


Hardware components | ||||||
 |
| × | 1 | |||
My journey to creating BitMind begins with a wave of nostalgia. As a lifelong gamer, I fondly remember the days of physical game guides filled with their beautiful maps, character profiles, and meticulously detailed walkthroughs.As gaming evolved, so did the way we access information. Online wikis and forums replaced physical guides, offering vast yet often unorganized repositories of knowledge. Yet, I find myself missing the personal touch of those old guides.
The idea for BitMind struck during a frustrating gaming session, when I wished for a more efficient way to access game information. I realized there was an opportunity to combine the comprehensive knowledge of online resources with the accessibility of a knowledgeable gaming companion.
BitMind aims to bridge this gap, offering an AI assistant that provides instant, tailored guidance for gamers. It's designed to streamline the information-seeking process, allowing players to focus on what matters most – enjoying the game.
ConceptBitMind's initial concept focused on efficiency and user-friendliness. I created a wireframe model to visualize these core principles before implementation. The concept features an AI assistant that integrates seamlessly with games, offering voice-activated queries, on-screen overlays, and personalized recommendations. A modular design allows for game-specific knowledge packs, ensuring adaptability across various gaming titles and genres. This approach aims to provide instant, relevant information to players while maintaining a non-intrusive and intuitive user experience.
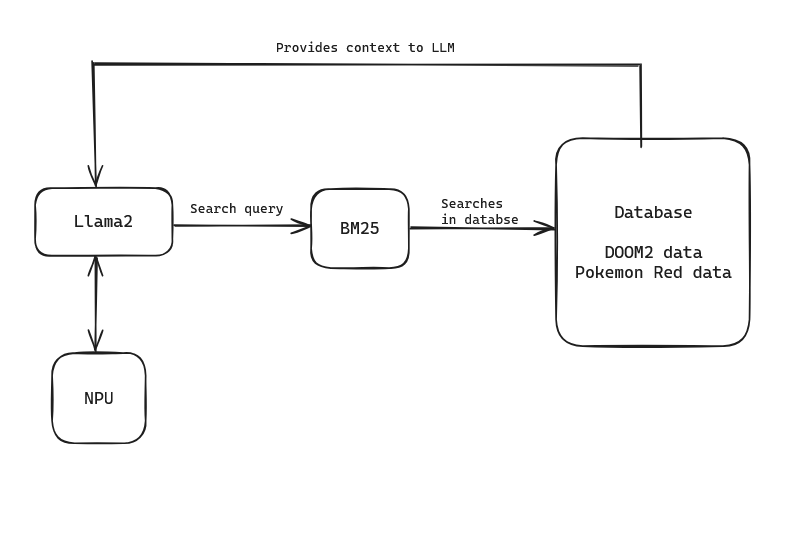
A pivotal aspect of BitMind's development was leveraging the NPU in the AMD AI hardware, which dramatically accelerated our AI processes compared to a standard CPU-based approach.
Some NPU specific aspects that helped the code were -
- The code replaces standard linear layers with quantized versions, which can significantly speed up computation on NPU hardware.
Utils.replace_node( model,
WQLinear,
qlinear.QLinearPerGrp,
(), {'device':'cpu', 'w_bit':args.w_bit, 'group_size':128} )- The code applied AWQ, which is a quantization technique that can significantly reduce model size and increase inference speed on NPU hardware.
if args.awq != "none":
for n, m in model.named_modules():
if isinstance(m, qlinear.QLinearPerGrp):
print(f"Preparing weights of layer : {n}")
m.device = "aie"
m.quantize_weights()- The code also replaced the standard attention mechanism with a Flash Attention implementation, which is typically much faster on NPU hardware.
if args.flash_attention:
from llama_flash_attention import LlamaFlashAttention
node_args = ()
node_kwargs = {
'config': model.config,
'llama_name': "llama-2-wts-hf/7B_chat",
'flash_config_path': "../../ops/python/llama_flash_attention_config.json",
'device': "cpu", # args.target
'max_new_tokens': 11,
'quant_mode': "awq"
}
Utils.replace_node( model,
LlamaAttention,
LlamaFlashAttention,
node_args, node_kwargs)The integration of the NPU not only sped up our processes significantly but also allowed for more ambitious AI features in BitMind.
The development of BitMind presented a series of complex challenges. One of the most significant hurdles was the incompatibility issues between various packages, which prevented the use of a traditional RAG system. To overcome this obstacle, I implemented an alternative approach using the BM25 algorithm for information retrieval. Here's a brief overview of the process:
- Tokenizing the query and getting scores
bm25 = BM25Okapi(tokenized_corpus)
tokenized_query = preprocess_text(query)
scores = bm25.get_scores(tokenized_query)- Retrieving top-k relevant passages
top_indices = scores.argsort()[-top_k:][::-1]- Constructing the relevant passages
relevant_text = ""
for i in top_indices:
if len(relevant_text) + len(paragraphs[i]) <= max_chars:
relevant_text += paragraphs[i] + " "
else:
remaining_chars = max_chars - len(relevant_text)
relevant_text += paragraphs[i][:remaining_chars] + "..."
breakAs I wrap up this project, I can't help but feel a sense of excitement and accomplishment. We've successfully harnessed the power of the LLaMA2 model, combined with the precision of BM25 retrieval, to create a text generation system that truly shines. The results speak for themselves – our system is capable of producing contextually relevant and accurate responses that have the potential to revolutionize the way we interact with games. I'm deeply grateful to AMD for their generous support and provision of cutting-edge hardware. Without the blazing fast inference speed of the NPU this project would not have gone as easily as it went.





{kind=link}
Comments
Please log in or sign up to comment.