

Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
Hybrid Blockchain Databases (HBDB) are software systems that integrate design principles and techniques from both blockchains and databases. Multiple such systems have been proposed by the database research community in the last few years (e.g., Veritas [1] and BlockchainDB [2] by Microsoft Research, BMR [3] by IBM Research, BigchainDB [4] by BigchainDB GmbH, and FalconDB [5] by Alibaba Research). Most of these systems are designed and developed by big companies such as Microsoft and IBM, and are closed-source. In an effort to evaluate the performance of these systems [6], a group of researchers from the National University of Singapore (including myself), has (re)implemented two of these systems, namely Veritas and BlockchainDB (source code here).
In this project, I refactored the above-mentioned (re)implementation of Veritas and accelerate it with a Xilinx Varium C1100 FPGA card (which I received from Xilinx as part of Adaptive Computing Challenge 2021 - thank you!). In particular, I tried to accelerate the ECDSA secp256k1 signature verification on the FPGA. Each client sending a request (Set or Get) to an HBDB server needs to sign that request with its private ECDSA key. The server verifies the signature before processing the request. This is a typical method used in blockchains (e.g., Ethereum, Hyperledger Fabric, etc.). The signing and verification steps also involve computing a digest of the request, before applying the secp256k1 methods. I use Keccak256 (similar to Ethereum) to compute a 32-byte digest of the request. At this moment, Keccak256 runs successfully on the FPGA, while secp256k1 verification failed in the implementation phase due to congestion (see more details in the Implementation section below). Hence, the results shown in Fig. 1 consider an optimistic scenario where the ECDSA verification takes half the time of Keccak256 generation, including data transfers. In this scenario, the HBDB system with ECDSA signature verification on the FPGA (green bar) achieves almost the same throughput as HBDB with no signatures (blue bar). Compared to HBDB with signature verification on the CPU (multi-threaded, red bar), the HBDB system with ECDSA signature verification on the FPGA has more than 2X higher throughput.
For details on the implementation and evaluation setup, as well as my explanation of the optimistic scenario, please see the Implementation and Evaluation sections below. I also recommend reading the Background section to understand the overall HBDB system.
The source code is available on Github: https://github.com/dloghin/accelerated-hybrid-blockchain-database.
BackgroundThe Hybrid Blockchain Database (HBDB) system in this project is somehow similar to Veritas [1]. We suppose there are some entities (e.g., organizations) that want to share a database but they do not fully trust each other. Hence, they want to keep track of the changes done to this shared database and use a blockchain ledger for this. Updates are broadcasted to all the nodes (or peers) in the system via an Apache Kafka service.
The code of this project starts from the open-source (re)implementation of Veritas (from here). This (re)implementation offers eventual consistency (that is, an update (which is a Set) operation will eventually be reflected in all the nodes), uses a Sparse Merkle Tree as the ledger data structure, and implements multi-version concurrency control (MVCC).
I did the following significant changes to the above-mentioned code:
- ECDSA secp256k1 Signatures. Each request is signed by the client and the server checks the signature. I use ECDSA secp256k1 from go-ethereum for this. This is in line with Veritas design "An authorized participant signs all interactions (queries) with the system, and the signatures are checked for authenticity during verification" [1]. Note that the (re)implementation code did not check the requests, even if the request data structure contains a field called signature. Before signing and verifying a request, a 32-byte digest of that request is computed using Keccak256, also taken from go-ethereum. Below is the Go code (CPU-only) I use to verify the signature at the server-side.
func VerifySignature(publicKeyStr, signatureStr, payload string) ([]byte, error) {
publicKey, err := hex.DecodeString(publicKeyStr)
if err != nil {
fmt.Printf("Error in decode hex %v\n", err)
return nil, err
}
signature, err := hex.DecodeString(signatureStr)
if err != nil {
fmt.Printf("Error in decode hex %v\n", err)
return nil, err
}
digest := crypto.Keccak256([]byte(payload))
if !secp256k1.VerifySignature(publicKey, digest, signature) {
return nil, errors.New("Invalid Signature")
}
return digest, nil
}- Request Broadcasting with Apache Kafka. Similar to Veritas, I rely on Kafka to order and broadcast the updates (Set requests) to the nodes. I removed the acknowledgment step from the broadcasting because it bloats the communication to O(N^2) complexity. Instead, my implementation has O(N) complexity.
