

Hardware components | ||||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
 |
| |||||
 |
| |||||
The idea for this project is to create affordable and easy to set up touch interface on any flat surface. The project mostly uses commonly available items that most people should have access to. Main part of this project is "runtime" application that uses two neural networks: vision based and sound based. Vision based neural network is used to track pointer on the screen. Sound network is used to detect events such as knocking on screen that will be recognized as mouse click and scratching that will be recognized as moving cursor with left mouse button pressed.
Considering that the overall cost of this project is abysmal compared to commercialy available touch boards, I think that it can be used for educational purposes in poorer or developing countries. It also can be used to digitize content of traditional "analog" blackboard.
Sound Event Detection systemFor audio detection I've decided to use Convolutional based approach where input to the network is an audio spectogram of fixed time. Network will perform classification of such spectograms to detect three classes: Idle (nothing happens on touch screen), Knock (single left mouse click), Scrub (drawing) .
Dataset creation
To create the dataset I've written simple Qt application that allows to continously record audio samples, convert them to spectogram matrix as described here and save as images, plain text or numpy arrays (Yup, I could just follow the link step by step in Python and write GUI using PyQt but this was the first and last time that I wanted to play with matrix transformations using STL C++). The application is available here: Spectogram-Dataset-Recorder.
Considering my horrible reaction time I've decided to record frame samples at 8000Hz that are 350 milliseconds long (Final sampling perioid will be much shorter but I'll cover it later in the blog). In this project I've stuck with Mel scale filter banks rather than Mel-frequency cepstral coeffs as the network converged fast enough and provides nice accuracy of around 96% on testing dataset. For this project I've created 3000 samples for each class which were split as follows: 2500 for training and validation and 500 for testing. For recording I have used following parameters:
- Pre emphasis coefficient: 0.97
- Frame size: 25ms
- Frame stride: 10ms
- DFTs: 512
- Filter banks: 26
- Normalize: no (it provided a bit better results in noisy environment for some reason)
- Rescale: [0; 1]
Samples were exported to plain text format and read later using numpy's "loadtxt" function. Below you can see some samples of the dataset in jpg format.
It took me a bit more than two hours with breaks to create this dataset. Not bad but I probably probably looked like an idiot scratching and knocking my projector's screen for two hours.
Having dataset created it's time to play with network's architecture.
Network architecture
For the network's architecture I've considered three popular ones: CNN with 1D convolution, CNN with 2D convolution and CRNN with 1D convolution and GRU/LSTM unist that was based on these articles: [1] [2].. All three networks provided similar accuracy of around 95% - 96% after 100 epochs. Sadly, looks like that Tensorflow's recurrent layers aren't supported yet in Model Optimizer so I had to decide between two CNN networks. After some testing I've decided to stuck with CNN with 1D convolution as it required A LOT OF less params to train than 2D CNN and also behaved a bit better on testing data (difference of about ~0.5%). The input to the network is a two dimensional spectogram matrix with rows that decribe time, columns that describe frequency and every value describes amplitude of given frequency in given time step. Architecture consists of two Convolutional layers (Conv1D -> Batch Normalization -> MaxPool1D), Flatten layer, Dropout layer, three Dense layers and Softmax layer. Convolutional and dense layers have ReLU activation. Initially, The output is a vector with three values that classify given frame onto three mentioned above classes. Network was created using Tensorflow 2.0 in Python.
After training, the network is automatically passed through OpenVINO's Model Optimizer using this script:
def export_model(model, dir, filename):
model.save('model.tf')
os.system('%%INTEL_OPENVINO_DIR%%/deployment_tools/model_optimizer/mo.py --saved_mo del_dir model.tf -b 1 --output_dir %s --model_name %s' % (dir, filename))
shutil.rmtree('model.tf')neat!
Event detection in runtime
When I told you that I did all audio processing in C++ to challenge myself, well, I lied a bit. The truth is that I really wanted to try Inference Engine in C++ rather than in Python. To do this, I needed to obtain audio spectogram in C++ and here I had these options:
Run python script with calculations then save result in some shared memory (maybe txt file?). Thich is kinda stupid solution as I would slowly kill my hard drive and it would be too slow for this puprose as I would need to run the script from C++, wait for it to finish and use IO stream to read the spectogram.
