





Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
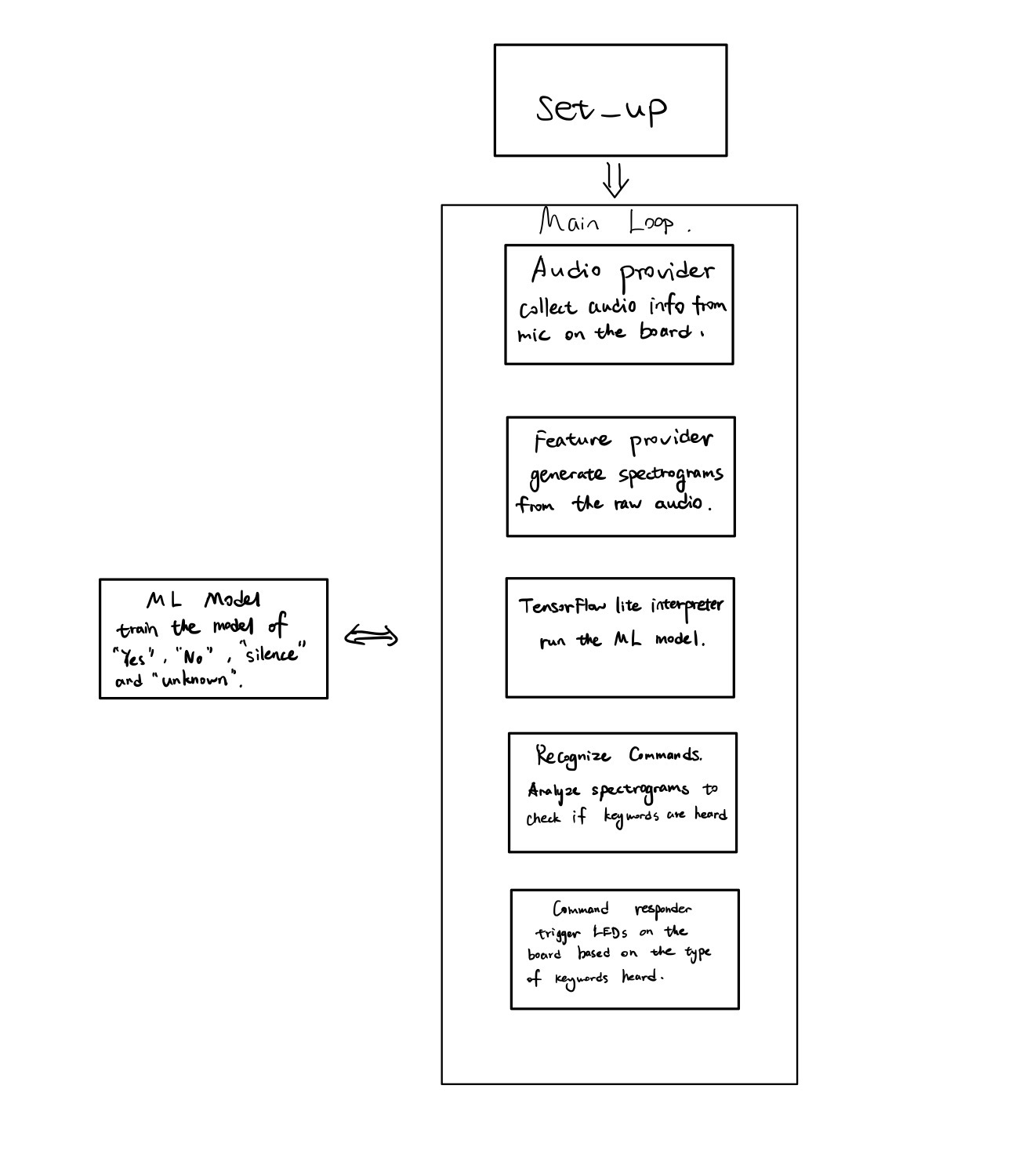
Nowadays, TinyML has become quite popular in the past few years, and it is widely used in our daily life. Some well-known products like Apple’s Siri, Amazon Alexa, and Google Assistant are all built based on this technology. These devices enable users to get instant access to information via voice control without using displays or keyboards. Behind these devices, there are some servers with the huge ML model to recognize various audio information sent from devices. However, these audio information are not collected 24/7 for the sake of privacy and efficiency. The user does not want to send their every word to the device from a privacy perspective, and the servers can not afford to analyze a constant stream of audio all time in terms of exceeded resource usage. The device needs some sort of signals to let it know when to collect the audio, and here is the wake word detection that comes to play. It is like when the iPhone hears “Hey Siri”, the iOS knows it can begin to capture audio and send it to the server. This project built on the microcontroller is to recognize two keywords “yes” and “no”, and the LED will behave accordingly to distinguish these two words using pre-trained audio model built with TensorFlow lite.