- Ledger Structure. I replaced the Sparse Merkle Tree ledger with a ledger structure similar to that of Hyperledger Fabric (see here), a very popular blockchain system. As shown in Fig. 2, a block in HBDB has a block id (an index where the first block in the ledger has index 0), the transactions (or Set requests) saved as an array of bytes, and two hashes, namely a block hash (BH) and a transactions hash (TH). TH is the 32-byte Keccak256 digest of the transactions, while BH is the 32-byte Keccak256 digest of the concatenations between the BH of the previous block (PH) and TH. In this way, blocks are linked together in a ledger. In addition, we keep a persistent KV-store where each transaction (Set request) id is associated with its corresponding block id.
- Benchmark. The benchmarking program waits for the last Set request to be committed. In this way, we ensure that the system has processed all the requests, before computing the final throughput.
Baselines, Problem, and GoalWith the above code changes, I created two baselines, namely, (1) baseline 1 running only on the CPU where there is no signature generation/verification (that is, there are no cryptographic operations), and (2) baseline 2 running only on the CPU where each request is signed by the client and verified by the server using ECDSA secp256k1. The performance of these two baselines with increasing number of clients (threads) is shown in Fig. 3 and Fig. 4. As expected, baseline 1 has higher throughput since there is no signature verification. It achieves a maximum throughput of 28935 req/s with 4 clients and 128 threads per client. In contrast, baseline 2 achieves a maximum of 19251 req/s with 4 clients and 64 threads per client. Similarly, on one HBDB node, baseline 1 and baseline 2 exhibit a maximum of 20256 and 9639 req/s, respectively. Hence, the impact of signature verification is significant.
Given this observation, my main goal is to see if accelerating both the digest generation and signature verification with the Verium C1100 FPGA can improve the throughput, and by how much. Ideally, the throughput of the accelerated HBDB should be close to that of baseline 1, as shown in Fig. 3 and Fig. 4.
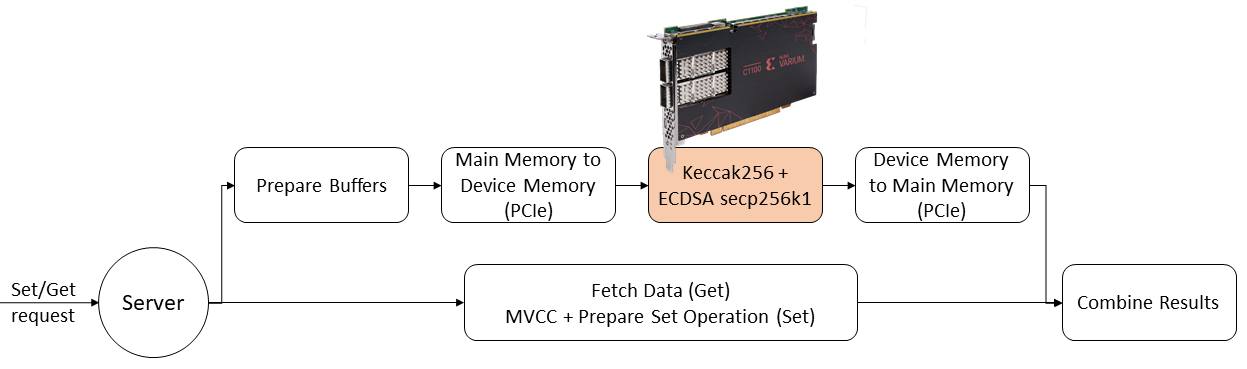
DesignThere are two key sections of the code that can be accelerated on the FPGA. These are (1) the signature verification of the requests and (2) the generation of block and transactions hashes. Moreover, these operations can be done in parallel with other operations that are more suitable to run on the CPU. As shown in Fig. 4, the verification of the signatures can be done in parallel with (a) fetching the data for Get requests or (b) checking the MVCC condition and preparing the operation for Set requests. (Note that MVCC also implies fetching data from the local database, an operation which is more suitable to be run on the CPU.)
The generation of the block hash and transactions hash can be done in parallel with saving the block structure and transactions ids to the persistent database, as shown in Fig. 5.