The second option was to implement whole Python interpreteter in C++ code which is a bit of exaggeration for this project.
The third and chosen solution was to implement all matrix operations in C++ which is a bit of pain (and definitely there is library for this on github) but the result is really rewarding later. And if you peek inside source code of Spectogram-Dataset-Recorder and this project's you will see that I just reused AudioProcessor class.
To record sound from the enviroment QAudioInput was used with "audio/pcm" coding. Samples are stored in RAM memory in QBuffer so these can be accessed really fast.
To make sure that event detecion runs somehow in "real time", all required job was passed to separate thread using QThread to make sure that QAudioInput will work.
To make detection more responsible than once every 350ms. It was decided to use sliding window technique in which there is buffer with allocated memory for samples for 350ms but recording happens i.e every 50ms. When new recording appears, then first (oldest) data in buffer is removed and all other data is shifted to begining of the buffer so there is space for new samples.
There is still one problem with the network. When "knock" like signal appears in the window, it stays for whole window i.e 350ms. And you should trust me, that it's possible to fit more than one knock in this window. And we want to distinguish all of them. To overcome this, I've decided to set some oldest samples to mean amplitude in the window so those won't interfere with newer samples.
Whole procedure for event detection looks like this:
bool EventDetectorThread::runStep(){
// record audio
audioBuf.buffer().clear();
audioBuf.reset();
while(audioBuf.buffer().size() < bytesPerPeriod){
QCoreApplication::processEvents();
}
// transform buffer:
// slide it so there will be space for recorded audio
// insert recorded audio to buffer
// clear n first samples to "cheat" network so it will
// predict events on smaller window than sizeOfSlidingWindow
slideWindow();
insertSamplesToWindow();
// get spectogram of sliding window
MatrixMath::vec2d spectogram;
spectogram = audioProcessor.processBuffer(slidingWindow);
clearWindow(spectogram);
// make decision
bool ok = true;
vector<long double> res = networkRequest(eventDetectorNetwork, spectogram, &ok);
string state = networkResponseToString(res);
if(!ok){
error("Event detector crashed on network request.\n");
audioInput->stop();
return false;
}
// process decision
// eliminate noise from the network
// by looking at the previous result and state
// sometimes it happens that knock is detected between scrubs
// so we need to ignore any knock that happens just after successfully detected scrub
// we also need to detect knock only if transition knock -> idle is detected
// as it may happen that begining of scrub will be detected as knock
string result = "Idle";
if(state == "Scrub" || (state == "Knock" && previousResult == "Scrub"))
result = "Scrub";
else if(state == "Idle" && previousState == "Knock")
result = "Knock";
if(result != previousResult){
emit touchStateChanged(QString::fromStdString(result));
}
previousState = state;
previousResult = result;
