





Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
 |
| |||||
 |
| |||||
Background: Liver cancer has globally become 6th incidence rate and 2nd mortality rate in all categories of cancers, which severely threatens human health [1]. In clinic, acceleration of comprehending accurate tumor anatomy from medical scans benefits diagnosis, organ surgery planning, treatment planning and post-treatment evaluation, whereas this requires precise manual delineation from radiologists. To reduce their workload, the artificial intelligence (AI) embedded tool provides a rapid solution that substantially boosts the inference of liver tumor by means of semantic segmentation, ultimately illustrating pixel-wise lesion mask on the given medical images. However, static computer-assisted diagnosis (CAD) tool built on AI inference usually hinders the model from generalizing to various clinical scenario and interpreting the resulted masks. Human-AI interactive diagnostic system adjusts expected lesion features with inputting radiologist expertise in real time, which can ensure the system robustness and interpretability.
Challenges: Human-AI interactive diagnostic system may be sub-optimal to deploy on current computer-assisted diagnosis (CAD) systems due to high latency and low throughput issues. The CAD systems adopt a cloud-client architecture with Ethernet for communication, in specific, implementing medical data storage/AI analysis on cloud and medical data import/display on client. Such an architecture may have less potential for developing a real-time application on interactively annotating liver tumor since the Ethernet communication (approximately 12MB/s throughput) becomes the bottleneck of system when we mutually transfer data between cloud and client in high frequency.
Aim: In this project, we aim to design the prototyping system, i.e. Human-AI Interactive Diagnostic system on an Edge computing device (HIDE) for liver tumor segmentation. Instead of the conventional cloud-client architecture, we integrate the main workflow of HIDE onto a single Field Programmable Gate Array (FPGA) board, named AMD-Xilinx Kria KV260 Vision AI Starter Kit, attempting to establish the functions of interactive data and annotation import, data storage, AI inference and output image visualization. We further estimate model performance and power consumption to understand additional benefit of our prototyping system.
Approach: The HIDE system is comprised of Host and Edge parts: The Host device is an Nvidia GPU server that installs the Vitis AI platform for directly translating the Tensorflow- or PyTorch-based deep learning programs for Deep-Learning Processor Unit (DPU) on Edge device. In specific, we train the deep learning segmentation network U-Net on Tensorflow GPU, and then it goes through Quantization Aware Training (QAT) and compiling to compress the GPU model weights that suits DPU computing. On the other hand, the KV260 platform composes the Edge device that includes the sensing-storing-computing function into the diagnostic pipeline. First, KV260 uses the smartcam module to acquire medical images and interactive annotations. Followed with pre-processing steps to have tumor region-of-interests (ROIs), we deploy the compiled DPU model at Host onto the KV260 FPGA. The included Vitis AI Runtime Engine with its Python API communicates with the DPU via an embedded Linux on the FPGAs microprocessor. To compare performance of the HIDE system with that of the Host solution, we finally assess the Dice score for segmentation metric as well as runtime, power consumption, and throughput for system indices.
Take-home: The KV260 board plus Vitis AI platform provide a rapid solution for interactive diagnostic system to proactively solve practical challenges. Through our developing experience, the best benefit is that our AI engineers/scientists can parallelly translate the GPU-based deep learning solution onto KV260 without much knowledge of FPGA computing. From our point of views, the advantages of KV260, i.e. low latency, high throughput and low energy cost, have great potential to become a famous pre-business platform for lightweight AI application before production.
Technologies Used- Vitis AI: The Vitis AI platform provide advance Application Programming Interface (API) that accelerates AI inference on AMD-Xilinx FPGA evaluation boards and platforms. Optimized IP cores, tools, libraries, models, and example designs have integrated in Vitis AI development tools. The Vitis AI development environment does not required any specific FPGA knowledge and with few additional steps, the AI developers can deploy deep-learning applications onto FPGA evaluation boards and platforms. In this project, we majorly employ the quantization, compiling, and profiling modules in Vitis AI.
