



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
While playing a recent video game I found myself visually disoriented after launching a specific powerful attack. To my surprise my friend did not have this experience. Curious, I utilized a video frame grabber to record gameplay. I found the game output 6 display frames of full-screen white flash animation when activating the move. I did not even recognize the flash, but my eyes and occipital lobe (brain) were overwhelmed with the stimulation.
I wanted to create a "selective filter" to edit the video frames in real time. Although I was successful in making the filter using color space conversion and applying thresholds, the filter was applied to a lot of material that did not need adjustment. Ultimately I found detecting the problem material was actually very difficult by hand. I need to detect content like a 'flash' to know when to apply the filter and when to release it. It is easy enough to detect a near full-screen bright white flash, but I would like to be able to detect and modify many other different types of effects. A trained AI classification model has the potential to perform well on many types of content: movies, games, as well as user generated content like shared videos.
This is the idea for the Datacenter AI Adaptive Computing challenge: Utilize deep learning engine AI to detect sudden 'bright' effects in video material so it can be modified by an adaptive threshold filter. In a mature implementation the full engine would utilize AI detection running alongside an adaptive filter, and could be deployed by any content delivery service to enable on-the-fly modification to photosensitive viewers without any need to store adjusted content.
- Hardware target : VCK5000-ES1 AI engine with DPU shell 4.4.6 deployed, in full PCIe3.0 x16 slot
- Docker container running Xilinix Vitis-AI 1.4.1 (CPU build).
- Clone Vitis-AI-Tutorials (specifically Design tutorials #12)
- PC system used : AMD Ryzen9 PC with basic GPU, recommend a healthy amount of usable disk space, maybe 1TB for a project like this.
- Ubuntu 20.04 with Kernel downgrade to 5.8.0.43 (for compatibility with VCK5000 drivers, completely remove all other kernel versions or driver install will detect them and fail)
- Follow Xilinx published instructions to install VCK5000 on base machine and drivers
- Pull down Xilinx tools and set up our container
git clone -b 1.4.1 --recurse-submodules https://github.com/Xilinx/Vitis-AI
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI-Tutorials
cd Vitis-AI
docker pull xilinx/vitis-ai-cpu:latest
./docker_run.sh xilinx/vitis-ai-cpu:latest- Finally, confirm you have a working X11 environment by following the setup instructions for your environment. X11 allows the docker container to display images and video on the host machine GUI environment.
- For additional information on debug tools, see final section of this document.
- VCK5000 runs 2 drivers on the PC (host): xclmgmt and xocl.
- Base AI models for different toolchains can be found on
Vitis-AI/models/AI-Model-Zoo/model-list/ - From folder name you can infer quite a lot of information. Example: tf2_resnet50_imagenet_224_224_7.76G_1.4 : TensorFlow2 framework, ResNet50 classifier from ImageNet, input size 224x224, with 7.76Gflops performance, version 1.4
- To download the actual model, view the model.yaml file in the folder with a text editor to find an https:// download link for your target device (VCK5000-ES1). The yaml file serves as a sort of 'look up' catalog for the zoo. Models are quite large, the ResNet50 is 180MB, that is why they are not included directly with the container.
- The DPU is the 'Deep Learning Processor Unit' for VCK5000. Our DPU and shell will have this notation: 'DPUCVDX8H' - this name is described in Xilinx UG-1414 as: CNN, Versal DDR with AIE&PL, DESCENT quantization, 8-bit, High throughput
Download the pretrained model referenced above and save in /workspace/vck5/resnet50. This folder will remain persistent between container sessions while /usr/share/... will not keep any changes after the container is exited or stopped.
Compile the demo/Vitis-AI_Library/samples/classification demo according to the instructions in its folder, then copy over the model and run the demo using the pretrained model:
sudo mkdir /usr/share/vitis_ai_library/models
sudo cp -r /workspace/vck5/resnet50 /usr/share/vitis_ai_library/models/resnet50
cd /workspace/demo/Vitis-AI-Library/samples/classification
source /workspace/setup/vck5000/setup.sh
./test_jpeg_classification resnet50 sample_classification.jpgThis should result in a set of classification scores from demo.hpp based on the default resnet50 training.