I implemented the acceleration code in C/C++ starting from the examples provided by Xilinx in the Vitis_Libraries repository. Xilinx already provides code for Keccak256 (here) and ECDSA secp256k1 (here). I studied the code of the benchmarks (here) because I needed both the kernel (running on the FPGA) and the driver (running on the host). The source code for the Keccak256 is under accelerator/hw/keccak256. Below I list the kernel code.
#include <ap_int.h>
#include <hls_stream.h>
#include "xf_security/keccak256.hpp"
void readLenM2S(int n,
ap_uint<128>* msgLen,
hls::stream<ap_uint<128>>& msgLenStrm,
hls::stream<bool>& endMsgLenStrm) {
// n is the size of msgLen array (== num)
for (int i = 0; i < n; i++) {
#pragma HLS pipeline ii = 1
msgLenStrm.write(msgLen[i]);
endMsgLenStrm.write(0);
}
endMsgLenStrm.write(1);
}
void readDataM2S(int n,
ap_uint<64>* msg,
hls::stream<ap_uint<64>>& msgStrm) {
// n is the size of msg array (== size)
for (int i = 0; i < n; i++) {
#pragma HLS pipeline ii = 1
msgStrm.write(msg[i]);
}
}
void writeS2M(int n, hls::stream<ap_uint<256>>& digestStrm, hls::stream<bool>& endDigestStrm, ap_uint<256>* digest) {
for (int i = 0; i < n; i++) {
#pragma HLS pipeline ii = 1
endDigestStrm.read();
digest[i] = digestStrm.read();
}
endDigestStrm.read();
}
/*
* num - input size (number of elements)
* msg - input message
* msgLen - input message lengths (elements)
* digest - output (32 bytes = 256 bits per digest)
*/
extern "C" void keccak256_kernel(
int num, int size,
ap_uint<64>* msg, ap_uint<128>* msgLen, ap_uint<256>* digest) {
#pragma HLS INTERFACE m_axi offset = slave latency = 64 \
num_write_outstanding = 16 num_read_outstanding = 16 \
max_write_burst_length = 64 max_read_burst_length = 64 \
bundle = gmem0 port = msg
#pragma HLS INTERFACE m_axi offset = slave latency = 64 \
num_write_outstanding = 16 num_read_outstanding = 16 \
max_write_burst_length = 64 max_read_burst_length = 64 \
bundle = gmem1 port = msgLen
#pragma HLS INTERFACE m_axi offset = slave latency = 64 \
num_write_outstanding = 16 num_read_outstanding = 16 \
max_write_burst_length = 64 max_read_burst_length = 64 \
bundle = gmem1 port = digest
#pragma HLS INTERFACE s_axilite port = num bundle = control
#pragma HLS INTERFACE s_axilite port = size bundle = control
#pragma HLS INTERFACE s_axilite port = msg bundle = control
#pragma HLS INTERFACE s_axilite port = msgLen bundle = control
#pragma HLS INTERFACE s_axilite port = digest bundle = control
#pragma HLS INTERFACE s_axilite port = return bundle = control
#pragma HLS dataflow
hls::stream<ap_uint<64> > msgStrm("s1");
hls::stream<ap_uint<128> > msgLenStrm("s2");
hls::stream<bool> endMsgLenStrm("s3");
hls::stream<ap_uint<256> > digestStrm("s4");
hls::stream<bool> endDigestStrm("s5");
#pragma HLS stream variable = msgStrm depth = 16384
#pragma HLS stream variable = msgLenStrm depth = 128
#pragma HLS stream variable = digestStrm depth = 128
#pragma HLS stream variable = endMsgLenStrm depth = 128
#pragma HLS stream variable = endDigestStrm depth = 128
readDataM2S(size, msg, msgStrm);
readLenM2S(num, msgLen, msgLenStrm, endMsgLenStrm);
xf::security::keccak_256(msgStrm, msgLenStrm, endMsgLenStrm, digestStrm, endDigestStrm);
writeS2M(num, digestStrm, endDigestStrm, digest);
}The idea is simple: in a dataflow manner, the input data (messages representing the requests for which we need to compute the digests) flows through the xf::security::keccak_256 processor. The data is read from memory buffers into streams, and at the end, the result stream is saved into memory buffers. This is done with the helper functions readDataM2S(),readLenM2S() and writeS2M().
The code for ECDSA verification is under accelerator/hw/ecdsa_secp256k1, and the kernel code is listed below.
