



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
Our project is the deployment of a prevailing super-resolution algorithm, WDSR (Wide Activation for Efficient and Accurate Image Super-Resolution[1]) on VCK5000. We decide to make it out of multiple reasons. First, image super-resolution, recently frequently used and researched in both industry and academia, is mainly composed of multiple convolution and activation layers, which is right what Vitis AI is good at. Also, we have some previous knowledge about super-resolution algorithms, which allows us to understand the algorithm from the mathematical level. Moreover, the current official demo library includes barely super-resolution applications, so our attempt will show more about the strength and robustness of Vitis AI and VCK5000.
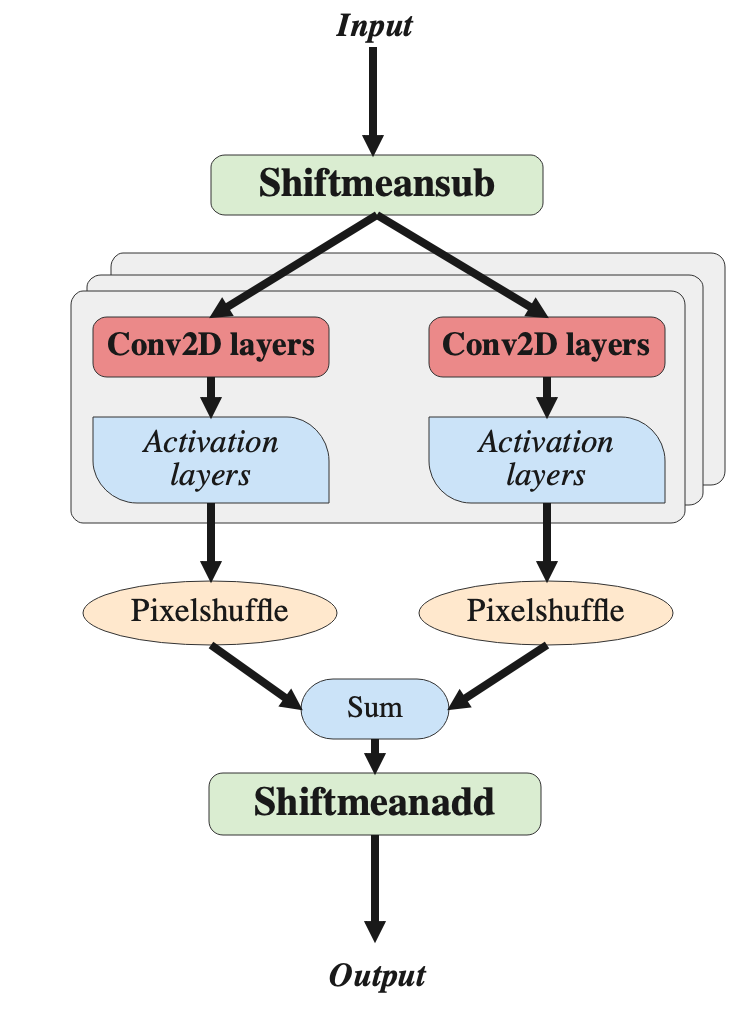
MethodAs is introduced in theuser guide, deploying a model requires model quantization, compilation, and VART programming. The model structure is shown in pic1. There are multiple operators not supported by Vitis AI, including shiftmeanadd and shiftmeansub involved in pre/post-processing and pixelshuflle and sum inside the model. We, therefore, divide the whole model into two main sub-models (the red part in pic1) which will be run on DPU in VCK5000 and the rest part will be run in CPU. We download thepre-trained model in https://github.com/ychfan/wdsr. It is worth noting that because the original model involves weight normalization for each convolutional layer, we have to process the weight in the pre-trained model and the processed pth file is involved in our source code. After dividing the model and preparing the model parameters, we quantize and compile the model. For VART programming, because we divide the model into two sub-models, we have to run two DPU models respectively and implement the unsupported operators by ourselves in C++.
We test our deployment using an input of a colorful image with size of 128x128. Because DPU only supports INT8, the accuracy of our algorithm lost a little but the speed is impressively high.
- The output is shown below:
Reference:
[1] Yu, Jiahui, et al. "Wide activation for efficient and accurate image super-resolution." arXiv preprint arXiv:1808.08718 (2018).