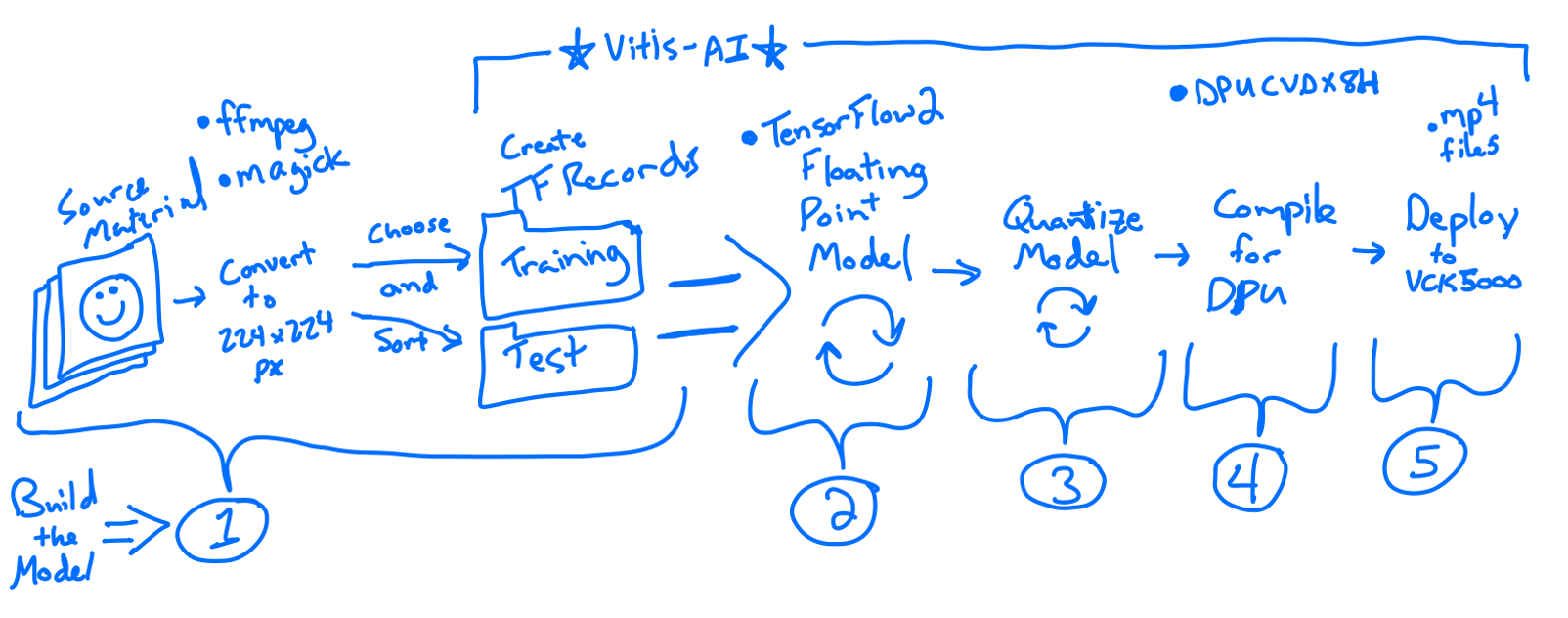
Build the model - Step 1 Prepare datasetFrom your source videos extract high quality frame data using ffmpeg tool
ffmpeg -i <video.mp4> -qscale:v 2 <outdir>/out%04d.jpgConvert the jpgs to our model input size 224x224 pixels. This will distort the images, but the result will still be effective because we are looking for colors and rough shapes, not specific details.
magick mogrify -resize 224x224! *.jpgNow we will sort the images into folders to use for training and validation.
/Videos/event -or- /Videos/none1
Copy these into Training and Test such that we have this structure:
/Videos/AS_for_TFR/Training/event
/Videos/AS_for_TFR/Training/none1
/Videos/AS_for_TFR/Test/event
/Videos/AS_for_TFR/Test/none1The samples are being prepared for a model with 2 output products (event, none1). I opted for none1 instead of 'none' because 'none' is a Python keyword.
Next we will build TensorFlow records from our folders using the tf_record.py script in Tutorial 12. We cloned Vitis-AI-Tutorials earlier along with Vitis-AI.
Update the tf_record.py with our new file locations
tf_record_dir='/workspace/Videos/tf_records' #output directory path for TF Records
raw_data_dir='/workspace/Videos/AS_to_TFR' #Directory path for raw datasetRun the script, and you should get a directory that looks like this:
Python3 tf_record.pyFinally run gen_validation_set.py file (attached) to generate validation dataset.
Build the model - Step 2 Train floating point modelMany scripts in the Tutorial 12 project make use of the train_eval_h5.py source file. We will make a few adjustments :
- Set the input shape from 100x100 to 224x224
- Set the output from 131 to 2
- My train_eval_h5.py (attached) is included as source
Edit the train_from_scratch.sh file to point to our evaluation images.
