



Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Almost all the private and government sectors and schools opted "Work from home" for their employees due to this covid-19 pandemics.
Schools were enabled online class approaches and companies nowadays mostly depends on video calling feature for meetings/discussions.
Here privacy is question mark
So to protect privacy of employee and students, implemented optimized background removal or blurring feature with OpenVINO.
This is heterogeneous application, can run in following targets,
CPU, GPU and FPGA (One solution for multiple different architectures)
Overview:
Mainly for 2 reasons,
- Optimizing and Quantizing Neural Network for Inference to achieve realtime
Segmentation models are so much compute intensive. Without optimization and quatization, achieving realtime is not possible at all.
- Heterogeneity across multiple architecture and platforms (one solution to many platforms
Develop one solution and deploy it with multiple target.
Applicable to both data-center and edge. No need to change even single line of code.
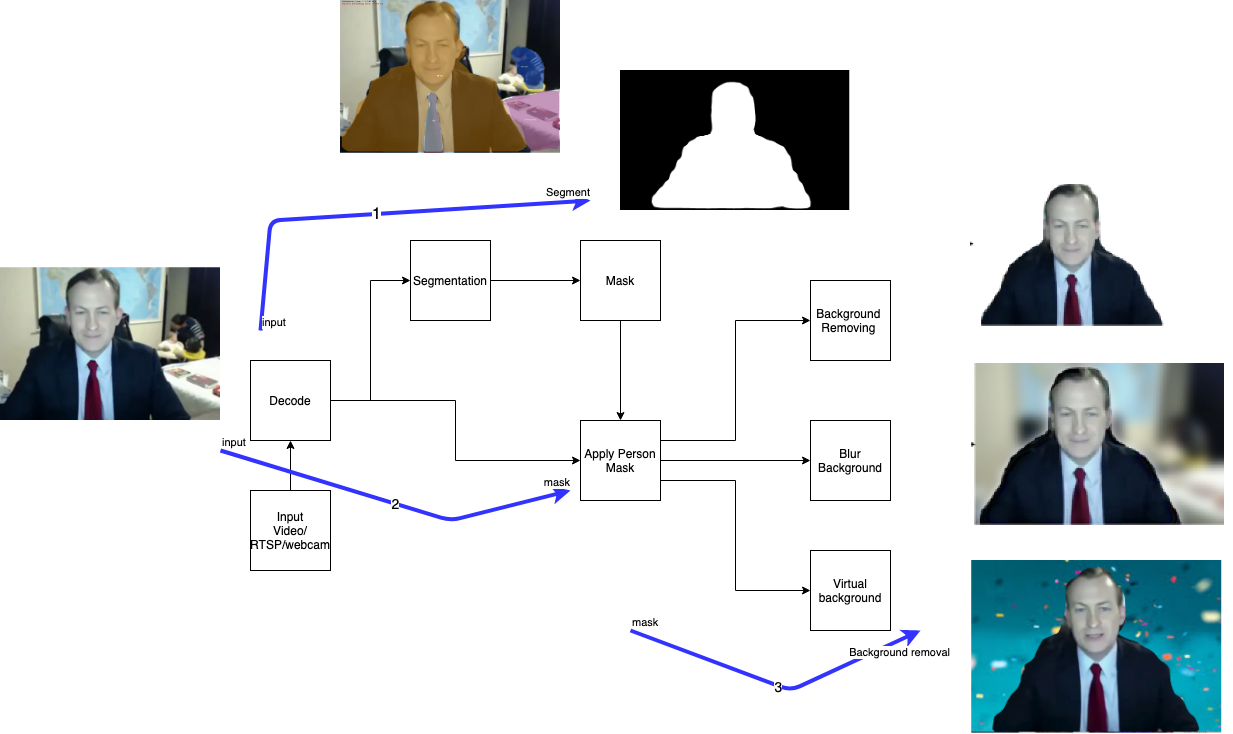
From Picture-1,
Project overview:- Apply Segmentation on input feed and separate Mask from segmentation response
- Apply separated Mask on input feed
- Apply different combinations of image Processing techniques to get desired response.