{kind=link}
#include <iostream>
#include "our_common.h"
// Some utility functions are defined in our_common.h:
// void ListImages(string const& path, vector<string>& images)
// void LoadWords(string const& path, vector<string>& kinds)
void CPUPixel_Shuffle(const float* inputs,
size_t imageSize, size_t in_height, size_t in_width,
int imageNum, int scale_factor, float* results)
{
int in_channel = imageSize / in_height / in_width;
int out_channel = in_channel / scale_factor / scale_factor;
int out_height = in_height * scale_factor;
int out_width = in_width * scale_factor;
for(int idx = 0; idx < imageNum; idx++)
for(int h=0; h < in_height; h++)
for(int w=0; w < in_width; w++)
for(int c=0; c < in_channel; c++){
int o_c = (int)(c / (scale_factor * scale_factor));
int o_h = (int)(h*scale_factor + (c / scale_factor)%scale_factor);
int o_w = (int)(w*scale_factor + c % scale_factor);
// results[idx*imageSize + o_c*out_height*out_width + o_h*out_width + o_w]
// = inputs[idx*imageSize + c*in_height*in_width + h*in_width + w];
results[idx*imageSize + o_h * out_channel * out_width + o_w * out_channel + o_c]
= inputs[idx*imageSize + h * in_width * in_channel + w * in_channel + c];
}
}
void CPUShiftMeanSub(const float* inputs,
size_t imageSize, size_t in_height, size_t in_width,
int imageNum, float* results)
{
int in_channel = imageSize / in_height / in_width;;
int out_channel = in_channel;
int out_height = in_height;
int out_width = in_width;
float rgb_mean[3] = {114.4440, 111.4605, 103.0200};
for(int idx = 0; idx < imageNum; idx++)
for(int h=0; h < in_height; h++)
for(int w=0; w < in_width; w++)
for(int c=0; c < in_channel; c++){
results[idx * imageSize + out_channel * h * out_width + w * out_channel + c]
= (inputs[idx * imageSize + out_channel * h * out_width + w * out_channel + c] - rgb_mean[c]) / 127.5;
}
}
void CPUShiftMeanAdd(const float* inputs,
size_t imageSize, size_t in_height, size_t in_width,
int imageNum, float* results)
{
int in_channel = imageSize / in_height / in_width;;
int out_channel = in_channel;
int out_height = in_height;
int out_width = in_width;
float rgb_mean[3] = {114.4440, 111.4605, 103.0200};
for(int idx = 0; idx < imageNum; idx++)
for(int h=0; h < in_height; h++)
for(int w=0; w < in_width; w++)
for(int c=0; c < in_channel; c++){
results[idx * imageSize + out_channel * h * out_width + w * out_channel + c]
= 127.5 * inputs[idx * imageSize + out_channel * h * out_width + w * out_channel + c] + rgb_mean[c];
}
}
void CPUSum(const float* inputs_1, const float* inputs_2,
size_t imageSize, size_t in_height, size_t in_width,
float* results
){
int in_channel = imageSize / in_height / in_width;;
int out_channel = in_channel;
int out_height = in_height;
int out_width = in_width;
for (int h = 0; h < out_height; h++)
for (int w = 0; w < out_width; w++)
for (int c = 0; c < out_channel; c++){
results[out_channel * out_width * h + w * out_channel + c]
= inputs_1[in_channel * in_width * h + w * in_channel + c] + inputs_2[in_channel * in_width * h + w * in_channel + c];
}
}
void runWDSR(
vart::Runner *mainbranch_runner,
vart::Runner *skipconv_runner,
GraphInfo mainbranch_shape,
GraphInfo skipconv_shape,
struct Arguments our_arguments) {
/* Model structure:
* preprocess: CPUShiftMeanSub
* left: skipconv + CPUPixel_Shuffle
* right: mainbranch + CPUPixel_Shuffle
* final: (right + left) -> CPUShiftMeanAdd
*/
// Currently, we use random images to test the inference latency.