--eval_image_path=/workspace/Videos/tf_records \Train until reasonable accuracy is achieved, or model hits an apex (meaning, it cannot improve)
bash train_from_scratch.shThere are also tools to help set up 'resume training' where training can be paused and restarted with the last training result.
Build the model - Step 3 Quantize the floating point modelIn order to convert the model from floating point to 8bit quantization for execution on our DPU, it must run through a quantization process. Xilinx provides a quantization tool that will apply necessary adjustments to the model without losing accuracy. The process will look similar to training, but is much faster.
Modify the following lines in quantize.py script
--model -> (the final trained model from step 2) \
--eval_image_path=/workspace/Videos/val/val \
--eval_image_list=/workspace/Videos/val/val_labels.txt \Execute the script
Python3 quantize.pyEdit the compile.py script to point to the quantized model as well as our target information files. Execute the script to compile the model for VCK5000 DPU. Make note that the compiler needs to have access to a '.json' file that corresponds to the specific DPU being used. This.json file should have been installed with the VCK5000 installation setup. The compile.sh should be updated as shown:
vai_c_tensorflow2 -m tf2_resnet50/vai_q_output/quantized.h5 \
-a /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK5000/arch.json \
-o tf2_resnet50/vck5000 \
-n resnet50 \
--options '{"input_shape": "1,224,224,3"}'Run the compilation
Python3 compile.pyModel outputs will be in ./tf2_resnet50/vck5000
md5sum.txtmeta.jsonresnet50.xmodel
We now rename and copy them to the /usr/share/vitis_ai_library/models/tf2_resnet50 directory. Also copy the resnet50.prototxt file from the resnet50 pretrained model we used in Baseline hardware check. resnet50.* files should be renamed tf2_resnet50.* Inspect the contents of the.prototxt file (it is text, so use nano or cat).
Attached to project is my pre-trained and compiled tf2_resnet50 model that can be deployed from this directory to run the demo.
Next edit the process_result.hpp to update our classification list and video output overlay
nano /workspace/demo/Vitis-AI-Library/samples/classification/process_result.hppI have included the process_result.hpp (attached) as source in this project.
With the changes completed it is time to rebuild the classification demo
cd /workspace/demo/Vitis-AI-Library/samples/classification
bash build.shI have found it helpful to add a usleep to be able to see how well the detection is running on video (frame by frame). Make changes as shown and rebuild demo.
sudo nano /usr/include/vitis/ai/demo.hpp
- Search for a comment:
// loop the videoto find the correct section
virtual int run() override {
auto& cap = *video_stream_.get();
cv::Mat image;
cap >> image;
usleep(100000); // this will slow the video for analysis
auto video_ended = image.empty();
if (video_ended) {
// loop the video
open_stream();
return 0;
}
....Prepare the container to display the video
sudo apt-get update
sudo apt-get install libcanberra-gtk*
export DISPLAY=:0.0Finally run the video demo with our tf2_resnet50 model on an mp4 video file (replace with actual filename).
./test_video_classification tf2_resnet50 <video_filename.mp4> -t 4A new window should spawn on Ubuntu desktop with the file playing and some overlay text. The -t 4 parameter sets the number of process threads that will queue DPU processing. Experiment with thread count to see if you get performance improvement.
On the command line window press CTRL+C to stop the application (the video window will close automatically).
Framerate throughput supports many simultaneous users!
Warning! If you experience photosensitivity please use caution with the included videos. The content was selected to demonstrate extreme flashing and movement.
- Launch video in large window, but pause before it plays. Drag the time slider back to the beginning of the video. Select high resolution playback (the yellow text should be sharp and legible)
- Drag the window or use a piece of paper to cover the right side for the first playthrough. Take note of the intensity, and note if you experience any 'vision burn-in' where you blur focus or lose visual information for a period of time.
- When the video has completed, move the slider to restart and cover the left side of the image for the second playthrough to see the detection accuracy and image adjustments.
- Compare notes with me, first video is mild adjustment, second video is aggressive adjustment. The VCK5000 detector is the same in both.
