



We've made a Walkie-Talkie using the ESP32.
Audio data is transmitted over either UDP broadcast or ESP-NOW. So the Walkie-Talkie will even work without a WiFi network!
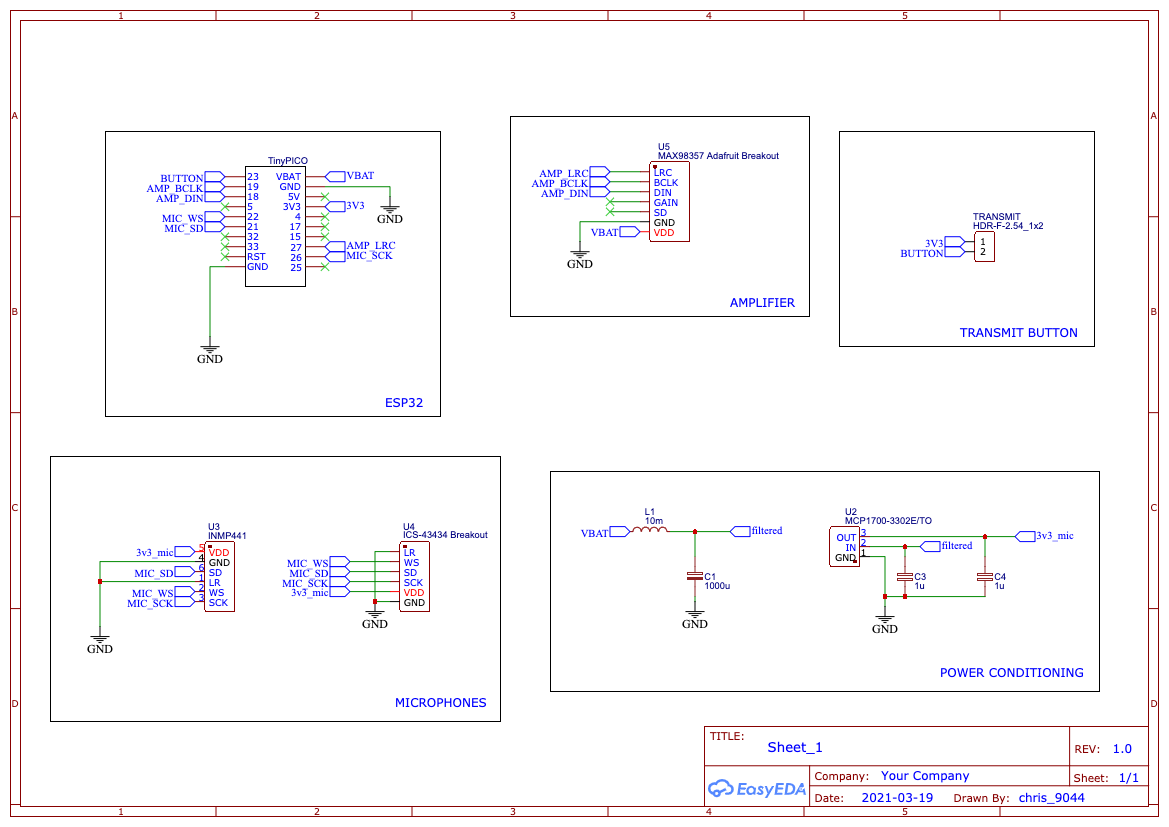
I've based it around an I2S microphone and an I2S Amplifier - but it will work equally well with analogue microphones and headphones with a small change to the code.
DetailsThere's a little video here that gives an overview of the project.
You can access the Fusion360 project here: https://a360.co/2PXgAUS - so feel free to print your own version if you want.
For the microphone in the video, I'm using my own ICS-43434 microphone board but it will work equally well with the INMP441 microphone board.
These are both I2S microphones that interface directly with the ESP32.
The I2S 3W amplifier board is from Adafruit and powers the speaker. This also directly interfaces with the ESP32.
For the ESP32 board, I'm using a TinyPICO, but any generic dev board can be used as we aren't using any special features in this project.
I'm using a custom PCB - I got this made up by the great people at PCBWay - as usual, they did a great job and I'm really pleased with how the boards have come out.