// assert(our_arguments.random_image == true);
// std::vector<std::string> imageNames;
// if (our_arguments.random_image == false) {
// ListImages(our_arguments.input_path, imageNames);
// if (imageNames.size() == 0) {
// LOG(ERROR) << "\nError: No images existing under " << our_arguments.input_path;
// return ;
// }
// }
// else {
// imageNames.push_back("random");
// }
const int image_channel = 3;
const int image_height = our_arguments.height;
const int image_width = our_arguments.width;
LOG(INFO) << "Image Height: " << image_height;
LOG(INFO) << "Image Width : " << image_width;
// get in/out tensors and dimensions.
std::vector<const xir::Tensor*> mainbranch_inputTensors = mainbranch_runner->get_input_tensors();
std::vector<const xir::Tensor*> mainbranch_outputTensors = mainbranch_runner->get_output_tensors();
std::vector<const xir::Tensor*> skipconv_inputTensors = skipconv_runner->get_input_tensors();
std::vector<const xir::Tensor*> skipconv_outputTensors = skipconv_runner->get_output_tensors();
auto mainbranch_in_dims = mainbranch_inputTensors[0]->get_shape();
auto mainbranch_out_dims = mainbranch_outputTensors[0]->get_shape();
auto skipconv_in_dims = skipconv_inputTensors[0]->get_shape();
auto skipconv_out_dims = skipconv_outputTensors[0]->get_shape();
// get shape information
int mainbranch_inSize = mainbranch_shape.inTensorList[0].size;
int mainbranch_outSize = mainbranch_shape.outTensorList[0].size;
int mainbranch_height = mainbranch_shape.inTensorList[0].height;
int mainbranch_width = mainbranch_shape.inTensorList[0].width;
int skipconv_inSize = skipconv_shape.inTensorList[0].size;
int skipconv_outSize = skipconv_shape.outTensorList[0].size;
int skipconv_height = skipconv_shape.inTensorList[0].height;
int skipconv_width = skipconv_shape.inTensorList[0].width;
int inSize = mainbranch_inSize;
#ifdef DEBUG
LOG(INFO) << "mainbranch_inSize : " << mainbranch_inSize;
LOG(INFO) << "mainbranch_outSize: " << mainbranch_outSize;
LOG(INFO) << "mainbranch_height : " << mainbranch_height;
LOG(INFO) << "mainbranch_width : " << mainbranch_width;
LOG(INFO) << "skipconv_inSize : " << skipconv_inSize;
LOG(INFO) << "skipconv_outSize: " << skipconv_outSize;
LOG(INFO) << "skipconv_height : " << skipconv_height;
LOG(INFO) << "skipconv_width : " << skipconv_width;
#endif
int batchSize = mainbranch_in_dims[0];
std::vector<cv::Mat> imageList;
std::vector<cv::Mat> bimageList;
// allocate inputs/outputs buffers and pointers
std::vector<std::unique_ptr<vart::TensorBuffer>> mainbranch_inputs, skipconv_inputs;
std::vector<std::unique_ptr<vart::TensorBuffer>> mainbranch_outputs, skipconv_outputs;
std::vector<vart::TensorBuffer*> mainbranch_inputsPtr, skipconv_inputsPtr;
std::vector<vart::TensorBuffer*> mainbranch_outputsPtr, skipconv_outputsPtr;
std::vector<std::shared_ptr<xir::Tensor>> mainbranch_batchTensors;
std::vector<std::shared_ptr<xir::Tensor>> skipconv_batchTensors;
float* imageInitial = new float[mainbranch_inSize * batchSize];
float* imageInputs = new float[mainbranch_inSize * batchSize]; //after shiftmeansub
float* mainbranch_Results = new float[mainbranch_outSize * batchSize]; //right branch = mb + ps
float* skipconv_Results = new float[skipconv_outSize * batchSize]; //left branch = sc + ps
float* left_Results = new float[mainbranch_outSize * batchSize];
float* right_Results = new float[mainbranch_outSize * batchSize];
float* sum_Results = new float[mainbranch_outSize * batchSize];
float* final_Results = new float[mainbranch_outSize * batchSize]; //after shiftmeanadd
cv::Mat image2 = cv::Mat(image_height, image_width, CV_8UC3);
unsigned int runSize = 1; //(imageNames.size() < (idx + batchSize) ? (imageNames.size() - idx) : batchSize);
imageList.clear();
bimageList.clear();
for (int i = 0; i < runSize; i++){
cv::RNG rnger(cv::getTickCount());
// CV_32FC1 uniform distribution
// 32-bit floating point, channel 1
if(our_arguments.random_image == false){
cv::Mat image0 = cv::imread(our_arguments.input_path);
printf("%d\n",image0.channels());
cv::resize(image0, image2, cv::Size(image_height, image_width), 0, 0);
}
else{