The project is instructed by Chapter 7 with pre-built ML model for keywords.
In Chapter 7, we learned that a spectrogram in the form of two-dimensional array is used as the input fed int the model as a 2D tensor. The model is trained based on the convolutional neural network(CNN) to collect and analyze the features among a group of adjacent information within multidimensional vector input so that it can recognize the specific class of input audio. The first step of this project is to capture the audio which is accomplished in Audio provider block. The audio is captured constantly by the built-in microphone on the board. The spectrogram format will be created from the raw audio data. Then, the well-formed spectrogram will be sent to the pre-trained model to output a set of probabilities for all categories. The operation should be implemented on a rolling basis to continuously check the audio. Thus, we should have some methods to determine if there is a keyword during a certain time window. Recognize commands components are run multiple times per second, and it aggregates the results and determined averagely if a keyword is heard. In the Command responder component, based on the possibility of each class, the RGB LEDs will be configured to indicate which keyword was heard. The device we used is Arduino Nano 33 BLE Sense. The built-in RGB LED indicates the recognized keywords. Initially, all three LEDs are set to off. There will be three scenarios, and they are “yes”, “no” and “unknown”. When the device found it is “yes”, the green LED will be on. When the device found it is “no”, the red LED will be on. When the device found it is “unknown”, the blue LED will be on. All three LEDs will be on for three seconds, and then it will be off. Otherwise, the built-in LED will be toggled when an inference is performed.
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/audio_provider.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/micro_model_settings.h"
namespace {
int16_t g_dummy_audio_data[kMaxAudioSampleSize];
int32_t g_latest_audio_timestamp = 0;
} // namespace
TfLiteStatus GetAudioSamples(tflite::ErrorReporter* error_reporter,
int start_ms, int duration_ms,
int* audio_samples_size, int16_t** audio_samples) {
for (int i = 0; i < kMaxAudioSampleSize; ++i) {
g_dummy_audio_data[i] = 0;
}
*audio_samples_size = kMaxAudioSampleSize;
*audio_samples = g_dummy_audio_data;
return kTfLiteOk;
}
int32_t LatestAudioTimestamp() {
g_latest_audio_timestamp += 100;
return g_latest_audio_timestamp;
}
/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_RECOGNIZE_COMMANDS_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_RECOGNIZE_COMMANDS_H_
#include <cstdint>
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/micro_model_settings.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Partial implementation of std::dequeue, just providing the functionality
// that's needed to keep a record of previous neural network results over a
// short time period, so they can be averaged together to produce a more
// accurate overall prediction. This doesn't use any dynamic memory allocation
// so it's a better fit for microcontroller applications, but this does mean
// there are hard limits on the number of results it can store.
class PreviousResultsQueue {
public:
PreviousResultsQueue(tflite::ErrorReporter* error_reporter)
: error_reporter_(error_reporter), front_index_(0), size_(0) {}
// Data structure that holds an inference result, and the time when it
// was recorded.
struct Result {
Result() : time_(0), scores_() {}
Result(int32_t time, uint8_t* scores) : time_(time) {
for (int i = 0; i < kCategoryCount; ++i) {
scores_[i] = scores[i];
}
}
int32_t time_;
uint8_t scores_[kCategoryCount];
};
int size() { return size_; }
bool empty() { return size_ == 0; }
Result& front() { return results_[front_index_]; }
Result& back() {
int back_index = front_index_ + (size_ - 1);
if (back_index >= kMaxResults) {
back_index -= kMaxResults;
}
return results_[back_index];
}
void push_back(const Result& entry) {
if (size() >= kMaxResults) {
error_reporter_->Report(
"Couldn't push_back latest result, too many already!");
return;
}
size_ += 1;
back() = entry;
}
Result pop_front() {
if (size() <= 0) {
error_reporter_->Report("Couldn't pop_front result, none present!");
return Result();
}
Result result = front();
front_index_ += 1;
if (front_index_ >= kMaxResults) {
front_index_ = 0;
}
size_ -= 1;
return result;
}
// Most of the functions are duplicates of dequeue containers, but this
// is a helper that makes it easy to iterate through the contents of the
// queue.