Clip 1 brain : The big flash gives me a 'visual burn-in' effect where I perceive it for much longer than it actually exists. In the adjusted video the flash does not disorient my vision, the artifacts from the adjustment are a little too obvious and could be tuned down with additional work on the filter. Clip 2 donut : The original was completely unwatchable for me, I cannot maintain focus with my eyes. The adjusted video is ok, it is still intense, but I can see what is going on.Clip 3 battle : The original was mostly ok but some block destructions were bright and I would lose focus on the screen. The adjusted video I did not experience any issue and felt like the video was smooth and clear for its duration.Clip 4 hallway : Original is very bright to me, so my vision is blurry when the lights are close and more sharp when they are far away. The adjusted video I have clear vision the entire timeFinal project notes and future development
I am very happy with the trained resnet50's ability to detect a variety of irritating content, especially the DPU high framerate almost 500FPS. Frame by frame analysis did not reveal any detection 'misses' which indicate the training and subsequent quantization work very well to represent my intention. It can be even more accurate with additional training for specific content. Some of my training involved a popular first person video game, but its result could not be shown as to comply with contest rules.
Now that detection is working very well, the next item to tackle is to improve the adaptive content filter algorithm to dull bright effects without artifacts. Perhaps an inspired reader will take on the challenge!
Parting advice for development on containers and AI toolchain- Do not upgrade software in container. The purpose of a container is to hold a set of working and compatible tools. The Vitis-AI containers start from a working set, so be very deliberate about what you add. The base machine and build will also need to be compatible with hardware and recommended software drivers. This is not a case of 'download latest and go'
- Learn how to mount persistent folders with your container launch script. A project like this will have a large batch of files that you might evaluate inside and outside of your container (like the video and image source files). Sometimes you might also want to edit or change folders with a more convenient tool that is not in the container.
- conda activate.... when launching your container you will also select a toolchain. This will enable paths to the tools you will need to follow your flow.
- Intermediate and output files are not interchangeable between tool chains. Meaning, it is not easy to take a TensorFlow2 model and convert it directly to an actual Caffe model. In some cases it is possible (like in this project where we use a trick), but do not assume it.
- Models have specific input configurations, for images it might be 224x224 or 100x100, or something else. The model will expect to be trained and validated with images of that size. You will also want to confirm model input size is compatible with DPU. The DPU will be able to run the compatible model on much larger image/videos (1920x1080, 3840x2160, etc)
- Xilinx provides example designs for specific toolchains. To start out, it will be helpful to find an example you can work through to learn a toolchain like TensorFlow2 or Caffe. I would highly recommend running through the full toolchain with a minimally trained model to make sure the flow is good before spending time/effort/money on training a model that might not be deployable.
- CUDA, cuDNN, or not. I and several others have exciting GPU power that sadly could not be utilized for floating point training because we could not solve our workspace driver compatibility. New NVidia RTX cards require new CUDA and cuDNN versions, and some toolchains cannot support them. The new Vitis-AI 2.0 update supports modern CUDA but the VCK5000-ES1 card is limited to Vitis-AI 1.4.1. I still trained to high accuracy with CPU, but it takes approximately 10x longer even with a high-end CPU.
- Docker container location. Many PCs have a very nice and fast boot drive where most programs reside. The Docker container workspace by default will be installed on the same drive where docker is installed, but it will become quite large with Vitis-AI, datasets, and training models. I followed a guide to move the actual container storage to a second drive. This enabled me allocate more space for the container.
- A flow chart is added (attached) to give visual representation of the steps and help navigate the sections of this project.
- Vitis-AI-Tutorials / Design_Tutorials / 12-Alveo-U250-TF2-Classification : This is an example tutorial to train and deploy a ResNet50 model using TensorFlow2 toolset. I modified the tutorial quite a bit, but it is very helpful to understand the process. When the model is successfully compiled, I port it back to the classification demo instead of finishing the tutorial
- Vitis-AI / demo / Vitis-AI-Library / samples / classification : Run test_jpeg_classification as a sanity check to confirm my hardware is working. Use test_video_classification demo as the framework to run a multi-threaded MP4 video -> VCK5000 DPU -> Overlay classification result on video -> display video on screen. Note that the changes in this project will 'break' the example design due to incompatible model output size (151 vs 2). The updated result process is only compatible with the new trained model.
- Vitis-AI / demo / VART / resnet50 : This demo can also be used to evaluate JPG images, it is helpful that it will use the.xmodel file from compilation directly, the samples/classification demo used expects an additional.prototxt file from Caffe toolchain (that we borrow from the zoo....)
- LSPCI tool will help identify the card and kernel drivers. Here is a snapshot of the working configuration on my machine. If kernel module is listed, but kernel driver is not listed as 'in use' then there is a problem with the driver or shell running on the VCK5000.
- XBUTIL is a powerful tool to check status of the VCK5000. There is an entire debug page on Xilinx github that is helpful to read and verify.




{kind=link}
Comments
Please log in or sign up to comment.