#include "xf_security/ecdsa_secp256k1.hpp"
extern "C" {
const ap_uint<256> r = ap_uint<256>("0xf3ac8061b514795b8843e3d6629527ed2afd6b1f6a555a7acabb5e6f79c8c2ac");
const ap_uint<256> s = ap_uint<256>("0x8bf77819ca05a6b2786c76262bf7371cef97b218e96f175a3ccdda2acc058903");
const ap_uint<256> Qx = ap_uint<256>("0x1ccbe91c075fc7f4f033bfa248db8fccd3565de94bbfb12f3c59ff46c271bf83");
const ap_uint<256> Qy = ap_uint<256>("0xce4014c68811f9a21a1fdb2c0e6113e06db7ca93b7404e78dc7ccd5ca89a4ca9");
void verify_kernel(const ap_uint<256>* hash,
ap_uint<8>* results, // Output Results
int elements // Number of elements
) {
#pragma HLS INTERFACE m_axi offset = slave latency = 32 num_write_outstanding = 1 num_read_outstanding = \
32 max_write_burst_length = 2 max_read_burst_length = 16 bundle = gmem0 port = hash
#pragma HLS INTERFACE m_axi offset = slave latency = 32 num_write_outstanding = 32 num_read_outstanding = \
1 max_write_burst_length = 16 max_read_burst_length = 2 bundle = gmem1 port = results
#pragma HLS INTERFACE s_axilite port = elements bundle = control
#pragma HLS INTERFACE s_axilite port = hash bundle = control
#pragma HLS INTERFACE s_axilite port = results bundle = control
#pragma HLS INTERFACE s_axilite port = return bundle = control
xf::security::ecdsaSecp256k1<256> processor;
processor.init();
for (int i = 0; i < elements; i++) {
#pragma HLS UNROLL factor=10
results[i] = processor.verify(r, s, hash[i], Qx, Qy);
}
}
}The input represents the signatures of the requests and the output is an array of booleans, where true means the signature is verified, and false otherwise. Unfortunately, Vitis + Vivado are not able to complete the implementation phase, due to the error below:
===>The following messages were generated while processing /home/dumi/git/Vitis_Libraries/security/L1/benchmarks/ecdsa_secp256k1/_x_temp.hw.xilinx_u55n_gen3x4_xdma_1_202110_1/link/vivado/vpl/prj/prj.runs/impl_1 :
ERROR: [VPL 18-1000] Routing results verification failed due to partially-conflicted nets (Up to first 10 of violated nets): level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U2/buff1_reg__3_i_15__0_psdsp_n_7 level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U2/buff0_reg__1_i_8__0_psdsp_n_7 level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U2/buff0_reg__1_i_7__0_psdsp_n_7 level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U2/buff0_reg__1_i_7__0_psdsp_n_1 level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/ap_CS_fsm_state114_repN_3 level0_i/ulp/verify_kernel/inst/control_s_axi_U/elements[15] level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U4/buff0_reg__8_i_4__0_psdsp_n_5 level0_i/ulp/verify_kernel/inst/grp_verify_256_s_fu_232/grp_productMod_p_fu_548/mul_128ns_128ns_256_5_1_U4/buff0_reg__8_i_6__0_psdsp_n_5 level0_i/ulp/ulp_ucs/inst/aclk_hbm_hierarchy/clkwiz_hbm/inst/CLK_CORE_DRP_I/SEN level0_i/ulp/ulp_ucs/inst/aclk_hbm_hierarchy/clkwiz_hbm/inst/CLK_CORE_DRP_I/S2_CLKFBOUT_FRAC_EN
ERROR: [VPL 60-773] In '/home/dumi/git/Vitis_Libraries/security/L1/benchmarks/ecdsa_secp256k1/_x_temp.hw.xilinx_u55n_gen3x4_xdma_1_202110_1/link/vivado/vpl/runme.log', caught Tcl error: problem implementing dynamic region, impl_1: route_design ERROR, please look at the run log file '/home/dumi/git/Vitis_Libraries/security/L1/benchmarks/ecdsa_secp256k1/_x_temp.hw.xilinx_u55n_gen3x4_xdma_1_202110_1/link/vivado/vpl/prj/prj.runs/impl_1/runme.log' for more information
WARNING: [VPL 60-732] Link warning: No monitor points found for BD automation.