emit spectogramUpdated(spectogram);
return true;
}For sliding window I've used following parameters:
- Window duration: 350ms
- Sampling period: 50ms (Single knock is around 40ms long)
- Clear window duration: 150ms (So only 200ms is used for classification)
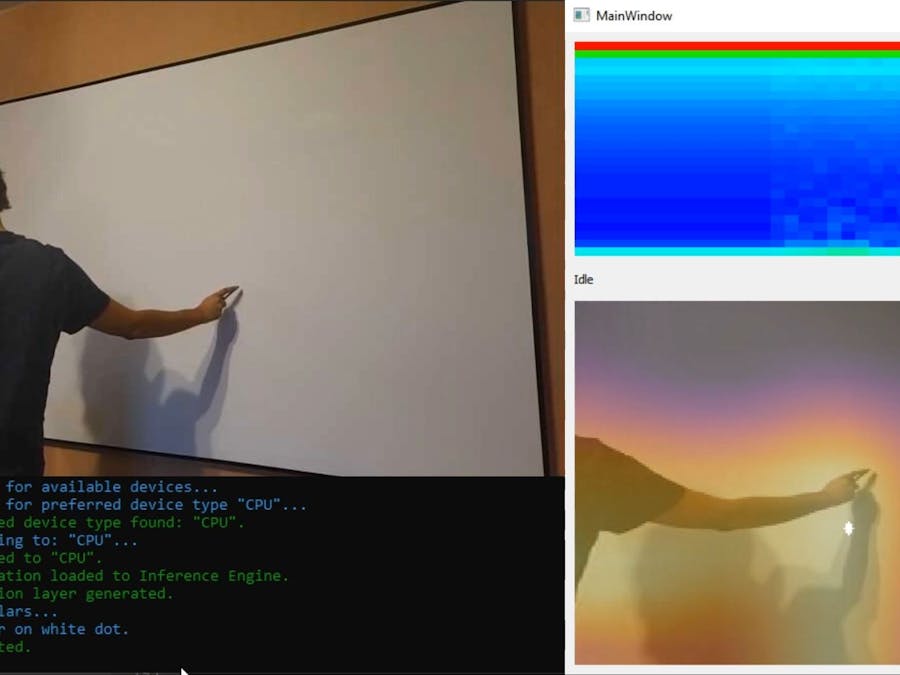
Here you can see how it looks live:
For cursor's detection system I've decided to use Fully-Convolutional Siamese Networks for Object Tracking as it is really lightweight and serves it purpose nicely.
Dataset
To train this network I've used a small part of ImageNet dataset and preprocessed it as it said in the network's whitepaper (Bounding boxes centered with some padding that if necessary is filled with mean RGB value of the picture). Not sure if I did it right tbh (I didn't) but I've splitted data like this: one frame as exemplar THEN next n frames as source images THEN next frame as exemplar etc... Then, during training I was using python's generator to retreive exemplar image and one random of frames assigned to it. Processed frame looks like this:
It took around ... nope! the script crashed after around 16 hours. Taught by experience, I have rewritten the script using multithreading to process all of the data faster and also made sure that dataset won't be overwritten after potential crash.
New script took like 8 hours to process everything. It's like 4 times faster than it would be using it's previous version. Finally I ended up with around 3.5 millions of images. Well there is no way that I would process all of this, so I've tried as much as I could. In the original paper authors took 50 epochs and 50000 exemplar - frame pairs and 8 per batch so I think that should be more than enough for this project. After a bit of training I have spotted one simple detail in whitepaper that I overlooked before: "Tracking through scale space is achieved by processing several scaled versions of the search image". Well, I did all the preprocessing for single scale so I had to do everything from scratch again...
After all ups and downs I've received nice dataset to train the network with. The next thing to do was to create tf.data.Dataset object from all of my data. This went rather smoothly as I just created generator to load file paths and weights for every video from structure.json and weights.json. To load images from given paths I've used .map() function to load images for batch using multiprocessing.
Network architecture
Architecture of this network is really intresting from the perspective of a person that takes it's first steps into deep learning. Basically, inputs (exemplar and source frame) are passed through one the same embedding function which in this case is fully convolutional, then result of both passes is convoluted (cross corelated really) again. In this convolution, the result of embedding with source frame is used as an input and the result of embedding with exemplar is used as a filter. This operation gives us Batch by Height by Width by 1 scores map that is used to decide where is tracked object (exemplar) on the picture. This score map is smaller than input frame so we need to resize it using OpenCV prefferably.