Result& from_front(int offset) {
if ((offset < 0) || (offset >= size_)) {
error_reporter_->Report("Attempt to read beyond the end of the queue!");
offset = size_ - 1;
}
int index = front_index_ + offset;
if (index >= kMaxResults) {
index -= kMaxResults;
}
return results_[index];
}
private:
tflite::ErrorReporter* error_reporter_;
static constexpr int kMaxResults = 50;
Result results_[kMaxResults];
int front_index_;
int size_;
};
// This class is designed to apply a very primitive decoding model on top of the
// instantaneous results from running an audio recognition model on a single
// window of samples. It applies smoothing over time so that noisy individual
// label scores are averaged, increasing the confidence that apparent matches
// are real.
// To use it, you should create a class object with the configuration you
// want, and then feed results from running a TensorFlow model into the
// processing method. The timestamp for each subsequent call should be
// increasing from the previous, since the class is designed to process a stream
// of data over time.
class RecognizeCommands {
public:
// labels should be a list of the strings associated with each one-hot score.
// The window duration controls the smoothing. Longer durations will give a
// higher confidence that the results are correct, but may miss some commands.
// The detection threshold has a similar effect, with high values increasing
// the precision at the cost of recall. The minimum count controls how many
// results need to be in the averaging window before it's seen as a reliable
// average. This prevents erroneous results when the averaging window is
// initially being populated for example. The suppression argument disables
// further recognitions for a set time after one has been triggered, which can
// help reduce spurious recognitions.
explicit RecognizeCommands(tflite::ErrorReporter* error_reporter,
int32_t average_window_duration_ms = 1000,
uint8_t detection_threshold = 200,
int32_t suppression_ms = 1500,
int32_t minimum_count = 3);
// Call this with the results of running a model on sample data.
TfLiteStatus ProcessLatestResults(const TfLiteTensor* latest_results,
const int32_t current_time_ms,
const char** found_command, uint8_t* score,
bool* is_new_command);
private:
// Configuration
tflite::ErrorReporter* error_reporter_;
int32_t average_window_duration_ms_;
uint8_t detection_threshold_;
int32_t suppression_ms_;
int32_t minimum_count_;
// Working variables
PreviousResultsQueue previous_results_;
const char* previous_top_label_;
int32_t previous_top_label_time_;
};
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_RECOGNIZE_COMMANDS_H_
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/command_responder.h"
#include "Arduino.h"
// Toggles the built-in LED every inference, and lights a colored LED depending
// on which word was detected.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command) {
static bool is_initialized = false;
if (!is_initialized) {
pinMode(LED_BUILTIN, OUTPUT);
// Pins for the built-in RGB LEDs on the Arduino Nano 33 BLE Sense
pinMode(LEDR, OUTPUT);
pinMode(LEDG, OUTPUT);
pinMode(LEDB, OUTPUT);
// Ensure the LED is off by default.
// Note: The RGB LEDs on the Arduino Nano 33 BLE
// Sense are on when the pin is LOW, off when HIGH.
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
is_initialized = true;
}
static int32_t last_command_time = 0;
static int count = 0;
static int certainty = 220;
if (is_new_command) {
error_reporter->Report("Heard %s (%d) @%dms", found_command, score,
current_time);
// If we hear a command, light up the appropriate LED
if (found_command[0] == 'y') {
last_command_time = current_time;
digitalWrite(LEDG, LOW); // Green for yes
}
if (found_command[0] == 'n') {
last_command_time = current_time;
digitalWrite(LEDR, LOW); // Red for no
}
if (found_command[0] == 'u') {
last_command_time = current_time;
digitalWrite(LEDB, LOW); // Blue for unknown
}
}
// If last_command_time is non-zero but was >3 seconds ago, zero it
// and switch off the LED.
if (last_command_time != 0) {
if (last_command_time < (current_time - 3000)) {
last_command_time = 0;
digitalWrite(LED_BUILTIN, LOW);
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
}
// If it is non-zero but <3 seconds ago, do nothing.
return;
}
// Otherwise, toggle the LED every time an inference is performed.
