



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
This is a computer vision application to keep track of instruments and materials used during surgery as an extra layer of control to avoid Retained Surgical Bodies. To achieve this an object detection model was created using over 30, 000 annotated synthetic training images generated with NVIDIA Omniverse Replicator. The dataset was used to fine-tune an object detection model with Edge Impulse Studio using integrated NVIDIA TAO transfer learning. Further, the model was validated on synthetic scenes using Edge Impulse Omniverse extension. Finally the model was built, ready to be deployed NVIDIA Jetson Orin Nano for use with camera feeds from surgical lights in operating rooms (OR).
Project resourcesKaggle dataset 30, 000 images in 320*320 pixel RGB, including labels
Github project code repository
Edge Impulse Studio project repository
The problemExtensive routines are in place pre-, during, and post-operation to make sure no unintentional items are left in the patient. In the small number of cases when items are left the consequences can be severe, in some cases fatal.
In the following drawing we see how equipment and disposable materials are typically organized during surgery. Tools are pre-packaged in sets for the appropriate type of surgery and noted when organized on trays or tables. Swabs are packaged in numbers and contain tags that are noted and kept safe. When swabs are used they are displayed individually in transparent pockets on a stand so they can be counted and checked with the tags from the originating package. Extensive routines are in place to continuously count all equipment used; still errors occur an estimated rate between 0.3 and 1 per 1000 abdominal operations.
Existing solutions are mainly based on either x-ray or RFID. With x-ray, the patient needs to be scanned using a scanner on wheels. Metal objects obviously will be visible, while other items such as swabs needs to have metal strips woven to be detected and the surgery team has to wear lead aprons. Some items have passive RFID-circuits embedded and can be detected by a handheld scanner.
This project started as a proof-of-concept demonstrating that an object detection model could be deployed and run on heavily constrained hardware, an Arduino Nicla Vision, as a wearable. This was documented on Edge Impulse. Many operating rooms (OR) are equiped with adjustable lights with a camera embedded. A video feed from such a camera could make a viable source for the object detection model. The wearable PoC proved a success and sparked the question: could the work be transferred to an application that could utilize more powerful hardware and greater video resolution? This article documents the steps involved in transferring the application to a model that can run on a NVIDIA Jetson with potential to be hooked up to a surgical camera feed.
Most of the tools used in surgery have a chrome surface. Due to the reflective properties of chrome, especially the high specular reflection and highlights, a given item's features will vary highly judged by its composition of pixels, in this context known as visual features.
More distinct types of objects can be added to the training data simply by importing 3D models. The goal of the device isn't to identify specific types of items, but rather to make the surgery team aware if item count changes from surgery start to end. With this approach we can group items with similar shapes and surfaces.
Edge Impulse Studio offers a web-based development platform for creating machine learning solutions from concept to deployment.
Using the camera on the intended device for deployment around 600 images were initially captured and labeled. Most images contained several items and a fraction were unlabeled images of unrelated background objects.
The model trained on this data was quickly deemed useless in detecting reflective items but provided a nice baseline for the proceeding approaches.
To isolate the chrome surfaces as a problematic issue, a number of chrome instruments were spray painted matte and a few plastic and cloth based items were used to make a new manually captured and labeled dataset of the same size. For each image the items were scattered and the camera angle varied.
A crucial part of any ML-solution is the data the model is trained, tested and validated on. In the case of a visual object detection model this comes down to a large number of images of the objects to detect. In addition each object of interest in each image needs to be labeled. Edge Impulse offers an intuitive tool for drawing boxes around the objects in question and to define labels. On large datasets manual labeling can be a daunting task, thankfully EI offers an auto-labeling tool. Other tools for managing datasets offer varying approaches for automatic labeling, for instance using large image datasets. However, often these datasets are too general and fall short for specific use cases.
NVIDIA Omniverse ReplicatorOne of the main goals of this project is to explore creating synthetic object images that come complete with labels. This is achieved by creating a 3D scene in NVIDIA Omniverse and using it's Replicator synthetic data generation toolbox to create thousands of slightly varying images, a concept called domain randomization. With a NVIDIA RTX 3090 graphics card from 2020 it is possible to produce about 2 ray-traced images per second. Thus, creating 10, 000 images would take about 5 hours.