ERROR: [VPL 60-704] Integration error, problem implementing dynamic region, impl_1: route_design ERROR, please look at the run log file '/home/dumi/git/Vitis_Libraries/security/L1/benchmarks/ecdsa_secp256k1/_x_temp.hw.xilinx_u55n_gen3x4_xdma_1_202110_1/link/vivado/vpl/prj/prj.runs/impl_1/runme.log' for more information
ERROR: [VPL 60-1328] Vpl run 'vpl' failed
ERROR: [VPL 60-806] Failed to finish platform linker
INFO: [v++ 60-1442] [13:47:21] Run run_link: Step vpl: Failed
Time (s): cpu = 00:02:04 ; elapsed = 05:31:10 . Memory (MB): peak = 2061.969 ; gain = 0.000 ; free physical = 2502 ; free virtual = 78202
ERROR: [v++ 60-661] v++ link run 'run_link' failed
ERROR: [v++ 60-626] Kernel link failed to complete
ERROR: [v++ 60-703] Failed to finish linking
INFO: [v++ 60-1653] Closing dispatch client.This has to do with congestion. I tried to follow this guide. Even with additional parameters, such as AggressiveExplore and SpreadLogic_high, the implementation fails.
--vivado.prop run.impl_1.STEPS.PLACE_DESIGN.ARGS.DIRECTIVE=AltSpreadLogic_high --vivado.prop run.impl_1.STEPS.PHYS_OPT_DESIGN.ARGS.DIRECTIVE=AggressiveExploreHence, I will only evaluate the Keccak256 on the FPGA.
Code Integration
On the host side, I wrote a driver program in C++ to interact with the kernel (see accelerator/sw/keccak256). Then, I compiled this C++ code into a shared library and I wrote a Go wrapper (see src/accelerator/accelerator.go) to access the kernel from Go. In Go, I have the following function which performs the acceleration on the FPGA:
func VerifySignatureBatchAccelerator(setRequests *pbv.BatchSetRequest, getRequests *pbv.BatchGetRequest, lock *sync.Mutex) ([]byte, []bool) {
// protect the call with a lock
lock.Lock()
defer lock.Unlock()
...
// prepare data buffers and send data to FPGA
...
size := C.send_data(dptr, sptr, num)
// call kernel
C.run_kernel(num, C.int(size))
// get digests (hashes)
rptr := C.get_results(num)
hashes := C.GoBytes(unsafe.Pointer(rptr), 32*num)
...
}
ap_uint<64>A few things to note:
- The call needs to be protected with a lock (similar to synchronized in Java), otherwise, multiple threads will access the C++ driver/FPGA at the same time resulting in deadlock/crash.
- The data needs to be aligned at 8 bytes (64 bits) because the xf::security::keccak_256 kernel uses ap_uint<64> elements. Otherwise, you may experience deadlocks in the kernel. Hence, I pad the buffers with additional zeros to align them at 8 bytes.
EvaluationI evaluate the impact of FPGA acceleration by measuring the throughput and comparing it with the two baselines mentioned above. Because I have only one Varium C1100 FPGA, I measure the performance of HBDB with a single node. More impressive throughputs are expected when the HBDB has more accelerated nodes.
System Setup
The experiments are carried out on the following system:
CPU: AMD Ryzen 5 3600X (6 cores, 12 threads) @ 3.8GHz
RAM: 32 GB DDR4
OS: Ubuntu 20.04.4 LTS, Linux kernel 5.8.0-63-generic
Go: 1.16.10
Vitis: 2021.2, Vivado: 2021.2 (with 2021.2.1 update)
XRT: 2.11.634
FPGA Platform: xilinx_u55n_gen3x4_xdma_1_202110_1Scenarios
Due to the above-mentioned issue with implementing the ECDSA signature verification on the FPGA, I have to "emulate" this step by introducing an artificial delay in the code. To get a feel of the magnitude of the difference between Keccak256 generation and secp256k1 verification, I created a small benchmarking program for the CPU-only execution (see microbench/keccak-secp256k1-cpu.go). The results (listed below) show that ECDSA verification is much faster than Keccak256 generation.
$ cd microbench
$ ./run-cpu-benchmarks.sh
Load data ...
Start running ...
Time of Keccak with 6 concurrency to handle 100000 requests: 0.0392581 s
...
Time of ECDSA Sign with 6 concurrency to handle 100000 requests: 0.7045437 s
...