++count;
if (count & 1) {
digitalWrite(LED_BUILTIN, HIGH);
} else {
digitalWrite(LED_BUILTIN, LOW);
}
}
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// This is an abstraction around an audio source like a microphone, and is
// expected to return 16-bit PCM sample data for a given point in time. The
// sample data itself should be used as quickly as possible by the caller, since
// to allow memory optimizations there are no guarantees that the samples won't
// be overwritten by new data in the future. In practice, implementations should
// ensure that there's a reasonable time allowed for clients to access the data
// before any reuse.
// The reference implementation can have no platform-specific dependencies, so
// it just returns an array filled with zeros. For real applications, you should
// ensure there's a specialized implementation that accesses hardware APIs.
TfLiteStatus GetAudioSamples(tflite::ErrorReporter* error_reporter,
int start_ms, int duration_ms,
int* audio_samples_size, int16_t** audio_samples);
// Returns the time that audio data was last captured in milliseconds. There's
// no contract about what time zero represents, the accuracy, or the granularity
// of the result. Subsequent calls will generally not return a lower value, but
// even that's not guaranteed if there's an overflow wraparound.
// The reference implementation of this function just returns a constantly
// incrementing value for each call, since it would need a non-portable platform
// call to access time information. For real applications, you'll need to write
// your own platform-specific implementation.
int32_t LatestAudioTimestamp();
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_AUDIO_PROVIDER_H_
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/command_responder.h"
// The default implementation writes out the name of the recognized command
// to the error console. Real applications will want to take some custom
// action instead, and should implement their own versions of this function.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command) {
if (is_new_command) {
error_reporter->Report("Heard %s (%d) @%dms", found_command, score,
current_time);
}
}
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
// Provides an interface to take an action based on an audio command.
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Called every time the results of an audio recognition run are available. The
// human-readable name of any recognized command is in the `found_command`
// argument, `score` has the numerical confidence, and `is_new_command` is set
// if the previous command was different to this one.
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command);
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_COMMAND_RESPONDER_H_
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/feature_provider.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/audio_provider.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/micro_features_generator.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/micro_model_settings.h"
FeatureProvider::FeatureProvider(int feature_size, uint8_t* feature_data)
: feature_size_(feature_size),
feature_data_(feature_data),
is_first_run_(true) {
// Initialize the feature data to default values.
for (int n = 0; n < feature_size_; ++n) {
feature_data_[n] = 0;
}
}
FeatureProvider::~FeatureProvider() {}
TfLiteStatus FeatureProvider::PopulateFeatureData(
tflite::ErrorReporter* error_reporter, int32_t last_time_in_ms,
int32_t time_in_ms, int* how_many_new_slices) {
if (feature_size_ != kFeatureElementCount) {
error_reporter->Report("Requested feature_data_ size %d doesn't match %d",
feature_size_, kFeatureElementCount);
return kTfLiteError;
}
// Quantize the time into steps as long as each window stride, so we can
// figure out which audio data we need to fetch.
const int last_step = (last_time_in_ms / kFeatureSliceStrideMs);
const int current_step = (time_in_ms / kFeatureSliceStrideMs);
int slices_needed = current_step - last_step;
// If this is the first call, make sure we don't use any cached information.