We will be walking through the following steps to create an object detection model that can run on a NVIDIA Jetson Orin Nano. The 3D models used to generate the training images are not distributed in the project repository due to limitations in licencing, the models can be purchased at TurboSquid. An updated Python environment with Visual Studio Code is recommended. A 3D geometry editor such as Blender is needed if object 3D models are not in USD-format (Universal Scene Description).
- Installing Omniverse Code, Replicator and setting up debugging with Visual Studio Code
- Creating a 3D stage/scene in Omniverse
- Working with 3D models in Blender
- Importing 3D models in Omniverse, retaining transformations, applying materials
- Setting metadata on objects
- Creating script for domain randomization
- Creating label file for Edge Impulse Studio
- Creating an object detection project in Edge Impulse Studio and uploading dataset
- Training, improving and deploying model to device
- Install Omniverse from NVIDIA.
- Install Code: Open Omniverse Launcher, go to Exchange, install Code.
- Launch Code from NVIDIA Omniverse Launcher.
- Go to Window->Extensions and install Replicator
- Create a new stage/scene (USD-file)
- Create a textured plane that will be a containment area for scattering the objects
- Create a larger textured plane to fill the background
- Add some lights
If you have a hefty heat producing GPU next to you, you might prefer to reduce the FPS limit in the viewports of Code. It may default to 120 FPS, generating a lot of heat when the viewport is in the highest quality rendering modes. Set "UI FPS Limit" to something like 60 or 30. This setting unfortunately does not persist between sessions, so we have to repeat this everytime projects open.
The objects we want to be able to detect need to be represented with a 3D model and a surface (material). Omniverse provides a library of ready-to-import assets, further models can be created using editors such as Blender or purchased on sites such as TurboSquid.
A scene containing multiple geometric models should be exported on an individual model basis, with USD-format as output.
Omniverse has recently received limited support in importing BSDF material compositions, but this is still experimental. In this project materials or textures were not imported directly.
Importing 3D models in Omniverse, retaining transformations, applying materialsTo avoid overwriting any custom scaling or other transformations set on exported models it is advisable to add a top node of type Xform on each model hierarchy. Later we can move the object around without loosing adjustments.
The replicator toolbox has a function for scattering objects on a surface in it's API. To (mostly) avoid object intersection a few improvements can be made. In the screenshot a basic shape has been added as a bounding box to allow some clearance between objects and to make sure thin objects are more appropriately handled while scattering. The bounding box can be set as invisible.
For the chrome surfaces a material from one of the models from the library provided through Omniverse was reused, look for http://omniverse-content-production.s3-us-west-2.amazonaws.com/Materials/Base/Metals/Chrome/ in the Omniverse Asset Store. Remember to switch to "RTX - Interactive" rendering mode to see representative ray-tracing results, "RTX - Real-Time" is a simplified rendering pipeline.
For the cloth based materials some of the textures from the original models were used, more effort in setting up the shaders with appropriate texture maps could improve the results.
To be able to produce images for training and include labels we can use a feature of Replicator toolbox found under menu Replicator->Semantics Schema Editor.
Here we can select each top node representing an item for object detection and adding a key-value pair. Choosing "class" as Semantic Type and e.g. "tweezers" as Semantic Data enables us to export these strings as labels later. The UI could benefit from a bit more exploration in intuitive design, as it is easy to misinterpret what fields shows the actual semantic data set on an item, an what fields carry over intended to make labeling many consecutive items easier.
Semantics Schema Editor may also be used with multiple items selected. It also has handy features to use the names of the nodes for automatic naming.
