

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
 |
| |||||
Why did we decide to make it?
COVID-19 has been spreading for almost three years, from the initial delta to the current Omicron. The virus is gradually becoming more infectious, and although we have antigen rapid test and PCR test, the accuracy of antigen rapid test is not high and PCR test takes too long to get the result. So we want to use deep learning to help doctors or patients to complete the diagnosis with just x-ray photos, to speed up the diagnosis while ensuring accuracy.
What is our project about?
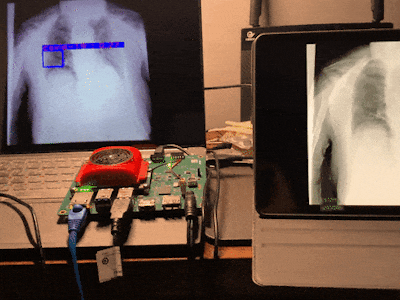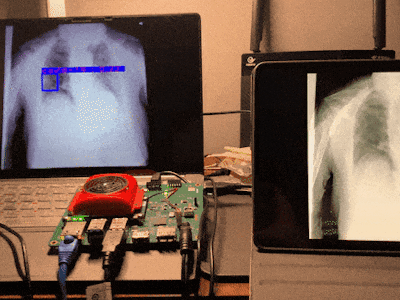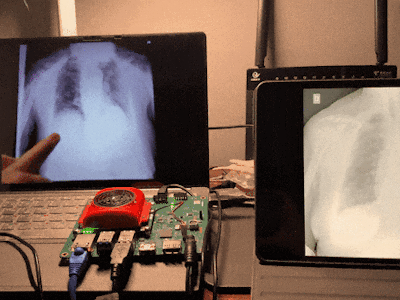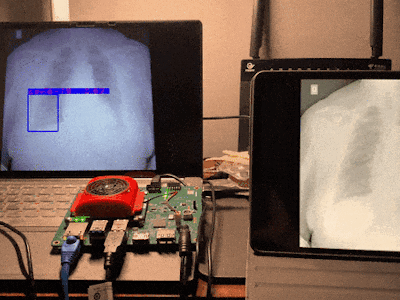
Our project is to run the yolo v2 voc tiny model on Kv260 to determine and localize whether covid19 is infected and the location of the lung lesion based on lung x-rays. The design requires no complicated circuit connections, just a usb drive-free camera, and your lung x-ray to complete the diagnosis. It is simple to use and easy to operate.
How does it work?
- Model Training
We obtained lung x-rays from the Kaggle competition "SIIM-FISABIO-RSNA COVID-19 Detection" and their corresponding label files(https://www.kaggle.com/competitions/siim-covid19-detection). To improve the training efficiency we preprocessed the photos to 512*512 size and generated XML files with the coordinates of the new coronal lesion shadows as tags. We made the data into a standard VOC2007 dataset and used the C++ version of the yolov2 code for training.
https://github.com/pjreddie/darknetIn the training process, we used 416*416 size images as input, batch size was set to 8, and the final filter output was changed to 1 class for 200, 000 iterations to train and output the darknet format weight model. The training process used a pre-trained model generated by yolov2 on the voc2007 dataset. The training instructions are as follows:
./darknet detector train cfg/voc-covid-19.data cfg/yolov2-voc-tiny-covid-19.cfg darknet53.conv.74After training on the Linux server, we use a python script to convert the darknet-formatted weights into TensorFlow-formatted weights:
python main.py \
--cfg 'cfg/yolov2-tiny.cfg' \
--weights 'data/yolov2-voc-tiny_200000.weights' \
--output 'data/' \
--prefix 'yolov2-voc-tiny/' \
--gpu 0- Model Quantization
After this we enter the Vitis-AI container, quantify the transformed model and build the frozen graph:
freeze_graph --input_graph yolov2-voc-tiny.pb --input_checkpoint yolov2-voc-tiny.ckpt --output_graph frozen/frozen_graph.pb --output_node_names yolov2-voc-tiny/convolutional9/BiasAdd --input_binary trueQuantifying frozen graphs:
vai_q_tensorflow quantize --input_frozen_graph frozen/frozen_graph.pb --input_fn calibration.calib_input --output_dir quantize/ --input_nodes yolov2-voc-tiny/net1 --output_nodes yolov2-voc-tiny/convolutional9/BiasAdd --input_shapes ?,416,416,3 --calib_iter 100Compile the quantized model so that it can run on kv260:
--frozen_pb quantize/quantize_eval_model.pb -a arch.json -o yolov2voctiny -n yolov2voctiny- ModelDeployment
First, we need to upload the yolov2tiny directory to KV260 using the following command.
scp -r yolov2tiny petalinux@192.168.0.150:~/You need to set the IP address as your KV260 board.
We will replace the SSD model with our model.
Now, copy our project(including yolov2tiny.xmodel, yolov2tiny.prototxt, aiinference.json, preprocess.json, label.json, meta.json and drawresult.json) to the board at /home/petalinux/yolov2tiny directory.
Then copy aiinference.json, preprocess.json, label.json, and drawresult.json from our project to /opt/xilinx/share/ivas/smartcam/ssd/
Don't forget to connect the USB webcam to the USB port of the KV260.
Then you can load the application and run it as a normal deployment.
sudo xmutil unloadapp
sudo xmutil loadapp kv260-smartcam
sudo smartcam --usb 0 -W 640 -H 480 --target rtsp --aitask ssdFinally, you will get output like this.



Comments