



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
The idea behind this project was to prototype a stereo depth camera with AI capabilities such as object segmentation and tracking.
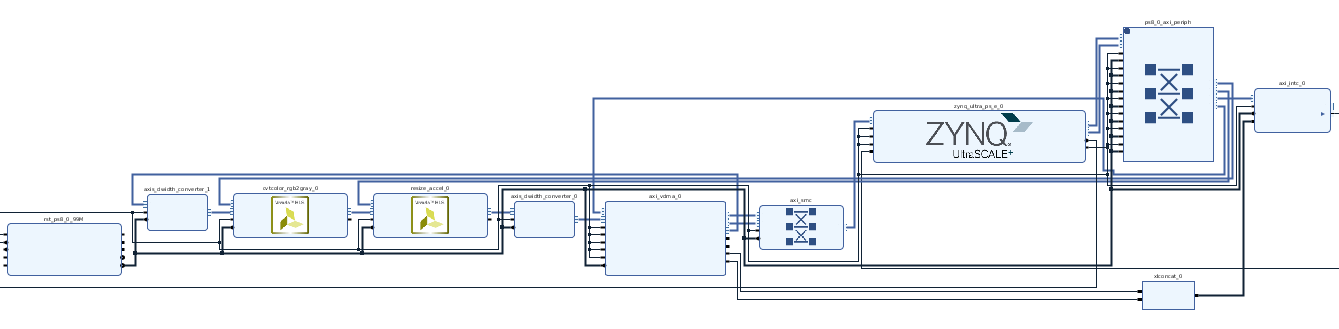
The project makes use of the Vitis Libraries IP cores as well as the DPU IP. Ubuntu 18.04 was used along with Vivado 2020.1, Vitis and Vivado HLS, Vitis AI version 1.2, and models from Vitis Vision Libraries were used for the generation of the IP cores.
Any image processing pipeline is a composed of a number of blocks. Before the images are sent to the AI portion of the algorithm they need to be pre-processed. First, the incoming images will be pre-processed by passing through the Vitis Vison IP blocks. Then the image data will pass through DPU network for segmentation. At the same time the same image will be passed to an object detection model such as mobilenet.
The stereo camera mezannine is simulated by writing the stereo pairs from the PS side using DMA or VDMA.
git clone https://github.com/Xilinx/Vitis_Libraries.gitTo use this, OpenCV 3.4.4 has to be installed as shown below.
3. Installing Open CVsudo apt -y install build-essential checkinstall cmake pkg-config
sudo apt -y install libjpeg8-dev libpng-dev
sudo apt install libjasper1 libjasper-dev
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt install libjasper1 libjasper-dev
sudo apt -y install libgtk-3-dev libtbb-dev qt5-default
sudo apt -y install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev libdc1394-22-dev
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
cd opencv
git checkout 3.4.1
cd ..
cd opencv_contrib
git checkout 3.4.1
cd ..
cd opencv
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D OPENCV_EXTRA_MODUL$
make -j6
sudo make install
sudo sh -c 'echo "/usr/local/lib" >> /etc/ld.so.conf.d/opencv.conf'
sudo ldconfig
find /usr/local/lib/ -type f -name "cv2*.so"
cd /usr/local/lib/python3.6/dist-packages/
sudo mv cv2.cpython-36m-x86_64-linux-gnu.so cv2.soUnder Vitis_Libraries/vision/L1/examples you’ll find a number of IP vison cores. These cores use the AXI interface which means that in order to input and output data from them one has to either write data from the PS side or use an interface converter. The other option is to modify the cores in streaming mode since image sensor produces streams of data.
The PYNQ resize examples uses an old version of Vitis Vision libraries that has a couple of bugs plus the conversion of stream to xf::MAT are not supported in the latest version since they are not part of the API.
3. Streaming imaging cores with PYNQCreate a folder on the same directory as the examples folder. I named this /examplest. Copy the stereolbm, resize and colorconv folders on the newly created folder.
Now open the tcl file and modify it by adding the following. For the stereo local block matching algorithm for example add the following where /user is your Linux user account name.
I have edited commented out the settings.tcl file since this file does not exist from the git repo. Another option is to create this and place all the lines below on that file.
#source settings.tcl
set PROJ "stereolbm.prj"
set SOLN "sol1"
set XF_PROJ_ROOT "/home/user/Documents/Vitis_Libraries/vision/"
set OPENCV_INCLUDE "/usr/local/include/opencv2"
set OPENCV_LIB "/usr/local/lib"
set XPART "xczu9eg-ffvb1156-2-i"
set CSIM "1"
set CSYNTH "1"
set COSIM "1"
set VIVADO_SYN "0"
set VIVADO_IMPL "0"Next step is to modify the interfaces to a streaming one. There is an issue that the PYNQ DMA framework does not work with the AXI Stream Interfaces that have side-bands as evidenced here:
https://github.com/Xilinx/Vitis_Libraries/issues/28
I opened a thread here detailing the findings
https://discuss.pynq.io/t/vitis-vision-core-fails-on-pynq-v2-5-1/1822/17
The Vitis Vison IP Libraries have to be modified slightly with a custom datatype.