- Xilinx Kria KV260 Vision AI Starter Kit: Fig.1 illustrates the components of KV260: the K26 system-on-module (SOM), carrier card, and thermal solution. The SOM has silicon device, memory, boot, and security module. In addition, this kit provides various interfacing options and includes a power solution and network connectors for camera, display, and microSD card. The thermal solution has a heat sink, heat sink cover, and fan. As it is said in the official document, the Kria KV260 Vision AI Starter Kit is designed to provide customers a platform to evaluate their target applications and ultimately design their own carrier card with Xilinx K26 SOMs. Whilst the Kria KV260 Vision AI Starter Kit include smart city and machine vision, security cameras, retail analytics, and other industrial applications, we develop our own semantic segmentation model with customized options.
Our novel Human-AI Interactive Diagnostic System on an Edge Computing Device (HIDE) system aims to embed the sensing-storing-computing-integrated KV260 platform into the radiologist's diagnostic pipeline. It realizes accurate segmentation with manually interactive inference, which has high throughput and low latency. The workload of AI model training and quantization compression is transferred to the host asynchronously, and the model on edge is updated periodically. The detailed description of our workflow is as follows:
Diagnostic pipeline in radiological department (blue area in Fig.2):
1. Liver cancer patient undergoes an abdominal CT scanning.
2. CT scans are printed out or digitally archived on the cloud server.
3. Radiologists annotate liver tumors with semantic annotations and evaluate the state of liver cancer using the standard RECIST protocol.
Human-AI interactive edge computing that further enables precise detection (yellow area in Fig.2):
1. The KV260 platform can use smartcam to acquire medical images derived from the different media, such as clinic paper report, monitor, tablet, smart phone, projector, etc.
2. The KV260 platform can pre-process CT scans together with semantic annotations to navigate to the tumor ROIs.
3. The KV260 platform can perform efficient deep learning model using FPGA to locally infer precise segmentation mask for sufficient advice for diagnosis and surgical or radiotherapy planning.
Vitis-AI Program that builds the HIDE system (pink area in Fig.2):
1. On GPU server (or host), engineers train a deep learning-based segmentation model using Tensorflow framework.
2. Vitis AI development environment quantizes the float32-type model into the INT8 type during quantized aware training (QAT), ultimately reducing the model size.
3. Vitis AI development environment enables compiling the quantized model into KV260-deployable model.
Dataset DescriptionIn our case, we utilize the ISBI LiTS 2017 Challenge dataset for liver tumor segmentation, which contains 131 contrast-enhanced 3D abdominal CT scans with different sizes. We further divide the dataset into a train set and a test set. The train set contains 103 volumes while the test set contains 28 volumes. The dataset can be found here.
Regarding Response Evaluation Criteria in Solid Tumors (RECIST) [2] , many investigators, cooperative groups, industry and government authorities have adopted these criteria in the assessment of treatment outcomes. In clinical practice, radiologists usually follow RECIST to mark the longest diameter and the perpendicular counterpart of the tumor in its significant slice (the axial slice with the largest tumor area), and assess the tumor size further. The RECIST-mark used in our project are lesion diameters which consist of two lines, one measuring the longest diameter and the second measuring its longest perpendicular diameter in the plane of measurement [3]. Samples of the lesions and RECIST-marks can be found in Fig.3.
- An Ubuntu 18.04 host server.
- Nvidia GPU driver and CUDA 11.4.
- Vitis AI docker miller: xilinx/vitis-ai:latest. (For GPU version, please read the official documentation for details)
- Install additional python packages (scikit-image, opencv-python, etc.) to the
vitis-ai-tensorflow2environment.
The first step is to train a DNN model for liver tumor segmentation from scratch in the cloud. Specifically, we input a liver abdominal CT with RECIST-marked tumor, and output the pixel-wise segmentation results of tumor. Here, we choose the widely-used U-Net segmentation model with 0.49M parameters based on the public available tensorflow-2.6.0 framework. The input images have the size of 256x256x4.