rnger.fill(image2, cv::RNG::UNIFORM, cv::Scalar::all(0), cv::Scalar::all(255));
}
for (int h = 0; h < image_height; h++) {
for (int w = 0; w < image_width; w++) {
for (int c = 0; c < image_channel; c++) {
imageInitial[h * image_width * image_channel + w * image_channel + c] = image2.at<cv::Vec3b>(h, w)[c];
}
}
}
imageList.push_back(image2);
}
// cv::Mat outimg;
// outimg.create(image_height, image_width, CV_8UC3);
// for (int h = 0; h < image_height; h++) {
// for (int w = 0; w < image_width; w++) {
// for (int c = 0; c < image_channel; c++) {
// outimg.at<cv::Vec3b>(h, w)[c] = imageInitial[h * image_width * image_channel + w * image_channel + c] * 255;
// }
// }
// }
// cv::imwrite("./out.jpg", outimg);
// return;
// ======================================================== //
/************************ ShiftMeanSub *********************/
// ======================================================== //
auto start_time0 = std::chrono::high_resolution_clock::now();
CPUShiftMeanSub(imageInitial, inSize, image_height, image_width, 1, imageInputs);
auto end_time0 = std::chrono::high_resolution_clock::now();
auto process_time0 = std::chrono::duration<double,std::milli>(end_time0 - start_time0).count();
LOG(INFO) << "*******************run_ShiftMeanSub time is******************* " << process_time0;
LOG(INFO) << "********** CPU_ShiftMeanSub Done. **********";
// ======================================================== //
/****************** mainbranch *****************/
// ======================================================== //
/* in/out tensor refactory for batch input/output */
mainbranch_batchTensors.push_back(std::shared_ptr<xir::Tensor>(xir::Tensor::create(
mainbranch_inputTensors[0]->get_name(), mainbranch_in_dims,
xir::DataType{xir::DataType::FLOAT, sizeof(float) * 8u})));
mainbranch_inputs.push_back(std::make_unique<CpuFlatTensorBuffer>(
imageInputs, mainbranch_batchTensors.back().get()));
mainbranch_batchTensors.push_back(std::shared_ptr<xir::Tensor>(xir::Tensor::create(
mainbranch_outputTensors[0]->get_name(), mainbranch_out_dims,
xir::DataType{xir::DataType::FLOAT, sizeof(float) * 8u})));
mainbranch_outputs.push_back(std::make_unique<CpuFlatTensorBuffer>(
mainbranch_Results, mainbranch_batchTensors.back().get()));
mainbranch_inputsPtr.clear();
mainbranch_outputsPtr.clear();
mainbranch_inputsPtr.push_back(mainbranch_inputs[0].get());
mainbranch_outputsPtr.push_back(mainbranch_outputs[0].get());
// execution
auto start_time1 = std::chrono::high_resolution_clock::now();
auto job_id1 = mainbranch_runner->execute_async(mainbranch_inputsPtr, mainbranch_outputsPtr);
mainbranch_runner->wait(job_id1.first, -1);
auto end_time1 = std::chrono::high_resolution_clock::now();
auto process_time1 = std::chrono::duration<double,std::milli>(end_time1 - start_time1).count();
LOG(INFO) << "*******************run_mainbranch time is******************* " << process_time1;
LOG(INFO) << "********** < mainbranch > branch Done. **********";
// ======================================================== //
/****************** skipconv *****************/
// ======================================================== //
/* in/out tensor refactory for batch input/output */
skipconv_batchTensors.push_back(std::shared_ptr<xir::Tensor>(xir::Tensor::create(
skipconv_inputTensors[0]->get_name(), skipconv_in_dims,
xir::DataType{xir::DataType::FLOAT, sizeof(float) * 8u})));
skipconv_inputs.push_back(std::make_unique<CpuFlatTensorBuffer>(
imageInputs, skipconv_batchTensors.back().get()));
skipconv_batchTensors.push_back(std::shared_ptr<xir::Tensor>(xir::Tensor::create(
skipconv_outputTensors[0]->get_name(), skipconv_out_dims,
xir::DataType{xir::DataType::FLOAT, sizeof(float) * 8u})));
skipconv_outputs.push_back(std::make_unique<CpuFlatTensorBuffer>(
skipconv_Results, skipconv_batchTensors.back().get()));
skipconv_inputsPtr.clear();
skipconv_outputsPtr.clear();
skipconv_inputsPtr.push_back(skipconv_inputs[0].get());
skipconv_outputsPtr.push_back(skipconv_outputs[0].get());
// execution
auto start_time2 = std::chrono::high_resolution_clock::now();
auto job_id2 = skipconv_runner->execute_async(skipconv_inputsPtr, skipconv_outputsPtr);