Training
To train the network, logistic loss was used as in the original paper. Full routine for creating such loss looks like this:
- Get radius r from the center of our source image to the farthest value of object's bounding box:
- Get stride k of the network (how much the network downscales the source image, in original example this will be 255/17 = 15)
- Create label matrix like score map (17x17 in original example) and for each cell:
1. Compute it's distance from the center and multiply it by k
2. If the distance is less than r then set it to 1, else set it to -1
@tf.function
def get_radius_from_center(x, y, center, stride):
x_with_offset = tf.math.add(float(x),0.5)
y_with_offset = tf.math.add(float(y),0.5)
x_distance = tf.math.subtract(tf.cast(center, tf.float32), x_with_offset)
y_distance = tf.math.subtract(tf.cast(center, tf.float32), y_with_offset)
x_vec_part = tf.math.pow(x_distance, 2)
y_vec_part = tf.math.pow(y_distance, 2)
distance = tf.math.sqrt(tf.math.add(x_vec_part, y_vec_part))
return tf.math.multiply(tf.cast(stride, tf.float32), distance)- Now, add cosine window to this matrix (to punish farthest detections form center even more) this window looks like this for 17x17 label matrix:
@tf.function
def get_cosine_matrix(shape):
cos0 = tf.convert_to_tensor(np.tile(scipy.signal.cosine(shape[1]), (shape[0], 1)), tf.float32)
cos1 = tf.convert_to_tensor(np.tile(np.transpose([scipy.signal.cosine(shape[0])]), (1,shape[1])), tf.float32)
return tf.math.multiply(cos0, cos1)- Multiply this matrix with sample's weight to make sure that sample videos with less samples will be equal to those with more samples
- Apply this function element wise to score matrix:
@tf.function
def get_loss_map(x):
sample = x[0]
pred = tf.math.divide(x[1], 1000) # change from original paper to prevent inf on tf.math.exp
max_radius = x[2]
weight = x[3]
stride = tf.math.divide(sample.shape[0], pred.shape[0])
center = tf.math.divide(pred.shape[0], 2)
shapes = [pred.shape[0], pred.shape[1]]
# construct raw loss map -1 if too far from center, 1 otherwise
loss_map = tf.convert_to_tensor([
[
1.0 if tf.less(get_radius_from_center(j, i, center, stride), max_radius)
else -1.0
for j in range(shapes[1])
]
for i in range(shapes[0])
], dtype=tf.float32)
# add cosine window to punish examples that are too far
# and reward those closer
loss_map = tf.math.add(loss_map, get_cosine_matrix(shapes)),
# apply weight to make sure that all video folders are treated equally
# and the network won't learn filters based on one dominating video folder
loss_map = tf.math.multiply(weight, loss_map)
# get logistic loss
loss_map = tf.math.multiply(loss_map, pred)
loss_map = tf.multiply(-1.0, loss_map)
loss_map = tf.math.exp(loss_map)
loss_map = tf.math.add(1.0, loss_map)
loss_map = tf.math.log(loss_map)
return tf.squeeze(loss_map, 0)- Reduce score matrix to scalar by computing mean of it
@tf.function
def logistic_loss_fn(samples, preds, radiuses, weights):
source_frames = samples[1] # only source frames are required to compute loss
radiuses = radiuses[1] # only radiuses of source frames are required to compute loss
losses = tf.map_fn(
fn = get_loss_map,
elems=(source_frames, preds, radiuses, weights),
fn_output_signature=tf.TensorSpec([None, None])
)
return tf.math.reduce_mean(losses), lossesThe training was a simple tensorflow's routine using GradientTape and checkpoints.
@tf.function
def train_step(inputs, radiuses, weights):
with tf.GradientTape() as tape:
preds = model(inputs, True)
losses, loss_maps = logistic_loss_fn(inputs, preds, radiuses, weights)
grads = tape.gradient(losses, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_loss_metric(losses)
train_acc_metric(preds, loss_maps)The training took around five days with breaks as sometimes I needed to use my PC and during training it behaved horrible due to high disk usage. For testing purposes I've created super simple script that loads newest checkpoint, takes input exemplar and frame, does detection and imposes network's prediction as heatmap on given image. Below you can see how the network behaved after around two days of training:
Well, it looks like it works decent, but the tests have shown that it's still not good enough during runtime. A bit more training should do the job.