Creating script for domain randomizationThis part describes how to write a script in Python for randomizing the content of the images we will produce with Omniverse Code. We could choose to start with an empty stage and programatically load models (from USD-files), lights, cameras and such. With a limited number of models and lights we will proceed with adding most items to the stage manually as described earlier. Our script can be named anything, ending in.py and preferably placed close to the stage USD-file. The following is a description of such a script replicator_init.py:
To keep the items generated in our script separate from the manually created content we start by creating a new layer in the 3D stage:
python
with rep.new_layer():Next we specify that we want to use ray tracing as our image output. We create a camera and hard code the position. We will point it to our items for each render later. Then we use our previously defined semantics data to get references to items, background items and lights for easier manipulation. Lastly we define our render output by selecting the camera and setting the desired resolution. We set the output resolution at 320x320 pixels. Edge Impulse Studio will take care of scaling the images to the desired size should we use images of different size than the configured model size.
rep.settings.set_render_pathtraced(samples_per_pixel=64)
camera = rep.create.camera(position=(0, 24, 0))
tools = rep.get.prims(semantics=[("class", "tweezers"), ("class", "scissors"), ("class", "scalpel"), ("class", "sponge")])
backgrounditems = rep.get.prims(semantics=[("class", "background")])
lights = rep.get.light(semantics=[("class", "spotlight")])
render_product = rep.create.render_product(camera, (320, 320))Due to the asynchronous nature of Replicator we need to define our randomization logic as call-back methods by first registering them in the following fashion:
rep.randomizer.register(scatter_items)
rep.randomizer.register(randomize_camera)
rep.randomizer.register(alternate_lights)Before we get to the meat of the randomization we define what will happen during each render:
with rep.trigger.on_frame(num_frames=10000, rt_subframes=20):
rep.randomizer.scatter_items(tools)
rep.randomizer.randomize_camera()
rep.randomizer.alternate_lights()num_frames defines how many renders we want. rt_subframes lets the render pipeline proceed a number of frames before capturing the result and passing it on to be written to disk. Setting this high will let advanced ray tracing effects such as reflections have time to propagate between surfaces, though at the cost of higher render time. Each randomization sub-routine will be called, with optional parameters.
To write each image and semantic information to disk we use a provided API. We could customize the writer but as of Replicator 1.9.8 on Windows this resulted in errors. We will use "BasicWriter" and rather make a separate script to produce a label format compatible with EI.
writer = rep.WriterRegistry.get("BasicWriter")
writer.initialize(
output_dir="out",
rgb=True,
bounding_box_2d_tight=True)
writer.attach([render_product])
asyncio.ensure_future(rep.orchestrator.step_async())Here rgb tells the API that we want the images to be written to disk as png-files, bounding_box_2d_tight that we want files with labels (from previously defined semantics) and bounding boxes as rectangles. The script ends with running a single iteration of the process in Omniverse Code, so we can visualize the results.
The bounding boxes can be visualized by clicking the sensor widget, checking "BoundingBox2DTight" and finally "Show Window".
Only thing missing is defining the randomization logic:
def scatter_items(items):
table = rep.get.prims(path_pattern='/World/SurgeryToolsArea')
with items as item:
carb.log_info("Tool: " + tool)
logger.info("Tool: " + tool)
rep.modify.pose(rotation=rep.distribution.uniform((0, 0, 0), (0, 360, 0)))
rep.randomizer.scatter_2d(surface_prims=table, check_for_collisions=True)
return items.node
def randomize_camera():
with camera:
rep.modify.pose(
position=rep.distribution.uniform((-10, 50, 50), (10, 120, 90)),
look_at=(0, 0, 0))
return camera
def alternate_lights():
with lights:
rep.modify.attribute("intensity", rep.distribution.uniform(10000, 90000))
return lights.nodeFor scatter_items we get a reference to the area that will contain our items. Each item is then iterated so that we can add a random rotation (0-360 degrees on the surface plane) and use scatter_2d to randomize placement. For the latter, surface_prims takes an array of items to use as possible surfaces, check_for_collisions tries to avoid overlap. The order of operations is important to avoid overlapping items.
For the camera we simply randomize the position in all 3 axis and make sure it points to the center of the stage.
With the lights we randomize the brightness between a set range of values.
Note that in the provided example rendering images and labels is separated between the actual objects we want to be able to detect and background items for contrast. The process would run once for the surgery items, then the following line would be changed from
rep.randomizer.scatter_items(tools)to
rep.randomizer.scatter_items(backgrounditems)When rendering the items of interest the background items would have to be hidden, either manually or programatically, and vice versa. The output path should also be changed to avoid overwriting the output.