1. Train the UNet segmentation model:
python ./code/train.py2. The trained network is converted to the format of H5, which is named as float_model.h5:
model.save(os.path.join(base_path, model_name+'/float_model.h5'))The 32-bit floating-point weights and activations to 8-bit integer (INT8) format to reduce computing complexity. We quantize the DNN model by employing the Quantization Aware Training (QAT) approach which can further improve the accuracy of the quantized model. You can directly run the script:
python QAT_unet.pyWe also itemize the main step in the vai_q_tensorflow2 API for better understanding:
1. Preparing the Float Model (float_model.h5) obtained in Step.1, training dataset with labels, Calibration Set (calibration dataset) which is a subset of the training dataset to represent the input data distribution and training script.
calib_dataset = load_calib_data(data_path=data_path)2. Quantizing the model:
Load float Model:
model = unet(input_size=(256, 256, 4))
model.load_weights(model_path, by_name=True)Do init PTQ quantization with calibration dataset first to help get a better initial state for the quantizers:
calib_dataset = load_calib_data(data_path=calib_path)
quantizer = vitis_quantize.VitisQuantizer(model, '8bit_tqt')
qat_model = quantizer.get_qat_model(
init_quant=True,
calib_dataset=calib_dataset,
include_cle=True,
freeze_bn_delay=1000)Train and get the quantize finetuned model:
qat_model.compile(
optimizer=opt, loss={'quant_conv2d_23_sigmoid_sigmoid': dice_coef_loss},
loss_weights={'quant_conv2d_23_sigmoid_sigmoid': 1},
metrics=[dice_coef, lr_metric])
qat_model.fit_generator(generator=trainGene,
steps_per_epoch=int(5000 / batch_size),
epochs=50, validation_data=devGene,
validation_steps=40, verbose=1,
callbacks=[csv_logger])3. Saving the quantized model:
quantized_model = vitis_quantize.VitisQuantizer.get_deploy_model(qat_model)
quantized_model.save(os.path.join(base_path, model_name, 'quantized.h5'))4. Evaluating the Quantized Model:
We replace the float model file with the quantized model in the evaluation script and evaluate the quantized model just as the float model:
python ./evaluation/predict_quantised_unet.py
python ./evaluation/cal_metrics_seg.pyThe evaluation results are shown in Table.1 and Fig.5.