Cursor tracking in runtime
After training I have exported Tensorflow's model to IR model, tried to load it into runtime application aaaaaand It looks like the cross corelation layer crashes the application. I have posted issue about it on Github and looks like architecture like this is not supported yet. Well, you should trust me that it was a bit of let down. Especially after n-th day of training. I've searched a bit for alternative library such as cppflow to only run the cross corelation layer, but then I've realized that OpenVINO is already built over such library called nGraph. And even better! I found out that I can create InferenceEngine::CNNNetwork object from nGraph function and use it through NCS2 or CPU! So I guess problem solved. After wrapping cross corelation into CNNNetwork my cursor tracking network is in reality made out of three subnetworks. The first two are embedding functions for exemplar and source frame exported to IR model from Tensorflow, and the third one is cross corelation layer generated directly in C++ code:
info(" - - Loading corelation layer to Inference Engine...\n");
// create inputs for cross corelation
info(" - - - Generating inputs to cross corelation...\n");
auto input = make_shared<ngraph::opset3::Parameter>(
ngraph::element::Type_t::f32, ngraph::Shape(getEmbeddingOutputDims(embeddingSourceSubnet)));
input->set_friendly_name("input");
auto filter = make_shared<ngraph::opset3::Parameter>(
ngraph::element::Type_t::f32, ngraph::Shape(embeddingDims));
filter->set_friendly_name("filter");
// conv layer
info(" - - - Generating cross corelation...\n");
std::shared_ptr<ngraph::Node> conv = make_shared<ngraph::opset3::Convolution>(
input->output(0),
filter->output(0),
ngraph::Strides({1,1}),
ngraph::CoordinateDiff({0,0}),
ngraph::CoordinateDiff({0,0}),
ngraph::Strides({1,1}));
ngraph::NodeVector ops = { input, filter, conv};
// validate
info(" - - - Validating cross corelation...\n");
ngraph::validate_nodes_and_infer_types(ops);
// create ngraph Function object from inputs and conv
info(" - - - Creating ngraph function...\n");
shared_ptr<ngraph::Function> ng_function = make_shared<ngraph::Function>(ngraph::OutputVector({conv}), ngraph::ParameterVector{ input, filter });
// create network from ngraph Function object
info(" - - - Creating network object...\n");
InferenceEngine::CNNNetwork net(ng_function);After loading the networks, the only thing to do is to connect them in serial. For this purpose I've decided to change default network's layout to NHWC and precision to U8 so it will be compatible with OpenCV Mat's "data" member. Finally, the only thing left was to create network request function. Considering that Mat objects can be pretty big and that this network should run as fast as possible, I decided to avoid copying. For this reason I've created blobs of data that point directly to Mat's "data" member:
cv::Mat PointerTrackerThread::networkRequest(const cv::Mat & sourceFrame, const EmbeddingBlob & filter){
// cross corelation
InferenceEngine::InferRequest xcorRequest = crossCorelationLayer.executableNetwork.CreateInferRequest();
// prepare inputs for cross corelation
xcorRequest.SetBlob("input", getEmbeddingBlob(embeddingSourceSubnet, sourceFrame));
xcorRequest.SetBlob("filter", filter);
// create empty score map
NetDims dims = crossCorelationLayer.outputInfo.begin()->second->getTensorDesc().get Dims();
cv::Mat res = cv::Mat::zeros(dims[2], dims[3], CV_32FC1);
// prepare output
InferenceEngine::TensorDesc resDesc (
InferenceEngine::Precision::FP32,
crossCorelationLayer.outputInfo.begin()->second->getTensorDesc().getDims(),
InferenceEngine::Layout::NCHW);
InferenceEngine::Blob::Ptr resBlob = InferenceEngine::make_shared_blob<float>(resDesc, (float*)res.data, dims[2] * dims[3]);
string outputName = crossCorelationLayer.outputInfo.begin()->first;
xcorRequest.SetOutput(InferenceEngine::BlobMap({{outputName, resBlob}}));
// do inference with cross corelation
xcorRequest.Infer();
return res;
}And here you can see that I don't copy any data, not even the output as it is directly feed to Mat object. Also you can see here that filter (aka result of embedding with exemplar) is passed as an argument to the request. That's because exemplars are generated and passed through the embedding only once, during startup of the application and the filters (blob pointers) are stored for the lifetime of the application. Now we don't need to do anything with exemplars anymore, and thanks to this it is possible to achieve more frames per second.