Whether the best approach for training data is to keep objects of interest and background items in separate images or to mix them is debated, both with sound reasoning. In this project the best results were achieved by generating image sets of both approaches.
Edge Impulse Studio supports a wide range of image labeling formats for object detection. Unfortunately the output from Replicator's BasicWriter needs to be transformed so it can be uploaded either through the EI Omniverse extension, web interface or via web-API.
Provided is a simple Python program, basic_writer_to_pascal_voc.py. A simple prompt was written for ChatGPT describing the output from Replicator and the desired results described at EI. Run the program from shell with
Copy
python basic_writer_to_pascal_voc.py <input_folder>or debug from Visual Studio Code by setting input folder in launch.json like this:
Copy
"args": ["../out"]This will create a file bounding_boxes.labels that contains all labels and bounding boxes per image.
Look at the provided object detection Edge Impulse project or follow a guide to create a new object detection project.
For a project intended to detect objects with reflective surfaces a large number of images is needed for training, but the exact number depends on a lot of factors and experimentation should be expected. It is advisable to start relatively small, say 1, 000 images of the objects to be detected. For this project over 30, 000 images were generated.
EI creates unique identifiers per image, so you can run multiple iterations to create and upload new datasets, even with the same file names. Just upload all the images from a batch together with the bounding_boxes.labels file.
This way we can effortlessly produce thousands of labeled images and witness how performance on detecting reflective objects increases. Keep in mind to try to balance the number of labels for each class.
For uploading the images we have a few options.
Uploading images using Edge Impulse extension for Omniverse IsaacThe Edge Impulse Omniverse Isaac extension is really handy when creating synthetic training images in Omniverse. We will get back to it later when testing the model. It can connect to your Edge Impulse project so you can upload any generated images. As of March 2024 you have to clone the extension repo and add to Omniverse manually, follow the steps in the repo. Once registrered it can be enabled to find the extension UI.
- Connect to your Edge Impulse project by setting your API key (this key is obtained from your Edge Impulse project Dashboard > Keys > API Keys), then click Connect.
- Once your project is connected to your Edge Impulse Omniverse extension, select the Data Upload, then specify your dataset's local path on your computer, select the dataset category to upload to (training, testing, or anomaly), then click Upload to Edge Impulse:
Since we have generated both synthetic images and labels, we can use the CLI tool from Edge Impulse to efficiently upload both. Use
edge-impulse-uploader --category split --directory [folder]
to connect to account and project and upload image files and labels in bounding_boxes.labels. To switch project first do
edge-impulse-uploader --clean
At any time we can find "Perform train/test split" under "Danger zone" in project dashboard.
If in doubt you can always upload images and labels in Edge Impulse Studio under "Data acquisition".
Finally we can design and train our object detection model. Determining optimal Neural Network architecture and parameters can be complex. Luckily EON Tuner can do the heavy lifting for us by finding the best suited model architecture. For specific constraints EON Tuner Search Space allows us to narrow options.
EON Tuner and Search SpaceWe can start EON Tuner to find appropriate settings simply by specifying target device and a rough latency.
EON Tuner Search Space further lets us narrow parameters.
Refer to the documentation for defining block parameters.
Model trainingWith the tools to effortlessly create as much training data as we want at our disposal, we have a lot of options available for what approach to choose. For instance, we could train a model using FOMO architecture from scratch, supplying as much data as needed to achieve good results.
Alteratively we can fine-tune an existing object detection model with a fraction of the images needed in the previous architecture. Make no mistake, capturing just 1000 images and manually labeling 5-6 items in each image is increadibly labor intensive, so being able to generate the data is extremely useful in both cases.
Fine-tuning an existing model poses it's own set of parameters to experiment with. For instance, "Freeze blocks" allows us to specify what initial CNN blocks we want to transfer unaltered from the backbone in our new model. The available IDs for each model vary and needs to be referenced for the selected architecture. For instance, here we can find the available block IDs for the different backbones when fine-tuning a SSD model.
Edge Impulse EON Tuner Search space can help us find suitable parameters automatically.
