





Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
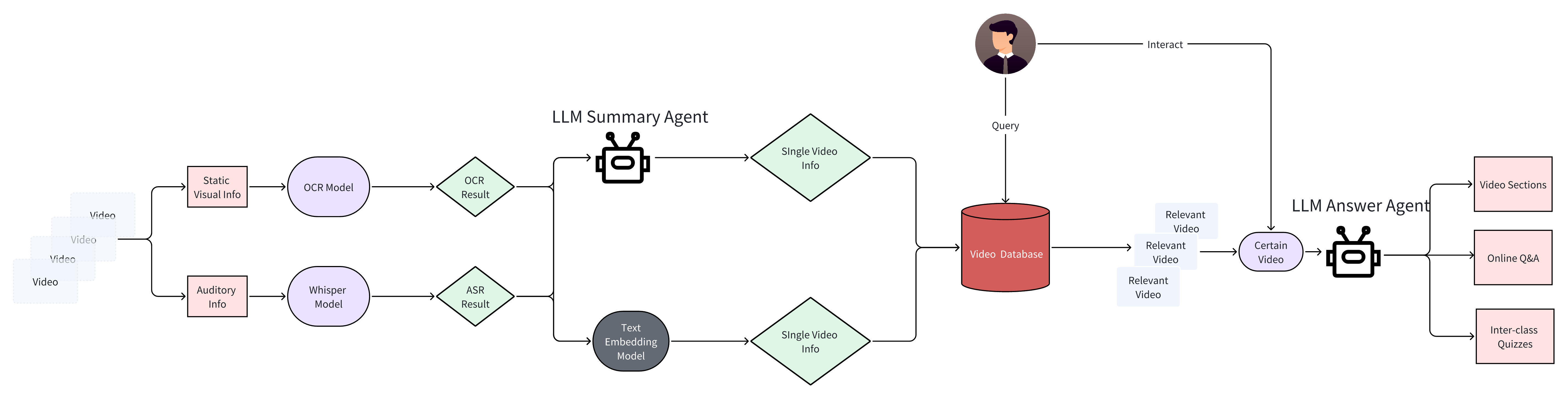
Online education has become an increasingly important form of education that cannot be ignored, as it allows people to have more free and accessible access to educational resources. We have designed an agent named VidMentor to help online teaching be more elastic, inclusive, and interactive. We use tools and models such as Llama3, Whisper, PaddleOCR, etc. and hardware powered by AMD to implement online Q&A, video segmentation, Inter-class quizzes, hoping to expand the functionality and effectiveness of online education
The UM790 Pro is equipped with a powerful AMD Ryzen 9 7940HS CPU and Radeon 780M Graphics APU, complemented by 32GB of RAM. It runs on the Windows 11 operating system, making it an excellent choice for local AI model deployment.
Code Framework├── 📂 checkpoints #save model checkpoints
├── 📂 videos #save all origin videos
├── 📂 asset #save necessary files
├── 📂 backend
│ ├── 📄 backend_audio.py #extract audio info into database
│ ├── 📄 backend_search.py #support search and answer in website demo
│ ├── 📄 backend_visual.py #extract visual info into database
│ ├── 📄 backend_llm.py #support building llm agents
├── 📂 database #save all video's data
├── 📂 utils
│ ├── 📄 tamplate.py #provide different tamplates for llm agents
│ ├── 📄 trees.py #provide tools to generate mind map
│ ├── 📄 utils.py #provide some useful common tools
├── 📂 models
│ ├── 📄 bgemodel.py #bgemodel method
│ ├── 📄 llm_model.py #llm model method
│ ├── 📄 whisper_model.py #whisper model method
│ ├── 📄 keybert_model.py #keybert method
│ ├── 📄 punctuator_model.py #punctuator model method
├── 📄 README.md #readme file
├── 📄 TUTORIAL.md #tutorial for vidmentor
├── 📄 requirements.txt #packages requirement
├── 📄 st_demo.py #run streamlit website demo
├── 📄 download_ckpt.py #download all model into local
├── 📄 build_database.py #build database- Prepare Environment
Create Conda Environment
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://github.com/Kailuo-Lai/VidMentor.git
conda create -n vidmentor python=3.9
conda activate vidmentor
cd VidMentor
pip install -r requirements.txtInstall Graphviz
1. Downlowd Graphviz from Download | Graphviz.
2. Add Graphviz to your system path.- Download Models
Download Model Weight
python download_ckpt.pyLLM Quantization
1. Build llama.cpp from llama.cpp/docs/build.md at master · ggerganov/llama.cpp (github.com)
2. Quantize the llama3 weight in the checkpoints folder following the instructions from llama.cpp/examples/quantize/README.md at master · ggerganov/llama.cpp (github.com)
3. Change the argument --llm_version in st_demo.py and build_database.py to the output file name of the quantized llama3 weight.- Build Database
Upload video into videos dir
python build_database.py- Run Streamlit Demo
streamlit run st_demo.py- Mind Map
1. Summarize the ASR results of individual videos using LLM to generate a summary text in markdown format.
2. Based on the markdown formatted summary of individual videos, draw mind maps using the Graphviz library.
3 . Utilize text embeddings to recall key points corresponding to ASR segments, achieving video segmentation based on key points.
- Multi-video Retrival
1. We use LLM to get summaries of videos with special prompt.
2. We get embedding of summaries by using BGE Mode.
3. Compute cosine similairty between user's input and summaries.
- Single-video Q&A
1. Use embedding to get reference from original model information.
2. Get answer with reference by using LLM.
3. Get answer without reference by using LLM.
4. Merge the answers above by using LLM.
Program Demonstration- Search and retrieval video
We hope that VidMentor is sufficiently intelligent—this intelligence will be demonstrated from the very beginning, in addressing the question of what videos the user actually needs to learn. We will return the most relevant videos from our extensive video library based on the user's needs, and all the user needs to do is enter their question into the search box.
- Watch & Interact with videos
Mind mapping & Video segmentation
Mind mapping is key to understanding and organizing knowledge points. We aim to help users extract key points from videos and construct mind maps to aid understanding; video segmentation allows users to freely jump to video segments corresponding to specific knowledge points, saving time in searching for relevant segments.
Real-time interaction
One of the biggest drawbacks of online learning is the lack of interaction. We want to provide users with an interaction experience similar to offline classes while they watch videos. We use LLM to simulate the role of a teacher, allowing users to ask questions in real time and get answers just like they would from a professor—this is the core value of this real-time interaction module.
We offer the following two interaction modes:
- Keywords
We hope to make this interaction more intelligent—it can intelligently extract key points from every frame of the video, allowing users to select the content they wish to understand more deeply when using it.
- Q&A
We also maintain a certain degree of freedom—regarding any whimsical questions you might have, you can choose the questioning mode to obtain the answers you seek.
- In-class Quizzes
Testing is one of the best methods to consolidate knowledge. Therefore, for each section of every video, we have used a LLM to generate some high-quality questions—this may greatly enhance the learning effect.
Starting from the enhancement of freedom and intelligence in online education, we have constructed a video understanding agent named VidMentor using tools such as Llama3, Whisper, and PaddleOCR, hoping to expand the functions and effects of online education. Compared to traditional teaching video comprehension, VidMentor can handle an entire series of educational videos, facilitating a comprehensive understanding of the whole subject for users. Additionally, VidMentor is equipped with functions such as online Q&A, video segmentation, and classroom quizzes, which help users understand from the basics to the more complex, simulating the scenario of offline teaching.
{kind=link}

Comments
Please log in or sign up to comment.