Whole procedure for cursor tracking is much easier than detector's as it only consists of loading frame from camera, performing convolution with all the filters and then rescaling score map to match screen's dimensions:
bool PointerTrackerThread::runStep() {
// do some initialization stuff
if(fstScan){
if(!finalizeSiameseNetwork())
return false;
fstScan = false;
}
// get new frame from camera
cv::Mat frame = accessCamera();
// ignore empties that may happen before camera initializes
if(frame.empty())
return true;
// transform perspective so blackboard is centered and fills whole frame
frame = warpPerspective(frame);
NetDims inputDims = getEmbeddingInputDims(embeddingSourceSubnet);
//resize frame to match network's input
cv::resize(frame, frame, {(int)inputDims[3],(int)inputDims[2]}, cv::INTER_CUBIC);
int cntr = 1;
cv::Mat scoreMap;
// get score map that is created from all partial score maps from all exemplar filters
for(auto & filter : exemplarFilters){
cv::Mat partialMap = networkRequest(frame, filter);
if(cntr == 1){
partialMap.copyTo(scoreMap);
}
else{
cv::addWeighted(scoreMap, (cntr-1)/(double)cntr, partialMap, 1/(double)cntr, 0, scoreMap);
}
cntr++;
}
// resize score map to match frame's size
cv::resize(scoreMap, scoreMap, frame.size(), cv::INTER_CUBIC);
// get cursor coords from score map
int x, y;
getCursorCoords(scoreMap, x, y);
int screenX = x*(double)(conf.screenWidth/(double)scoreMap.size().width)+1920;
int screenY = y*(double)(conf.screenHeight/(double)scoreMap.size().height);
emit cursorPositionChanged(screenX, screenY);
// generate heatmap for gui
cv::Mat heatmap = applyHeatmap(frame, scoreMap);
cv::circle(heatmap, {x, y}, 3, {255,255,255}, -1);
emit visualsChanged(heatmap);
return true;
}Camera input
To make sure that output from siamese network is correctly mapped to PC's screen I've written super small application to read my camera's input and fine tune cv::wrapPerspective function to correctly cut off unused parts of it.
Getting the exemplar
Getting exemplar images is as easy as it can get. During startup, there is message in command line "Place your cursor on white dot". Now you should place your finger on white dot that appears in the center of the preview in UI application. It'll wait 5 second, then will cut three exemplar images of different size. After this, the application will be ready.
The program itself
Well, I have shown most of the backend logic while describing both neural networks. So here I'll just describe how all of this is connected together. Firstly, you have probably spotted some strange "emit" stuff in C++ listings:
emit touchStateChanged(QString::fromStdString(result));
emit spectogramUpdated(spectogram);
emit cursorPositionChanged(screenX, screenY);
emit visualsChanged(heatmap);Those are special keywords used in Qt (basically core of Qt framework) that are used to communicate between different objects. In my case, GUI, tracker and event detector are different objects that also work in different threads. Using emit (aka signal & slot mechanic) I can easily communicate with all threads using Qt's event loop. So in my case every time spectogram was processed, the event was sent to GUI thread with new spectogram and new touch state using two emits. In pointer tracker, every time camera's frame was processed, the result was also sent using signal along with other signal that sends coordinates of the mouse. Connecting all of this I was able to emulate mouse behavior using only camera and microphone. To simulate mouse behavior I've used following scripts:
void MainWindow::changeCursorState(const QString & state){
ui->touchStateLabel->setText(state);
if(state== "Knock"){
INPUT Input={0};
Input.type = INPUT_MOUSE;
Input.mi.dwFlags = MOUSEEVENTF_LEFTDOWN;
SendInput( 1, &Input, sizeof(INPUT) );
ZeroMemory(&Input,sizeof(INPUT));
Input.type = INPUT_MOUSE;
Input.mi.dwFlags = MOUSEEVENTF_LEFTUP;
SendInput( 1, &Input, sizeof(INPUT) );
}
else if(state == "Scrub"){
INPUT Input={0};
Input.type = INPUT_MOUSE;
Input.mi.dwFlags = MOUSEEVENTF_LEFTDOWN;
SendInput( 1, &Input, sizeof(INPUT) );
}
else{
INPUT Input={0};
Input.type = INPUT_MOUSE;
Input.mi.dwFlags = MOUSEEVENTF_LEFTUP;
SendInput( 1, &Input, sizeof(INPUT) );