if (is_first_run_) {
TfLiteStatus init_status = InitializeMicroFeatures(error_reporter);
if (init_status != kTfLiteOk) {
return init_status;
}
is_first_run_ = false;
slices_needed = kFeatureSliceCount;
}
if (slices_needed > kFeatureSliceCount) {
slices_needed = kFeatureSliceCount;
}
*how_many_new_slices = slices_needed;
const int slices_to_keep = kFeatureSliceCount - slices_needed;
const int slices_to_drop = kFeatureSliceCount - slices_to_keep;
// If we can avoid recalculating some slices, just move the existing data
// up in the spectrogram, to perform something like this:
// last time = 80ms current time = 120ms
// +-----------+ +-----------+
// | data@20ms | --> | data@60ms |
// +-----------+ -- +-----------+
// | data@40ms | -- --> | data@80ms |
// +-----------+ -- -- +-----------+
// | data@60ms | -- -- | <empty> |
// +-----------+ -- +-----------+
// | data@80ms | -- | <empty> |
// +-----------+ +-----------+
if (slices_to_keep > 0) {
for (int dest_slice = 0; dest_slice < slices_to_keep; ++dest_slice) {
uint8_t* dest_slice_data =
feature_data_ + (dest_slice * kFeatureSliceSize);
const int src_slice = dest_slice + slices_to_drop;
const uint8_t* src_slice_data =
feature_data_ + (src_slice * kFeatureSliceSize);
for (int i = 0; i < kFeatureSliceSize; ++i) {
dest_slice_data[i] = src_slice_data[i];
}
}
}
// Any slices that need to be filled in with feature data have their
// appropriate audio data pulled, and features calculated for that slice.
if (slices_needed > 0) {
for (int new_slice = slices_to_keep; new_slice < kFeatureSliceCount;
++new_slice) {
const int new_step = (current_step - kFeatureSliceCount + 1) + new_slice;
const int32_t slice_start_ms = (new_step * kFeatureSliceStrideMs);
int16_t* audio_samples = nullptr;
int audio_samples_size = 0;
// TODO(petewarden): Fix bug that leads to non-zero slice_start_ms
GetAudioSamples(error_reporter, (slice_start_ms > 0 ? slice_start_ms : 0),
kFeatureSliceDurationMs, &audio_samples_size,
&audio_samples);
if (audio_samples_size < kMaxAudioSampleSize) {
error_reporter->Report("Audio data size %d too small, want %d",
audio_samples_size, kMaxAudioSampleSize);
return kTfLiteError;
}
uint8_t* new_slice_data = feature_data_ + (new_slice * kFeatureSliceSize);
size_t num_samples_read;
TfLiteStatus generate_status = GenerateMicroFeatures(
error_reporter, audio_samples, audio_samples_size, kFeatureSliceSize,
new_slice_data, &num_samples_read);
if (generate_status != kTfLiteOk) {
return generate_status;
}
}
}
return kTfLiteOk;
}
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
#include "tensorflow/lite/c/c_api_internal.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
// Binds itself to an area of memory intended to hold the input features for an
// audio-recognition neural network model, and fills that data area with the
// features representing the current audio input, for example from a microphone.
// The audio features themselves are a two-dimensional array, made up of
// horizontal slices representing the frequencies at one point in time, stacked
// on top of each other to form a spectrogram showing how those frequencies
// changed over time.
class FeatureProvider {
public:
// Create the provider, and bind it to an area of memory. This memory should
// remain accessible for the lifetime of the provider object, since subsequent
// calls will fill it with feature data. The provider does no memory
// management of this data.
FeatureProvider(int feature_size, uint8_t* feature_data);
~FeatureProvider();
// Fills the feature data with information from audio inputs, and returns how
// many feature slices were updated.
TfLiteStatus PopulateFeatureData(tflite::ErrorReporter* error_reporter,
int32_t last_time_in_ms, int32_t time_in_ms,
int* how_many_new_slices);
private:
int feature_size_;
uint8_t* feature_data_;
// Make sure we don't try to use cached information if this is the first call
// into the provider.
bool is_first_run_;
};
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_FEATURE_PROVIDER_H_
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/main_functions.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/audio_provider.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/command_responder.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/feature_provider.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/micro_model_settings.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/micro_features/tiny_conv_micro_features_model_data.h"
#include "tensorflow/lite/experimental/micro/examples/micro_speech/recognize_commands.h"
#include "tensorflow/lite/experimental/micro/kernels/micro_ops.h"
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
#include "tensorflow/lite/experimental/micro/micro_interpreter.h"
#include "tensorflow/lite/experimental/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"
// Globals, used for compatibility with Arduino-style sketches.
namespace {
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* model_input = nullptr;
FeatureProvider* feature_provider = nullptr;
RecognizeCommands* recognizer = nullptr;
int32_t previous_time = 0;
// Create an area of memory to use for input, output, and intermediate arrays.