Pipeline 1: Deep Learning
Using any one of the following pre-trained model provided by intel, Based on Mask RCNN
- instance-segmentation-security-0050
- instance-segmentation-security-0083
- instance-segmentation-security-0010
- instance-segmentation-security-1025 - (fast one compared to other models)
Why Instance segmentation?
Labels of Instance segmentation are instance-aware. Instance Segmentation is identifying each object instance for every known object within an image.
With instance segmentation, we are getting more understanding on the instance individuals.
model output response,
Separate 'required person mask' from model response,
Pipeline 2 & 3: Image Processing
Background blur:Step 1: Separate background
Step 2: Blur background
Step 3: Merge person and background
python3 customize_video_background_with_person_segment.py -h
usage: customize_video_background_with_person_segment.py [-h] -f FUNCTION -m
"<path>" --labels
"<path>" -i "<path>"
[-d "<device>"]
[-l "<absolute_path>"]
[--delay "<num>"]
[--custom_image "<path>"]
[-pt "<num>"]
[--no_keep_aspect_ratio]
[--no_track]
[--show_scores]
[--show_boxes] [-pc]
[-r] [--no_show]
Options:
-h, --help Show this help message and exit.
-f FUNCTION, --function FUNCTION
Required. enter
1 for removing background
2 for changing background
3 for background blurring.
-m "<path>", --model "<path>"
Required. Path to an .xml file with a trained model.
--custom_image "<path>"
Required. Path to a custom background image file.
--labels "<path>" Required. Path to a text file with class labels.
-i "<path>" Required. Path to an image, video file or a numeric
camera ID.
-d "<device>", --device "<device>"
Optional. Specify the target device to infer on: CPU,
GPU, FPGA, HDDL or MYRIAD. The demo will look for a
suitable plugin for device specified (by default, it
is CPU).
-l "<absolute_path>", --cpu_extension "<absolute_path>"
Required for CPU custom layers. Absolute path to a
shared library with the kernels implementation.
--delay "<num>" Optional. Interval in milliseconds of waiting for a
key to be pressed.
-pt "<num>", --prob_threshold "<num>"
Optional. Probability threshold for detections
filtering.
--no_keep_aspect_ratio
Optional. Force image resize not to keep aspect ratio.
--no_track Optional. Disable tracking.
--show_scores Optional. Show detection scores.
--show_boxes Optional. Show bounding boxes.
-pc, --perf_counts Optional. Report performance counters.
-r, --raw_output_message
Optional. Output inference results raw values.
--no_show Optional. Don't show outputTo execute Background Blur:
python3 customize_video_background_with_person_segment.py \
-m <path to model>/instance-segmentation-security-0083.xml\
--label coco_labels.txt \
--delay 1 \
-i input/input_video.mov \
--function 3Response:
To execute Background Removal:
python3 customize_video_background_with_person_segment.py \
-m <path to model>/instance-segmentation-security-0083.xml \
--label coco_labels.txt \
--delay 1 \
-i input/input_video.mov \
--function 1Response:
To execute Virtual Background:
python3 customize_video_background_with_person_segment.py \
-m <path to model>/instance-segmentation-security-0083.xml \
--label coco_labels.txt \
--delay 1 \
-i input/input_video.mov \
--custom_image input/background_image.jpeg
--function 2Here is few benchmarking data, Maximum fps achieved with respect to following pre-trained models.
