


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
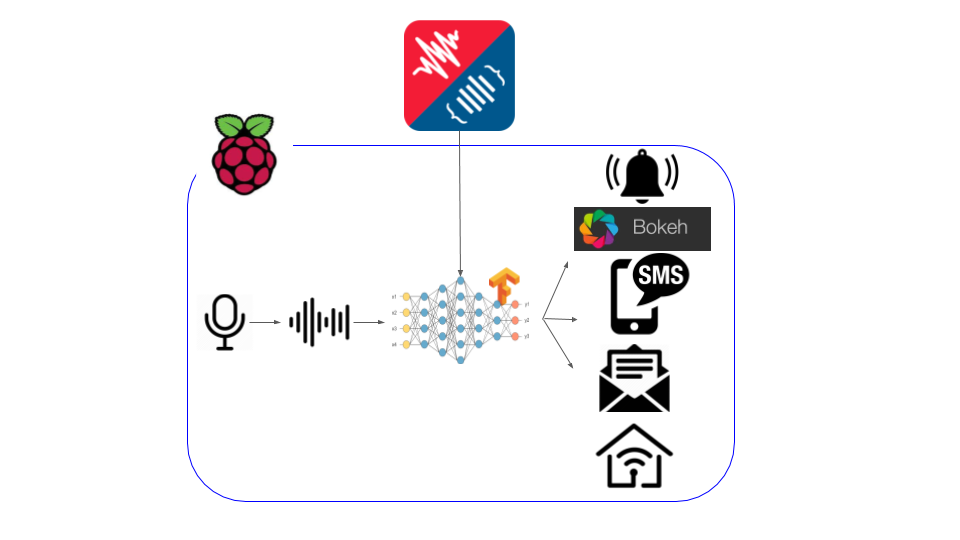
With the vast availability, interoperability and technical ability of today’s smart devices, we need improved means to understand our surroundings and make better use of these tools. The ability to generally classify the audio surrounding in real-time on the edge will provide an improved means to automate home smart devices and provide an auditory situational awareness. This IoT project is aimed at applying machine learning techniques to perform general sound event classification on real-time audio at the collection point. As the audio signal enters the device, audio capture, signal preparation and real-time inference all happen in real-time, directly on the device so your audio is private and never enters the network. The audio signal is processed through a bi-directional LSTM RNN and classified into some discrete number of classes. This project uses vggish for audio feature extraction and AudioSet for inference model training.
Assembling the DeviceThe device assembly is straightforward. First, follow the instructions on the official raspberry pi site to install raspian on your SD card. Then head over to the Seeed wiki to install the Seeed 2-mic hat.
SoundScene Software InstallSoundScene is the set of python utilities that run directly on the raspberry pi that perform the audio capture, audio pre-processing, audio classification as well as the inference application (sending of SMS, recording, LEDs, etc.). The following assumes you've installed raspian (full or minimal with ssh enabled) and the device is connected to your network. Here are the steps to install:
- Ssh to the device
ssh pi@192.168.1.27 #your ip will differ- Install git and clone soundscene
sudo apt-get -y install git
cd /tmp
git clone https://github.com/stantonious/ss-apps.git- Run soundscene install scripts (takes awhile to install on the Raspberry PI 3b+)
ss-apps/setup/scripts/ss-setup.sh
#Follow the prompts to setup your RaspiWifiOnce you've gone through the RaspiWifi setup, you'll need to reboot your device. RaspiWifi turns your device into a WAP (web access point) and exposes http://10.0.0.1/ to allow you to configure your device's wifi. Once your device is rebooted, use a cell phone (or other wifi enable device) to connect to your device's WAP (usually labeled as
DemonstrationFeatures- AudioSet pre-trained classifiers. There are a few different pre-trained models that are available (accuracy/model information available upon request). You can find the pre-trained models at https://console.cloud.google.com/storage/browser/ss-models
- Client-side apps. There are pre-installed applications that run directly on the raspberry pi and respond to live inference. The applications include; recording app, live inference gui (bokeh), LED app.
- Open wifi headless configuration. By way of the fantastic open source project RaspiWifi, you can plug-in and headlessly configure your device to perform audio classification anywhere with power. This feature is enable when you hold the button on the Seeed mic hat for 10 seconds. Note - wifi is only necessary if you want SMS notifications and audio playback.
- SMS notification. I have some Google App Engine services running to perform real-time SMS notification with audio playback. Contact me for information.
- Sound sample submittal to improve model accuracy
- Smart baby monitor
- Smart pet monitor
- Monitor an absent hotel room
- Monitor for running water in a vacant property
- Sound scene
- Run the inference GUI
The inference GUI show real-time inference values generated by the device. It's a bokeh application that runs directly on the raspberry pi.
ssh pi@192.168.1.27 #your ip will be different
vi /usr/local/bin/start-ss-gui.sh #update the BOKEH_ALLOW_WS_ORIGIN to your IP (leave the port as is)
sudo service ss-gui startNavigate to http://<your ip>:5006/
- Build a custom app
All the SoundScene application receive their inference via RabbitMQ. Use one of the example application provided to base your custom app. You'll want to register to register to receive inference updates as such:
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='inference',
exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
channel.queue_bind(queue=result.method.queue, exchange='inference')- Start/Stop SoundScene services
All SoundScene services are systemd services. You can show/start/stop services as such:
ls /lib/systemd/system | grep ss- #show installed services
sudo service ss-notif-1 start # Start the Male notification service- Install a new model
You'll need to pull the desired model from https://www.googleapis.com/storage/v1/b/ss-models/, redirect the soundscene symlink and reboot your device
#Install the HacksterIO demo model
ss_dir=/opt/soundscene
sudo curl -XGET -o ${ss_dir}/hio-nobaby.tflite "https://www.googleapis.com/storage/v1/b/ss-models/o/hio-nobaby.tflite?alt=media"
if [ -d "${ss_dir}/soundscene.tflite" ]; then
sudo rm ${ss_dir}/soundscene.tflite
fi
sudo ln -s ${ss_dir}/hio-nobaby.tflite ${ss_dir}/soundscene.tflite- The AudioSet dataset is awesome, but not perfect. The dataset is human labeled (of course) and contains some error. I've seen heavy overlap in classes such as Baby, Child and Silence. I've applied some techniques to remove this overlap, but error still exists. My advice is test out the various models and configuration options to see which best suites your needs
- Raspberry PI 3b+ is barely powerful enough to run live inference. You will notice occasional audio dropout, and you'll likely want to run the backoff application to keep from running the device too hot. I've had much better results with the Raspberry PI 4!





{kind=link}
Comments