




Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
 |
| |||||
In recent years, cryptocurrencies have become an increasingly popular medium for decentralized transactions. Transactions are recorded on distributed ledgers, enhanced with a cryptographic Proof of Work (PoW). PoW is the foundation for decentralized consensus; the transactions are verified with minimal effort, but adversaries must spend significant computational effort to abuse or disturb the system. Honest cryptocurrency miners help compute the PoW, and they are incentivized with a fraction of cryptocurrency as a reward for their effort.
Currently, PoW computations are often built by iterating a cryptographic hash function until the output has a dedicated form. This is an energy-intensive process, that presents a prime candidate for acceleration with dedicated hardware. Nevertheless, several cryptocurrencies adopt so-called ASIC-resistant PoW algorithms. These types of PoW aim to deter dedicated hardware miners in favor of CPU and GPU-based miners, which are more generally available to the public. This decision is targeted at sustaining the distributed ledger idea, by preventing a monopoly where the majority of the miners are owned by a limited number of entities.
Initially, cryptocurrency ledgers were public and open to anyone. Then, the demand for private transactions appeared, and new cryptocurrencies aimed to satisfy this market gap. The Haven Protocol is one of the projects with such a goal. For its PoW, Haven leverages on a custom ASIC-resistant hash function named as CrpyptoNight Haven.
In this project, we challenge the ASIC-resistance claims of CryptoNight-Haven, by implementing the PoW as an XRT RTL kernel on FPGA. We construct our hardware accelerator as a XRT RTL kernel targeting the Xilinx Varium C1100 Blockchain Accelerator Card. The design employs deeply pipelined computation and XRT integration over a high-speed PCIe Gen 4 bus connection. We employ HBM for the underlying intermediate scratchpad data storage, allowing parallel execution of many computation cores.
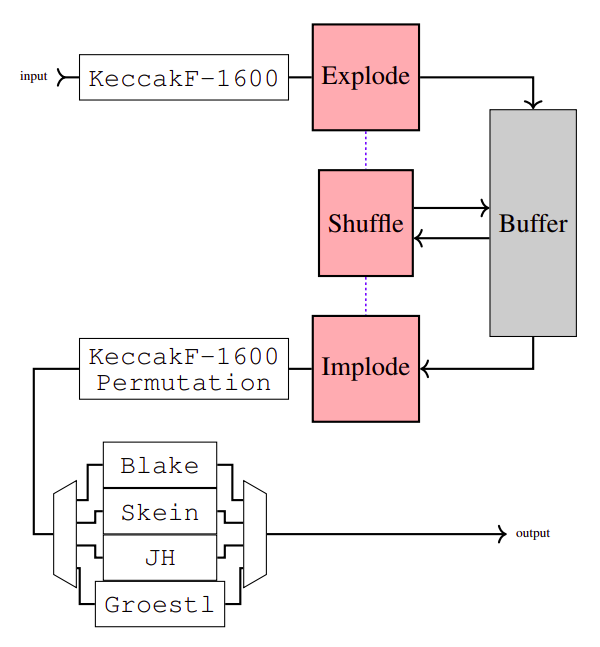
ArchitectureOur hardware architecture for CryptoNight Haven is shown below. Cryptonight-Haven chains together multiple well-known cryptographic primitives, e.g. AES, Keccak, Blake, and others. Together, these primitives are used to initialize the large 4 MB scratchpad data buffer, on which semi-random operations are performed.
The most time-consuming step is shuffle. The shuffle step performs semi-random operations on the memory buffer. It is initialized using the first 128 bytes of the state. Shuffle performs many iterations that are separated into three parts each: a read, an operation and a write of the result. The operation involves an AES computation, multiplication, addition, and division. Especially this last operation is aimed at deterring custom hardware miners.
To maximize throughput, the shuffle step is pipelined to be able to perform up to 128 hashes -- block headers with incrementing nonces -- simultaneously, requiring 512 MB high-bandwidth scratchpad storage. Pipelining shuffle decreases the explode and implode cores' idle time.
ResultsUnfortunately, we did not finish our miner implementation in time for the 2021 Adaptive Computing Challenge and cannot present conclusive mining results. Our design is verified in RTL simulation and hardware emulation but produces incorrect outputs on the Varium C1100. We plan to finish our design shortly after the challenge. Stay tuned for energy-efficient high-throughout FPGA mining results!
-1_U2cBCoh4Is.png)










-1_U2cBCoh4Is.png){kind=link}
{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.