- instance-segmentation-security-0050 - 20 fps
- instance-segmentation-security-1025 - 25 fps
- Benchmark (1025 model) for 48 concurrent streams and 48 inference async request, fps - 24
[ INFO ] Prepare image /home/test/input.png
[ WARNING ] Image is resized from (1566, 1086) to (480, 480)
[ INFO ] Fill input 'im_info' with image size 480x480
[Step 10/11] Measuring performance (Start inference asyncronously, 48 inference requests using 48 streams for CPU, limits: 60000 ms duration)
[Step 11/11] Dumping statistics report
Count: 1488 iterations
Duration: 61865.65 ms
Latency: 1976.05 ms
Throughput: 24.05 FPS- Benchmark (1025 model) for 12 concurrent streams and 12 inference async request, fps - 20
[ INFO ] Prepare image /home/test/input.png
[ WARNING ] Image is resized from (1566, 1086) to (480, 480)
[ INFO ] Fill input 'im_info' with image size 480x480
[Step 10/11] Measuring performance (Start inference asyncronously, 12 inference requests using 12 streams for CPU, limits: 60000 ms duration)
[Step 11/11] Dumping statistics report
Count: 1224 iterations
Duration: 60719.57 ms
Latency: 586.51 ms
Throughput: 20.16 FPS- Benchmark (1025 model) for 2 concurrent streams and 2 inference async request, fps - 15
[Step 10/11] Measuring performance (Start inference asyncronously, 2 inference requests using 2 streams for CPU, limits: 1000 ms duration)
[Step 11/11] Dumping statistics report
Count: 18 iterations
Duration: 1198.51 ms
Latency: 130.32 ms
Throughput: 15.02 FPS- Benchmark (1025 model) for 1 streams and 1 inference request, fps - 10
[ INFO ] Fill input 'im_info' with image size 480x480
[Step 10/11] Measuring performance (Start inference asyncronously, 1 inference requests using 1 streams for CPU, limits: 1000 ms duration)
[Step 11/11] Dumping statistics report
Count: 12 iterations
Duration: 1189.33 ms
Latency: 96.91 ms
Throughput: 10.09 FPSScaling can be depends on choice of server core numbers.
If server is having X cores, then X inference requests can run simultaneously in Async mode.
Scaling metric depends on number of cores.
Heterogeneous:One application code for different target platforms.
Not required to change any Inference part of the code.
How to take advantage of hardware with Openvino?
2 plugins were there,
- Hetero - frees cpu, offloads compute intensive work to other targeted platforms
- Multi - Utilizes all the targeted platform maximum
when target with Hetero or Multi plugin, it follows priority order.
-d HETERO:FPGA, CPU
1st inference Engine takes dlaplugin and execution happens with FPGA.
If any layer has no support with fpga arch then those layer falls back to cpu to execute.
-d HETERO:FPGA, CPU
-d HETERO:GPU, CPU
-d HETERO:FPGA, GPU, CPU
-d MULTI:FPGA, CPU
-d MULTI:GPU, CPUhere GPU is "Integrated GPU". you can find this feature all the intel architectures after 4th gen.
Running Inference on FPGA accelerator:Step1: Setting up Intel FPGA stack, and initialize hardware runtime stack
Step2: Program FPGA (Arria10 PAC accelerator card) with openvino provided bitstream.
Select bitstream based on neural network and supported layer specified.
Validate FPGA:
aocl diagnosefrom this command execution, you can confirm name of the device - acl0
Program FPGA:
aocl program acl0 selected_bitstream.aocxStep3: After, you can run below command to get execute on FPGA.
which utilize dlaplugin for FPGA.
python3 customize_video_background_with_person_segment.py \
-m <path to model>/instance-segmentation-security-0083.xml \
--label coco_labels.txt \
--delay 1 \
-i input/input_video.mov \
--custom_image input/background_image.jpeg
--function 2
-d HETERO: FPGA, CPUStep1: Install OpenVINO on Pi
Step2: Plug NCS2 and verify device detection
Step3: Initialize OpenVINO
Step4: Clone given github and execute this command
movidius plugin enables this NCS 2 execution
python3 customize_video_background_with_person_segment.py \
-m <path to model>/instance-segmentation-security-0083.xml \
--label coco_labels.txt \
--delay 1 \
-i input/input_video.mov \
--custom_image input/background_image.jpeg
--function 2
-d MYRIADMost of the layers are not supported with myriad (NCS2)
Reference - Instance segmentation models is not supported with MYRIAD. Refered this from openvino doc - https://docs.openvinotoolkit.org/2020.4/omz_demos_README.html
Worked fine with CPU, GPU and with FPGA.
Heterogeneous system: Single inference system for different architecture.
ConclusionHeterogeneous Privacy enabled video conferencing feature implemented with OpenVINO. This can be deployed at Intel CPU, GPU and FPGAs.
Based on core count of the server, Inference request count can be increased which runs asynchronously which improves throughput of whole inference system.
This pandemic time, this background removing feature will help to protect privacy of employees and students when attending online meetings and classes.
Thank you!!!





{kind=link}
{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.