



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Word detection is sometimes way more intuitive and handy than typing on the screen of a cell phone. That's why nowadays, no matter home devices or electric cars, all march in the direction of supporting voice recognization to control the system. Except for being convenient, most of us use our voice when we want to communicate with "people" and get things done. Even during the covid pandemic, the team requires an online meeting to finish the work since the text is sometimes insufficient. In other words, when the robot can listen and realize the words of humans, the human is more likely to treat the machine as another human and benefit from them. Therefore, this project is meaningful to me, since if one day we can build many tiny machines to listen to the voice and enhance the life of every human, that would be awesome.
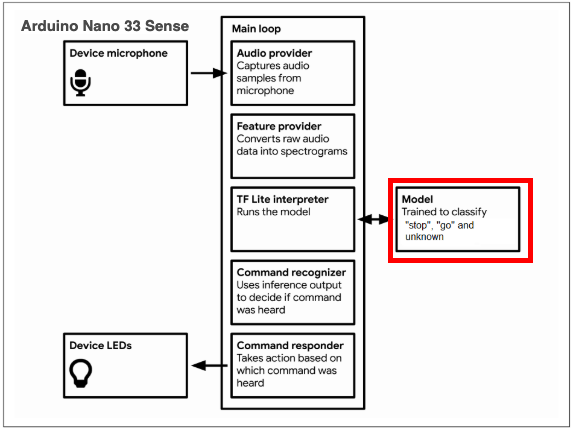
GoalThis project aims to train speech command datasets on the TensorFlow platform and use the model on Arduino Nano 33 BLE Sense board to detect the voice. The embedded voice recognition device will light green when recognizing "go, " and turn red when hearing "stop" and when the voice is unrecognized, then it will light blue.
ApproachBefore we start, we need to understand that we have to feed data into a TensorFlow Lite model and run it on a microcontroller with limited memory, so we got to optimize it. The training data we have is the free-spoken audio dataset and uses the public TensorFlow Simple Audio Recognition script. In order to accelerate the training process, I also use TPU and high-RAM in Colab. Although most of the training scripts have been prepared in Colab, we are still able to customize the configuration as training steps and learning rates. Here is the summary of how my data train:
Training these words: stop,go
Training steps in each stage: 10000,2000
Learning rate in each stage: 0.001,0.0001
Total number of training steps: 12000While training the data, we also have TensorBoard appearing in Colab to see the progress and result of current trained data. TensorBoard shows two graphs, “accuracy” and “cross_entropy.”
A TensorFlow model consists of the weights and biases resulting from training and we need to convert them to TensorFlow Lite. The steps we take here are to freeze the graph and generate the C array. After that, we verify the accuracy of our microcontrollers modal is still high enough.
Float model accuracy is 87.387387% (Number of test samples=1221)
Quantized model accuracy is 87.223587% (Number of test samples=1221)Before we can explore how the machine runs, we also have to replace the original model data with our new model, which means we have to replace the model/update the labels/update command_responder.cc. Finally, we move to compile and upload modal to the board and test the functionality of our application on Arduino. Through this project, it's really great to follow the instructions and understand what's happening for tinyML under the hood.

{kind=link}
Comments
Please log in or sign up to comment.