not justify the substantial waiting time of 30 seconds, making the pyttsx3 library a more practical choice for my use case.
So, to convey the answer to the blind user, we employ a text-to-speech (TTS) model, integrated into the Jetson Nano system. The TTS model converts the textual description into a natural-sounding spoken narration, which is then routed to a pair of headphones worn by the user. This audio output effectively translates the visual information captured in the image into an auditory representation, enabling the blind user to comprehend and interact with their surroundings more effectively.
In this part we are going to use pyttsx3. It is a text-to-speech conversion library in Python. Unlike alternative libraries, it works offline, and use a little resources.
Examining the commented code can provide a deeper understanding of how the program functions and the rationale behind each section.
System Integration and Usability
The entire system seamlessly integrates with the Jetson Nano, forming a compact and portable device that can be easily carried and utilized by blind individuals. The intuitive design and simple user interface make the system easy to operate, allowing users to focus on the information being conveyed rather than technical complexities.
It works offline, we don´t need any internet connection.
These are the components of the prototype:
- Battery
- Webcam with microphone
- Push button
- Bluetooth speaker
- Jetson Nano with a protective case
Evaluation and Future Directions
I have done some trials that I have save in the github repository, with the image, the question and the answer from the system.
As you can observe, the system is functioning correctly. Since English is not my native language, I am utilizing a text-to-speech program on another computer to communicate with the system during this trial.
To assess the effectiveness of our system, we will conduct a user study involving blind individuals. The participants will task with using the system to capture images and receive answers, and their feedback will be very important. The main point to evaluate will be expressed satisfaction with the system's accuracy, ease of use, and overall impact on their daily lives.
Future directions for this research include:
- Enhancing the multimodal model's ability to generate more nuanced and detailed answers of complex scenes.
- Integrating with other assistive technologies to provide a comprehensive suite of support for blind individuals.
By combining speech-to-text, image capture, visual question answering, and text-to-speech output, my system empowers blind individuals with enhanced visual perception, enabling them to interact with their surroundings more effectively and independently. I believe that this innovative approach has the potential to revolutionize the lives of blind individuals, providing them with a valuable tool for navigating daily challenges and enriching their experiences.
Using a Jetson model with more RAM, we could use a larger model with better results.
A live trial



{kind=link}
Comments
Please log in or sign up to comment.