Step 3 on Host: Compiling DNN Model to xmodelSince we are going to embed the model onto a DPU, we need to map the network model to a highly optimized DPU instruction sequence. Specifically, we input the quantized_model.h5 obtained in Step.2 and the arch.json which is a configuration file generated during the Vitis flow. Then, we can obtain a compiled model named compiled_model.xmodel.
Compiling for DPU
vai_c_tensorflow2 -m ./quantized_model/quantized_model.h5 \
-a /opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.json \
-o ./compiled_model/ \
-n unet_compiled- Flash the petalinux into SD card using Balena Etcher.
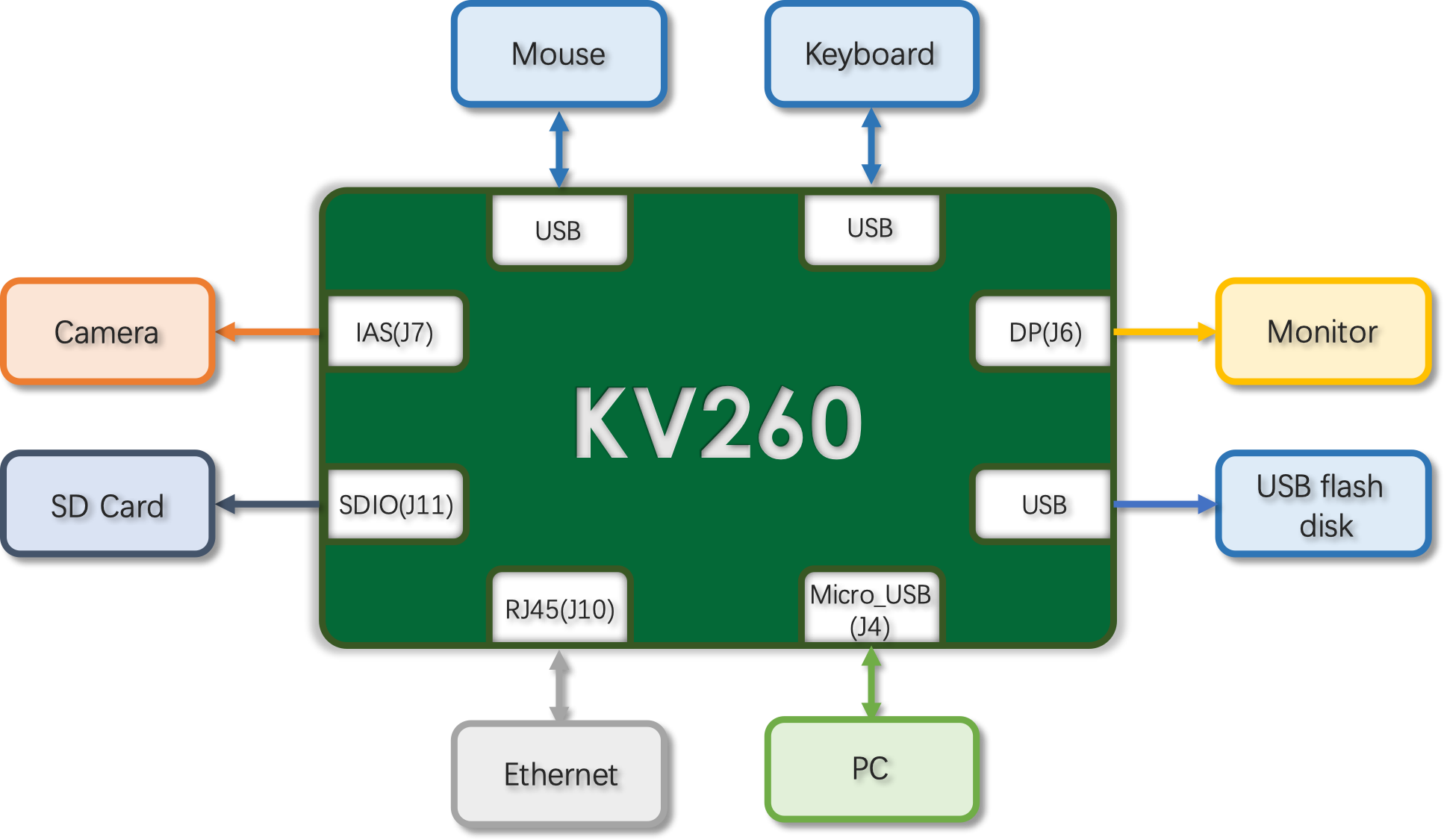
- Interface access for the KV260, e.g. SD (J11), micro-USB (J4), IAS (J7), Ethernet (RJ45) in Fig.4.
- Set user password:
sudo su -I root- Internet access for the KV260:
ping 8.8.8.81. The camera interface is an important part in our project. This requires installing the Smart camera app (smartcam).
1) Obtain the smartcam application package:
sudo xmutil getpkgs2) Install the smartCam accelerator package:
sudo dnf install packagegroup-kv260-smartcam.noarch3) View available application firmware on the system:
sudo xmutil listapps4) Uninstall the default KV260-DP application:
sudo xmutil unloadapp5) Load the smartcam accelerator firmware:
sudo xmutil loadapp kv260-smartcam2. Print the CT image and focus the camera:
Fix the printed CT image and turn on the camera to display the image on the screen:
sudo smartcam --mipi -W 1920 -H 1080 --target dpMove the camera to focus until a clear CT image is captured and then fix the camera.
3. Mount the USB:
1) Create a USB drive folder:
mkdir /mnt/usb2) Mount the USB in root mode:
mount -t vfat/dev/sda1/mnt/usb4. Use Smartcam to collect images and store them in USB:
sudo smartcam --mipi -W 1920 -H 1080 --target file5. Use FFMPEG application to segment the collected video stream into pictures:
ffmpeg -r 30 -i /mnt/usb/out.h264 -f image2 /mnt/usb/%03d.jpegHere, we aim to produce region-of-interest (ROI) along with the interactive annotation mark from practitioner, given the medical images scanned by the smartcam. This can be successfully implemented by OpenCV in Python.