}
}
void MainWindow::updateSpectogram(const MatrixMath::vec2d & spectogram){
QPixmap spectogramPixmap = spectogramToPixmap(spectogram, ui->spectogramLabel->width(), ui->spectogramLabel->height());
ui->spectogramLabel->setPixmap(spectogramPixmap);
}
void MainWindow::changeCursorPosition(int x, int y){
QCursor::setPos(x,y);
}
void MainWindow::updatePreview(const cv::Mat & mat){
QPixmap heatmapPixmap = CvMatToPixmap(mat, ui->cameraView->width(), ui->cameraView->height());
ui->cameraView->setPixmap(heatmapPixmap);
}As you can see, those are really small and easy to understand functions. Below you can see how this works in real time:
On the video above you can see that event detector works great! Every time I knock on the board, "Knock" state is being detected and when I scrub, "Scrub" state is detected. The pointer tracker works not so good though. It roughly knows, where my hand is, but is prone to noise. I guess it happens due to image warping using OpenCV and maybe because score map is too small as you can see that the dot moves in some discrete steps. Also I guess that I've trained the network on not suitable data. Maybe I'll work on this later, but training this net on HDD was a bit of pain as most of the training time was spend for I/O access and my PC as unusable due to this.
How to run the projectFirstly, you should have OpenVINO installed with PATH variables set permanently.
Now, open Qt Creator and edit LIBS and INCLUDE fields in .pro files to point to your installations of OpenVINO and OpenCV.
To only run the project, build runtime application in Qt Creator in Release mode, then copy content of runtime_files to newly created folder. Now, run configurator application and select corners of your screen. Copy all of the values into xtl, xtl, xtr, ytr, xbl, xbl, xbr, ybr fields in config.json that was copied to newly created folder. The last thing to do is to change config.json depending on your setup. Especially "deviceName" field in eventDetector and "cameraId" in pointer tracker. Now you can run runtime application.
To play with this project, you need two datasets. The first one should be created using Spectogram dataset recorder and the second one should be ILSVRC2017_VID. To train event detector, just run train.py in event_detector folder with valid path to the dataset. This will export IR model to IR_model folder. To train pointer tracker, firstly run dataset_creator.py from pointer_tracker folder with valid path to ILSVRC2017_VID dataset. After dataset was created, just run train.py and export model using export_model.py. This will export IR model to IR_model folder. Now if you have built runtime application, simply copy content of both IR_model folders to build-runtime<some text> folder that should be available in runtime folder.
ConclusionsI have spent like a month (?) working on this project, but all I can say is that I had a lot of fun. And also learned a lot of new things about neural networks, especially about how all of this works under the hood, about different layers and topologies. Also I would never have guessed that it is so easy to integrate neural networks and hardware accelerators into C++ code.
Alternative project ideasI have also tought about these implementations:
- Only audio network(s) for X, Y microphones for position tracking of the cursor but:
- Not everybody has to two microphone ports in their PC
- It would require to label not only scratches and knocks but also it's positions over time and that would be painfull (especially for scratches)
- It would be more prone to environmental noise
- Using only SiamFC and get clicks and scratches from some designed for it device:
- It would be more expensive as it would require transmitter (pointer) and some receiver connected to PC
- It would provide latency
- It would run on batteries
- Audio network and two SiamFC networks to track cursor from both sides of the screen and use mean to get coordinates: I think this is really nice idea especially for tracking when a person covers the pointer with it's hand from one side. Sadly I don't have two USB cameras, two tripods and also really long USB extension cord for second camera to test it.




{kind=link}
Comments