// The size of this will depend on the model you're using, and may need to be
// determined by experimentation.
constexpr int kTensorArenaSize = 10 * 1024;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
// The name of this function is important for Arduino compatibility.
void setup() {
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroErrorReporter micro_error_reporter;
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(g_tiny_conv_micro_features_model_data);
if (model->version() != TFLITE_SCHEMA_VERSION) {
error_reporter->Report(
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// Pull in only the operation implementations we need.
// This relies on a complete list of all the ops needed by this graph.
// An easier approach is to just use the AllOpsResolver, but this will
// incur some penalty in code space for op implementations that are not
// needed by this graph.
//
// tflite::ops::micro::AllOpsResolver resolver;
// NOLINTNEXTLINE(runtime-global-variables)
static tflite::MicroMutableOpResolver micro_mutable_op_resolver;
micro_mutable_op_resolver.AddBuiltin(
tflite::BuiltinOperator_DEPTHWISE_CONV_2D,
tflite::ops::micro::Register_DEPTHWISE_CONV_2D());
micro_mutable_op_resolver.AddBuiltin(
tflite::BuiltinOperator_FULLY_CONNECTED,
tflite::ops::micro::Register_FULLY_CONNECTED());
micro_mutable_op_resolver.AddBuiltin(tflite::BuiltinOperator_SOFTMAX,
tflite::ops::micro::Register_SOFTMAX());
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(
model, micro_mutable_op_resolver, tensor_arena, kTensorArenaSize,
error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
TfLiteStatus allocate_status = interpreter->AllocateTensors();
if (allocate_status != kTfLiteOk) {
error_reporter->Report("AllocateTensors() failed");
return;
}
// Get information about the memory area to use for the model's input.
model_input = interpreter->input(0);
if ((model_input->dims->size != 4) || (model_input->dims->data[0] != 1) ||
(model_input->dims->data[1] != kFeatureSliceCount) ||
(model_input->dims->data[2] != kFeatureSliceSize) ||
(model_input->type != kTfLiteUInt8)) {
error_reporter->Report("Bad input tensor parameters in model");
return;
}
// Prepare to access the audio spectrograms from a microphone or other source
// that will provide the inputs to the neural network.
// NOLINTNEXTLINE(runtime-global-variables)
static FeatureProvider static_feature_provider(kFeatureElementCount,
model_input->data.uint8);
feature_provider = &static_feature_provider;
static RecognizeCommands static_recognizer(error_reporter);
recognizer = &static_recognizer;
previous_time = 0;
}
// The name of this function is important for Arduino compatibility.
void loop() {
// Fetch the spectrogram for the current time.
const int32_t current_time = LatestAudioTimestamp();
int how_many_new_slices = 0;
TfLiteStatus feature_status = feature_provider->PopulateFeatureData(
error_reporter, previous_time, current_time, &how_many_new_slices);
if (feature_status != kTfLiteOk) {
error_reporter->Report("Feature generation failed");
return;
}
previous_time = current_time;
// If no new audio samples have been received since last time, don't bother
// running the network model.
if (how_many_new_slices == 0) {
return;
}
// Run the model on the spectrogram input and make sure it succeeds.
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
error_reporter->Report("Invoke failed");
return;
}
// Obtain a pointer to the output tensor
TfLiteTensor* output = interpreter->output(0);
// Determine whether a command was recognized based on the output of inference
const char* found_command = nullptr;
uint8_t score = 0;
bool is_new_command = false;
TfLiteStatus process_status = recognizer->ProcessLatestResults(
output, current_time, &found_command, &score, &is_new_command);
if (process_status != kTfLiteOk) {
error_reporter->Report("RecognizeCommands::ProcessLatestResults() failed");
return;
}
// Do something based on the recognized command. The default implementation
// just prints to the error console, but you should replace this with your
// own function for a real application.