The raw abdomen images should go through image warping and cropping process to have orthogonal rectangular view, and next practitioner can interactively annotate with a simple cross to emphasize tumor shape and location. In specific, the following steps are required to perform:
1. Read and resize the raw images.
2. Convert the color image to grayscale.
3. Use Canny function to detect edges in the grayscale.
4. Find the contour that have largest area and longest length.
5. Find and back translate the four vertices matching the original image resolution.
6. Performance four-vertex perspective transform to have rectangular view.
7. Interactively annotate lesions by drawing long and short axes.
8. Crop lesion ROIs of the size 256*256 which can include the long and short axes of lesion.
All the above processes have been integrated in a jupyter notebook, hence go to its directory, input jupyter notebook and then enter pre-process-scan.ipynb to see the details.
1. We need to first deploy the model files trained on host, script files and scanned CT images to the KV260 platform, and run the test model:
python3 app_mt.py2. Monitor metrics such as throughput and runtime:
python3 -m vaitrace.py app_mt.py3. Monitor the power computation of running test model:
xmutil platformstats -pIn this project, we use two benchmarks to evaluate our method, according to two famous challenges: 2021 Mobile AI Workshop Challenge and 2021 Low-Power Computer Vision Challenge (LPCVC).
The first benchmark TotalScore1 is the Dice Coefficient (Dice) to evaluate the segmentation performance, which can be formulated as:
where Seg is the segmentation result and GT is the ground truth.
The second benchmark TotalScore_2 consists the power of system, Dice and throughput, which can be formulated as:
where baseline_Dice=0.6. The above two benchmarks can be calculated by:
import numpy as np
def total_score1(seg, gt):
inter=(seg.astype(np.int)>.astype(np.int)).sum()
dice=2*(inter/(np.sum(seg)+np.sum(gt)))
return dice*100
def total_score2(power, runtime, dice, throughput, base_dice=0.6):
def relu(x):
if x > 0:
return x
else:
return 0
energy = power * runtime
score = 1.0 * 1e4 / energy * relu(dice-base_dice) * throughput
return scoreFinally, we report the benchmark results (in Table.1) and illustrate the segmentation visualization results (in Fig.5) of reduced U-net architecture on host and on edge, respectively.
KV260 is an advanced visual application development platform with unparalleled AI performance, preset hardware acceleration and adaptation to future sensor changes. This project successfully designs a HIDE system, which applies the KV260 platform to realize a computer-assisted liver cancer diagnosis. It opens the field for broad applications in the medical diagnostic system on Edge device. Our experimental results show the model inferred on Edge can preserve the comparable performance on Host but substantially improve the system efficiency and reduce power consumption.
This project is not limited to liver tumor segmentation and U-Net architecture. With some tinkering it should be possible to perform tumor detection and diagnose and also suitable for wider range of medical images such as MRI or B-mode ultrasound.
Feel free to fork our GitHub repos and do some awesome things yourself!
References[1] J. Fu and H. Wang. “Precision diagnosis and treatment of liver cancer in China.” Cancer letters 412, 283-288, 2018
[2] E. A. Eisenhauer et al., “New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1),” Eur. J. Cancer, vol. 45, no. 2, pp. 228–247, 2009.
[3] Y. Zhang, et al. "DeepRecS: From RECIST diameters to precise liver tumor segmentation." IEEE Journal of Biomedical and Health Informatics, 2021.
AcknowledgmentWe thank ISBI LiTS 2017 Challenge for providing the liver tumor dataset. Thank AMD-Xilinx for offering KV260 AI starter kit for the secondary development of the prototype. We also feel great thanks to the git repos DeepRecS and document scanner for accelerating our software development.

{kind=link}
{kind=link}




Comments
Please log in or sign up to comment.