Transfer learning in the context of computer vision and object detection involves taking a model pre-trained on a large dataset and adapting it to a specific object detection task. This approach leverages the model's learned features, such as edges, textures, and shapes, which are common across different visual recognition tasks, to achieve higher performance with less data and training time on a new task.
A critical aspect of transfer learning is the concept of "freezing" the initial layers of the pre-trained model. In deep learning models, the initial layers capture general features (e.g., edges and textures) that are applicable across various tasks. By freezing these layers, their weights are kept unchanged during the training process on the new task.
The integration of NVIDIA TAO in Edge Impulse Studio facilitates the building of efficient models faster by combining the power of transfer learning and the latest NVIDIA TAO models. These can be deployed across the entire Edge Impulse ecosystem of devices, silicon, and sensors.
A really convenient feature in Edge Impulse extension for Omniverse Isaac is the ability to test the object detection model on a synthetic 3D scene as a digital twin. Just load up the scene that was created for generating annotated training images in Isaac, enable the extension as described earlier and hit "Classify". You could also use generic pre-built 3D scenes found in Omniverse and import your 3D models to simulate different environments. For this to work we only have to build a WebAssembly (wasm) target in Edge Impulse Studio under "Deployment".
Now we can navigate our 3D scene and test the model on any view. We can even compare the model inference output side-by-side to the bounding boxes in Omniverse.
In the image above on the left square image we see model inference (bounding boxes, labels and confidence score in red) side-by-side with visualization of the bounding boxes of the actual models in the scene. This enables efficient model development iterations and can uncover a lot of issues without having to deploy the model to device and testing in a real environment.
Model improvementsThe first version of the object detection model showed great results when tested on witheld images from the same generation process. However, when tested in both virtual environment using the Edge Impulse extension for Omniverse and on real surgery equipment it was soon clear that it would produce many false positives when exposed to background items. To remidy this a new 10, 000 items dataset was generated where the objects of interest were put on top of random background images.
For this 5, 000 images were downloaded from the COCO 2017 dataset and the replicator program extended as such:
import os
def randomize_screen(screen, texture_files):
with screen:
# Let Replicator pick a random texture from list of .jpg-files
rep.randomizer.texture(textures=texture_files)
return screen.node
# Define what folder to look for .jpg files in
folder_path = 'C:/Users/eivho/source/repos/icicle-monitor/val2017/testing/'
# Create a list of strings with complete path and .jpg file names
texture_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.jpg')]
# Register randomizer
rep.randomizer.register(randomize_screen)
# For each frame, call randomization function
with rep.trigger.on_frame(num_frames=2000, rt_subframes=50):
# Other randomization functions...
rep.randomizer.randomize_screen(screen, texture_files)Adding this to the training/testing sets greatly increased performance when bacground objects are in view. Testing in a real surgery environment would determine if more of this type of images are needed.
In validating the model in Omniverse we have already deployed it in a form that can run on Windows or Linux bound by CPU. In the first version of the project the model was deployed to run on MCU, a Arduino Nicla Vision. Now we want to utilize the hardware capabilities of a NVIDIA Jetson Orin Nano, especially increased RAM size and the GPU, so we can run inference on a video feed from cameras mounted in operation lights.
Deploy model to Jetson Orin Nano using edge-impulse-linuxFirst make sure to follow the NVIDIA Jetson Getting Started Guide to flash a SD-card with the Ubuntu OS provided by NVIDIA with Jetpack (5.1.2 for Orin as of March 2024) and finish setup.
Following the Edge Impulse documentation for deployment to Jetson we must download the proper firmware for the Jetson:
wget -q -O - https://cdn.edgeimpulse.com/firmware/linux/jetson.sh | bashWe can use the generic Linux wrapper to test the model by running the edge-impulse-linux CLI tool. This will start a wizard which will ask you to log in, and choose an Edge Impulse project. If you want to switch projects run the command with --clean.
To run your impulse locally, just connect to your Jetson again, and run:
edge-impulse-linux-runnerThis will automatically compile the model with full GPU and hardware acceleration, download the model to the Jetson, and then start classifying. Edge Impulse Linux SDK has examples on how to integrate the model with a range of programming languages.