struct axis_t {
ap_uint<8> data;
ap_int<1> last;
};To replace the standard conversion functions:
xf::cv::AXIvideo2xfMat(_src, src_mat);
xf::cv::xfMat2AXIvideo(src_mat, _dst);with this:
template <int TYPE, int ROWS, int COLS, int NPPC>
int AXIstream2xfMat(hls::stream<axis_t<8>>& AXI_video_strm, xf::cv::Mat<TYPE, ROWS, COLS, NPPC>& img) {
axis_t<8> pixelpacket;
int res = 0;
int rows = img.rows;
int cols = img.cols;
int idx = 0;
assert(img.rows <= ROWS);
assert(img.cols <= COLS);
loop_row_axi2mat: for (int i = 0; i < rows; i++) {
loop_col_axi2mat: for (int j = 0; j < cols; j++) {
// clang-format off
#pragma HLS loop_flatten off
#pragma HLS pipeline II=1
// clang-format on
AXI_video_strm >> pixelpacket;
img.write(idx++, pixelpacket.data);
}
}
return res;
}Once this is done, the StereoLBM was tested with images with size 320x240 pixels. The reasons being that the stereo LBM algorithm uses a lot of resources so in order to fit as many features as possible it’s needed to downsize the incoming images. In addition, one has to convert these to grayscale since the stereoLBM algorithm works on grayscale images.
Once the images are resized and grayscaled they are passed to the stereolbm algorithm. The output of this is a 16-bit grayscale disparity image where the grayscale hue represent the object depth.
Once the IP core is simulated, the next step is to co-simulate it by setting the COSIM flag to 1. As you can see below it passes the hardware co-simulation by generating a disparity depth map.
The same procedure was followed for the resize IP and RGB to Gray IP.
Each of the cores was tested individually using the PYNQ framework as shown on the notebooks attached below.
4. AI SegmentationThe next step was to test the AI DPU core. Pynq 2.6. does not support the DPU as it downgrades it to version PYNQ 2.5.1.
The other option is to follow the procedure detailed on Mario Bergeron article as shown on this link:
https://www.hackster.io/AlbertaBeef/vitis-ai-1-2-flow-for-avnet-vitis-platforms-7cb3aa
As I wanted to leverage the PYNQ frameowrk in order to fuse together the data the from the stereo core with the AI core I tried to compile a segmentation network elf file for the PYNQ 2.5.1.
Download Vitis AI 1.2
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AIThen install Docker.
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo groupadd docker
docker pull xilinx/vitis-ai:latest
sudo usermod -aG docker $USER
newgrp docker
docker pull xilinx/vitis-ai:latest
docker imagesUnder the Vitis AI directory issue:
./docker_run.sh xilinx/vitis-ai:latestThen install the following packages
sudo su # you must be root
conda activate vitis-ai-tensorflow # as root, enter into Vitis AI TF (anaconda-based) virtual environment
conda install seaborn
conda install pycairo==1.18.2
conda install keras==2.2.4
# you cannot install next packages with conda, so use pip instead
pip install imutils==0.5.1
conda deactivate
exit # to exit from root
conda activate vitis-ai-tensorflowDownload the models zip file version 1.2.
The idea was to implement the segmentation network as shown on this tutorial for the ZC102 board.
https://github.com/Xilinx/Vitis-AI-Tutorials/tree/VAI-KERAS-FCN8-SEMSEG
There is an issue with the dataset given here:
https://drive.google.com/file/d/0B0d9ZiqAgFkiOHR1NTJhWVJMNEU/view
It looks like this refers to another dataset as the folder name and images are different.
In order to port it to Ultra96V2, get the.hwh file from the SD card image /boot directory.
Then create the Ultra96V2 dcf file as shown on Mario's tutorial at the end.
Create a /tutorial folder under Vitis-AI and copy the folder VAI-KERAS-FCN8-SEMSEG from the git repo.
The paths need to be changed in order to compile this.
Since, I was not able to access the correct dataset I was stuck at this point.
Provided an.elf file was generated the dpu would get loaded with this in order to generate a segmented output of the incoming frames.
This will get updated at a future point.
5. Fusing the data.Since the outputs from the stereo core is a grayscale image while the output from the segmentation core is an RGB matrix one can fuse both in a 4-dimensional matrix where the fourth channel is the depth.
The accumulate IP from the Vitis vision library was compiled in original form. This uses AXI protocol to read and write. There seems to be an issue with the accumulate core from the Vitis vision libray as it gets stuck.
A number of issues were encountered during this project so troubleshooting them took way more time than imagined. Part of this project will get updated at a future point.
Many thanks to Xilinx, Avnet and Hackster for providing the Ultra96V2.





{kind=link}
Comments
Please log in or sign up to comment.