Time of ECDSA Verify with 6 concurrency to handle 100000 requests: 0.0017899 sEven if FPGA and CPU are so different, I do not expect ECDSA verification to take much longer on the FPGA compared to Keccak256 digest generation. Hence, my optimistic scenario is that ECDSA verification will take half the time of the Keccak256 on the FPGA. In contrast, the pessimistic scenario considers similar durations. I introduced an artificial delay in the code, as listed below (see src/accelerator/accelerator.go).
// optimistic
time.Sleep(delta / 2)
// pessimistic
time.Sleep(delta)Results
With the above scenarios in mind, the results presented in Fig. 6 highlight that indeed, the time taken by the ECDSA verification can have a significant impact on the performance of the HBDB. If the ECDSA verification takes as long as the Keccak256 verification (pessimistic), HBDB with FPGA archives a throughput of 16588 req/s, which is 1.7X higher compared to baseline 2. In the optimistic scenario, HBDB with FPGA archives a throughput of 20586 req/s, which is 2.1X higher compared to baseline 2.
Reproducing the Results
To reproduce the results, you need to install Varium C1100 on your computer (on a PCIe slot). You can follow UG1525 from Xilinx. Then install XRT and Vitis. Also, make sure your kernel is 5.8. With newer kernels, I experienced some errors in the XRT code.
Make sure you have go (Golang) installed. I recommend go1.16.0. Export the variables for the environment, and then run the steps:
export GOROOT=<path-to-go>
export GOPATH=<path-to-gopath>
export PATH=$PATH:$GOROOT/bin
source <path-to-Vitis>/Vitis/2021.2/settings64.sh
source /opt/xilinx/xrt/setup.sh
git clone https://github.com/dloghin/accelerated-hybrid-blockchain-database.git
cd accelerated-hybrid-blockchain-database/scripts
./install_dependencies.sh
./build_binaries.sh
./gen_ycsb_data.sh
./preprocess_ycsb_data.sh
cd ../docker/hbdb
./build_docker.sh
cd ../../scripts
./run_benchmark.sh
# or, to run on more threads
./run_benchmark.sh allThe results are in folders of the form "logs-hbdb-2022-04-01-11-38-24". You can list "hbdb-clients-*.txt", such as
$ cat logs-hbdb-2022-04-01-11-38-24/hbdb-clients-64.txt
...
Throughput of 2 drivers with 64 concurrency to handle 99900 requests: 19533 req/s
Average latency: 6.080641371371371 ms
Batch size: 100Besides the conclusion that Varium C1100 (and for that matter, other Alveo FPGA cars), can significantly accelerate the cryptographic operations in hybrid blockchain databases, I would like to list some of my personal conclusions on working on this project. On the upside, Xilinx and AMD provide very powerful hardware accompanied by state-of-the-art software tools. It is a lot of fun working on this king of hardware-software projects. On the downside, I would have expected the tools to be able to find a suitable placement for the ECDSA secp256k1 logic to avoid congestion. Requiring the user/developer to manually place the logic would significantly reduce the usability of the tools and the hardware, especially when those users do not have a strong background in FPGA. I hope AMD-Xilinx will consider this and improve the software tools such that more developers can enjoy the power of the FPGA while programming in high-level languages.
References[1] J. Gehrke et al., "Veritas: Shared Verifiable Databases and Tables in the Cloud", In Proc. of 9th Biennial Conference on Innovative Data, 2019.
[2] M. El-Hindi et al., "BlockchainDB: A Shared Database On Blockchains", In Proc. of VLDB Endowment, 12(11), pages 1597-1609, 2019.
[3] S. Nathan et al., "Blockchain Meets Database: Design And Implementation Of A Blockchain Relational Database", In Proc. of VLDB Endowment, 12(11), pages 1539-1552, 2019.
[4] BigchainDB GmbH, "BigchainDB 2.0 The Blockchain Database", Technical Report, 2018.
[5] Y. Peng et al., "Falcondb: Blockchain-Based Collaborative Database", In Proc. of ACM SIGMOD International Conference on Management of Data, pages 637-652, 2020.
[6] Z. Ge et al., "Hybrid Blockchain Database Systems: Design and Performance", In Proc. of VLDB Endowment, 15(5), pages 1092 - 1104, 2022.
{kind=link}

Comments
Please log in or sign up to comment.