RespondToCommand(error_reporter, current_time, found_command, score,
is_new_command);
}
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
#define TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
// Initializes all data needed for the example. The name is important, and needs
// to be setup() for Arduino compatibility.
void setup();
// Runs one iteration of data gathering and inference. This should be called
// repeatedly from the application code. The name needs to be loop() for Arduino
// compatibility.
void loop();
#endif // TENSORFLOW_LITE_EXPERIMENTAL_MICRO_EXAMPLES_MICRO_SPEECH_MAIN_FUNCTIONS_H_
/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/experimental/micro/examples/micro_speech/recognize_commands.h"
#include <limits>
RecognizeCommands::RecognizeCommands(tflite::ErrorReporter* error_reporter,
int32_t average_window_duration_ms,
uint8_t detection_threshold,
int32_t suppression_ms,
int32_t minimum_count)
: error_reporter_(error_reporter),
average_window_duration_ms_(average_window_duration_ms),
detection_threshold_(detection_threshold),
suppression_ms_(suppression_ms),
minimum_count_(minimum_count),
previous_results_(error_reporter) {
previous_top_label_ = "silence";
previous_top_label_time_ = std::numeric_limits<int32_t>::min();
}
TfLiteStatus RecognizeCommands::ProcessLatestResults(
const TfLiteTensor* latest_results, const int32_t current_time_ms,
const char** found_command, uint8_t* score, bool* is_new_command) {
if ((latest_results->dims->size != 2) ||
(latest_results->dims->data[0] != 1) ||
(latest_results->dims->data[1] != kCategoryCount)) {
error_reporter_->Report(
"The results for recognition should contain %d elements, but there are "
"%d in an %d-dimensional shape",
kCategoryCount, latest_results->dims->data[1],
latest_results->dims->size);
return kTfLiteError;
}
if (latest_results->type != kTfLiteUInt8) {
error_reporter_->Report(
"The results for recognition should be uint8 elements, but are %d",
latest_results->type);
return kTfLiteError;
}
if ((!previous_results_.empty()) &&
(current_time_ms < previous_results_.front().time_)) {
error_reporter_->Report(
"Results must be fed in increasing time order, but received a "
"timestamp of %d that was earlier than the previous one of %d",
current_time_ms, previous_results_.front().time_);
return kTfLiteError;
}
// Add the latest results to the head of the queue.
previous_results_.push_back({current_time_ms, latest_results->data.uint8});
// Prune any earlier results that are too old for the averaging window.
const int64_t time_limit = current_time_ms - average_window_duration_ms_;
while ((!previous_results_.empty()) &&
previous_results_.front().time_ < time_limit) {
previous_results_.pop_front();
}
// If there are too few results, assume the result will be unreliable and
// bail.
const int64_t how_many_results = previous_results_.size();
const int64_t earliest_time = previous_results_.front().time_;
const int64_t samples_duration = current_time_ms - earliest_time;
if ((how_many_results < minimum_count_) ||
(samples_duration < (average_window_duration_ms_ / 4))) {
*found_command = previous_top_label_;
*score = 0;
*is_new_command = false;
return kTfLiteOk;
}
// Calculate the average score across all the results in the window.
int32_t average_scores[kCategoryCount];
for (int offset = 0; offset < previous_results_.size(); ++offset) {
PreviousResultsQueue::Result previous_result =
previous_results_.from_front(offset);
const uint8_t* scores = previous_result.scores_;
for (int i = 0; i < kCategoryCount; ++i) {
if (offset == 0) {
average_scores[i] = scores[i];
} else {
average_scores[i] += scores[i];
}
}
}
for (int i = 0; i < kCategoryCount; ++i) {
average_scores[i] /= how_many_results;
}
// Find the current highest scoring category.
int current_top_index = 0;
int32_t current_top_score = 0;
for (int i = 0; i < kCategoryCount; ++i) {
if (average_scores[i] > current_top_score) {
current_top_score = average_scores[i];
current_top_index = i;
}
}
const char* current_top_label = kCategoryLabels[current_top_index];
// If we've recently had another label trigger, assume one that occurs too
// soon afterwards is a bad result.
int64_t time_since_last_top;
if ((previous_top_label_ == kCategoryLabels[0]) ||
(previous_top_label_time_ == std::numeric_limits<int32_t>::min())) {
time_since_last_top = std::numeric_limits<int32_t>::max();
} else {
time_since_last_top = current_time_ms - previous_top_label_time_;
}
if ((current_top_score > detection_threshold_) &&
((current_top_label != previous_top_label_) ||
(time_since_last_top > suppression_ms_))) {
previous_top_label_ = current_top_label;
previous_top_label_time_ = current_time_ms;
*is_new_command = true;
} else {
*is_new_command = false;
}
*found_command = current_top_label;
*score = current_top_score;
return kTfLiteOk;
}



{kind=link}
Comments
Please log in or sign up to comment.