Edge detectionAnother interesting approach to the challenge of detecting reflective surfaces is using edge detection. This would still benefit from synthetic data generation with automatic labeling. By using OpenCV's Canny function we can easily create training images only concentrating on object edges, while maintaining the labels.
# Convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Use Canny edge detector
edges = cv2.Canny(gray, threshold1=50, threshold2=200)To utilize edge detection we would have to apply similar transformation on the input when running inference.
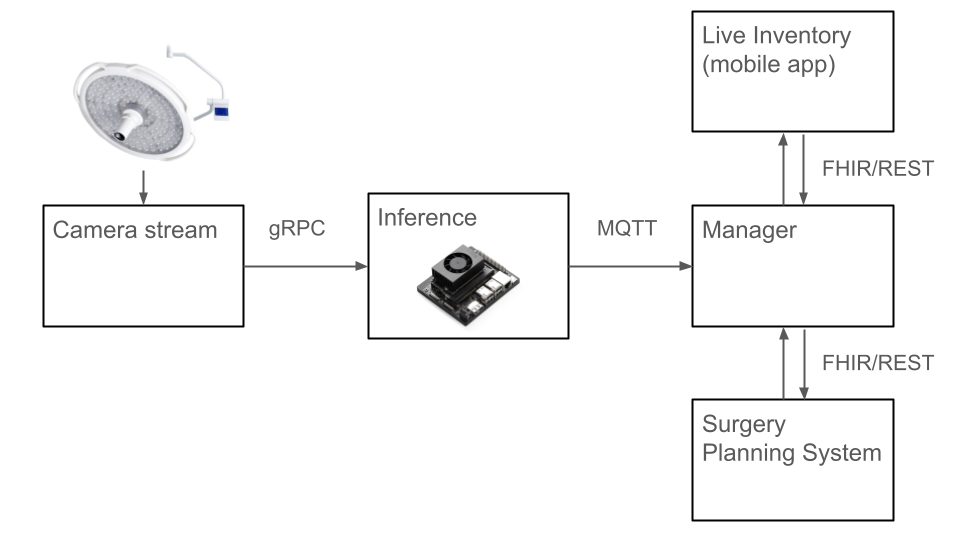
ApplicationThe outlines of the final application flow looks like this:
- The equipment planned for use in a given surgery is retrieved from the surgery planning system, as can be tested in open DIPS sandbox.
- Before surgery start planned inventory is compared and confirmed to the equipment layed out on table.
- As surgery progresses the inventory list is automatically maintained with what tools can be seen on table.
- Live inventory can be viewed on mobile app. Extra equipment and disposables can be registrered when introduced ad-hoc.
- At surgery end a final tally of the equipment prepared and returned to table is documented in surgery planning system.
Technically this would consist of several components:
- Integration with surgery planning system to retrieve planned equipment as a structured list for the currently planned surgery in the current OR. The equipment list would need to be mapped to the classes used in the Object Detection model.
- Live camera feed from surgery camera.
- Live inference on NVIDIA Jetson Orin Nano that publishes MQTT-messages with currently detected objects.
This project demostrates that it is possible to create powerful object detection models purely on synthetic images. As demonstrated, due to the difficult nature of the objects of interest this project would not be feasible to be implemented with traditional manual data capture and annotation. The project also demonstrates the power of transfer learning, where existing computer vision models trained on large generic data sets can be fine-tuned for specific applications. Finally the project demonstrates how easily an object detection model based on synthetic data can be targeted both to constrained hardware, such as a microcontroller and to a more powerful GPU-based platform.
Synthetic image generation requires 3D models to represent the real-life counterparts. Luckily 3D assets are readily available, and advances in generative text-to-3D models are rapidly becoming usable.
Eivind Holt has worked as a developer in Norwegian Electronic Health Record system vendor DIPS since 2004, lately as Tech Lead in research and innovation. On his spare time he experiments with the latest advances in sensor and AI tech, writes articles, hosts workshops and talks.




{kind=link}
Comments
Please log in or sign up to comment.