






Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
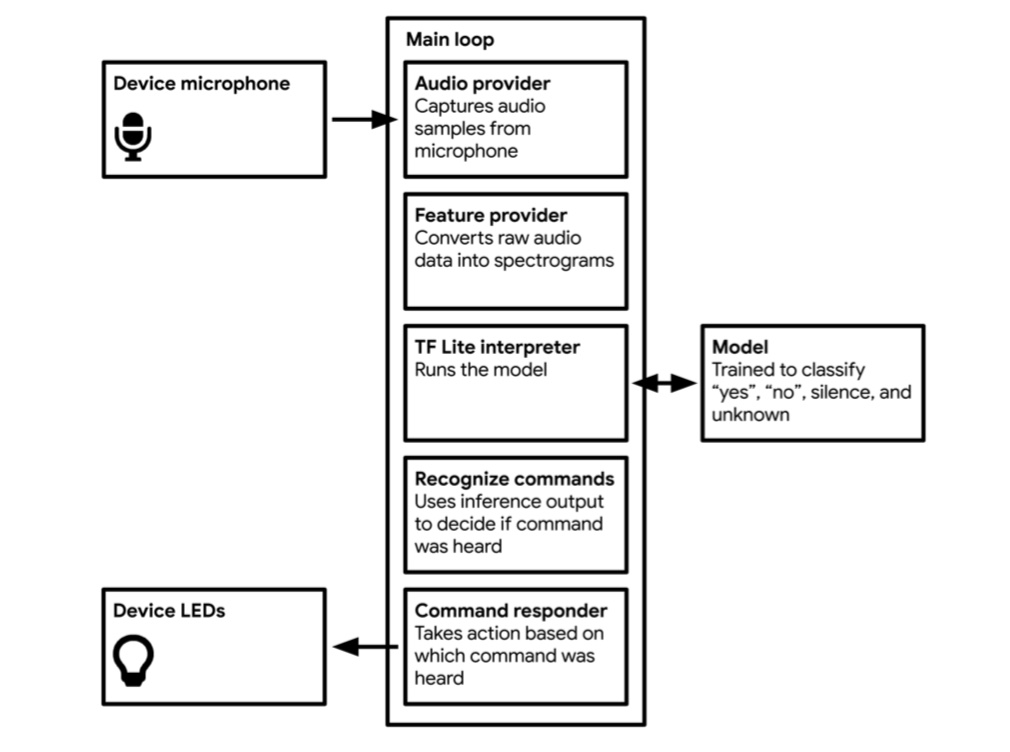
The model is trained to recognize the words “yes” and “no”, and is also capable of distinguishing between unknown words and silence or background noise.
Our application will listen to its surroundings with a microphone and indicate when it has detected a word by lighting an LED or displaying data on a screen, depending on the capabilities of the device.
Application ArchitectureWe walked through Chapter 7: Wake word detection Building an application to know the basics of the application architecture and it did the following sequence of things:
1. Obtains an input
2. Pre-processes the input to extract features suitable to feed into a model
3. Runs inference on the processed input
4. Post-processes the model’s output to make sense of it
5. Uses the resulting information to make things happen
ModelThe model was trained on a dataset called the Speech Commands Dataset (https://oreil.ly/qtOSI). This consists of 65, 000 one-second long utterances of 30 short words, crowdsourced online. The model takes in one second worth of data at a time. It outputs four probability scores, one for each of these four classes, predicting how likely it is that the data represented one of them.
ResultThen we followed the instruction from Chapter 7 to understand the code and deploy it to the sense. Here is the demo of our application.







{kind=link}
Comments
Please log in or sign up to comment.