I've got a lot of audio projects and it's really nice to be able to just plug things together and not to have to worry about wires going everywhere. The only slight omission I've made is not breaking out the remaining GPIO pins - so I think I'll do a version 2 of the board soon.
Here's a link to the schematic and PCB on EasyEDA and a link to order the board directly from PCBWay if you want to.
Having said that, you really don't need a PCB, you can easily just connect everything up on breadboard - and that's exactly what I did when I was prototyping.
The schematic is very simple - we're using I2S boards for both the microphone and the speaker which makes the wiring up of these to the ESP32 very straightforward.
You can of course modify the code to use the built-in ADC for input and the built-in DAC for output. Very handy if you want to use analogue microphone boards and a headphone jack for output.
I've added a bit of extra circuitry to my board to create a clean power supply for the microphones. If you watch some of my earlier videos then you'll recall that we were picking up quite a lot of noise on the microphones when using WiFi.
To fix this noise problem we are creating a clean 3.3v power supply for the microphones by taking a direct feed from the battery, we filter this with an LC filter and then pass this to a Low Drop Out regulator. This gives us a really nice and clean power supply for the microphones which removes a lot of the noise issues.
All the code is on GitHub - it should be mostly self-explanatory, but I'll give a high-level overview here.
The main challenge with this project is how to get the audio broadcast from one walkie-talkie to all the other walkie-talkies.
I've implemented this in two different ways. You can easily switch between these in the code with a simple hash define.
The first way is using UDP broadcast. UDP broadcast is a very simple mechanism. You send a UDP packet to a special IP address and your router broadcasts this packet to all the other devices on your network.
We can safely send up to 1436 bytes in a UDP packet so if we're sampling at 16KHz and using 8-bit samples that's around 90ms of audio data. So we need to send around 11 packets per second. This is well within the capabilities of the ESP32.
The big advantage of using broadcast UDP is that we don't need to know about our peers, we can just broadcast a message and anyone who is listening for it will receive it. We also don't need a centralised server that everything connects to. All the heavy lifting is done by the router.
However, there are some disadvantages of UDP that we should be aware of:
- Delivery of UDP packets is only best effort - there is no guarantee that someone will receive the packet you send.
- There is also no guarantee of packet ordering - someone may receive the packets you have sent in completely random order.
For this project, I've chosen to ignore these two issues. With broadcast packets, we're generally staying in the same network so we probably won't lose too many packets and our packets will probably also come in the correct order. If they don't then we'll just get a bit of noise and distortion on the audio.
The other big advantage of UDP broadcast is that you can receive the packets on your desktop computer or your phone - so it would be quite easy to create additional clients that are not based on the ESP32.
The second way I've implemented the transport is to use ESP-NOW.
ESP-NOW is a protocol developed by Esppresif which enables multiple ESP devices to communicate with each other without needing WiFi.
This gives us one great advantage over the UDP option in that we don't need a WiFi network to make our Walkie-Talkie work.
The disadvantage with ESP-NOW is that it has a much smaller packet size of 250 bytes. This means that we need to be sending packets 64 times a second.
We also have all the same downsides as UDP - packet delivery is best effort and there is no guarantee what order the packets will arrive in.
However, in my tests, it has performed reasonably well.
With the transport problem solved we just need to hook everything up.
We have the I2S input - this reads samples from the microphone and passes them to our transport.
Once the transport has accumulated enough data to fill a packet it sends the data through either UDP or ESP-NOW.
On the other side, we have the same transport listening for packets. Every time a packet is received it queues the data up for playing via our I2S output. The I2S output just pushed samples out to the I2S amplifier.
To allow for packets taking slightly longer to arrive we have a buffer between the transport and the I2S output. We let a small amount of time elapse before we start playing the samples - this gives us some spare time to allow for packet jitter. It does come at the cost of some latency in the audio - with everything taken into account the audio is played about half a second after it was made.
All in all, though the project works. Quality is not amazing, but it's certainly sufficient for a hobby project.
As always, the code is all on GitHub. Let me know what you think in the comments. And if you have any improvements then please open up a pull request.
Some ideas that would be good to look at:
- Compression of the audio to reduce bandwidth.
- Automatic Gain Control
- Echo cancellation so we can have full-duplex
There's probably a load of other improvements, so feel free to hack away!
{kind=link}

Comments
Please log in or sign up to comment.