skipconv_runner->wait(job_id2.first, -1);
auto end_time2 = std::chrono::high_resolution_clock::now();
auto process_time2 = std::chrono::duration<double,std::milli>(end_time2 - start_time2).count();
LOG(INFO) << "*******************run_skipconv time is******************* " << process_time2;
LOG(INFO) << "********** < skipconv > branch Done. **********";
// ======================================================== //
/************************ Pixel Shuffle *********************/
// ======================================================== //
int scale_factor = 2;
auto start_time3 = std::chrono::high_resolution_clock::now();
CPUPixel_Shuffle(mainbranch_Results, mainbranch_outSize,
mainbranch_shape.outTensorList[0].height, mainbranch_shape.outTensorList[0].width,
1, 2, right_Results);
auto end_time3 = std::chrono::high_resolution_clock::now();
auto process_time3 = std::chrono::duration<double,std::milli>(end_time3 - start_time3).count();
LOG(INFO) << "*******************run_single_pixelshuffle time is******************* " << process_time3;
auto start_time3_2 = std::chrono::high_resolution_clock::now();
CPUPixel_Shuffle(skipconv_Results, skipconv_outSize,
skipconv_shape.outTensorList[0].height, skipconv_shape.outTensorList[0].width,
1, scale_factor, left_Results);
auto end_time3_2 = std::chrono::high_resolution_clock::now();
auto process_time3_2 = std::chrono::duration<double,std::milli>(end_time3_2 - start_time3_2).count();
LOG(INFO) << "*******************run_single_pixelshuffle time is******************* " << process_time3_2;
LOG(INFO) << "********** CPU_PixelShuffle Done. **********";
int ps_height = skipconv_shape.outTensorList[0].height * scale_factor;
int ps_width = skipconv_shape.outTensorList[0].width * scale_factor;
int ps_size = skipconv_outSize;
int ps_channel = ps_size / (ps_height * ps_width);
// ======================================================== //
/************************ Sum *********************/
// ======================================================== //
auto start_time4 = std::chrono::high_resolution_clock::now();
CPUSum(left_Results, right_Results, ps_size, ps_height, ps_width, sum_Results);
auto end_time4 = std::chrono::high_resolution_clock::now();
auto process_time4 = std::chrono::duration<double,std::milli>(end_time4 - start_time4).count();
LOG(INFO) << "*******************run_sum time is******************* " << process_time4;
LOG(INFO) << "********** CPU_Sum Done. **********";
// ======================================================== //
/************************ ShiftMeanAdd *********************/
// ======================================================== //
auto start_time5 = std::chrono::high_resolution_clock::now();
CPUShiftMeanAdd(sum_Results, ps_size, ps_height, ps_width, 1, final_Results);
auto end_time5 = std::chrono::high_resolution_clock::now();
auto process_time5 = std::chrono::duration<double,std::milli>(end_time5 - start_time5).count();
LOG(INFO) << "*******************run_shiftmeanadd time is******************* " << process_time5;
LOG(INFO) << "********** CPU_ShiftMeanAdd Done. **********";
cv::Mat outimg;
int outheight = image_height*2;
int outwidth = image_width*2;
outimg.create(outheight, outwidth, CV_8UC3);
for (int h = 0; h < outheight; h++) {
for (int w = 0; w < outwidth; w++) {
for (int c = 0; c < image_channel; c++) {
outimg.at<cv::Vec3b>(h, w)[c] = final_Results[h * outwidth * image_channel + w * image_channel + c];
}
}
}
cv::imwrite("./out.jpg", outimg);
delete[] imageInitial;
delete[] imageInputs;
delete[] mainbranch_Results;
delete[] skipconv_Results;
delete[] left_Results;
delete[] right_Results;
delete[] sum_Results;
delete[] final_Results;
}
int main(int argc, char* argv[]) {
auto our_arguments = getArguments(argc, argv);
auto mainbranch_graph = xir::Graph::deserialize(our_arguments.mainbranch_path);
auto skipconv_graph = xir::Graph::deserialize(our_arguments.skipconv_path);
auto mainbranch_subgraph = get_dpu_subgraph(mainbranch_graph.get());
auto skipconv_subgraph = get_dpu_subgraph(skipconv_graph.get());
LOG(INFO) << "Create Runner for mainbranch. ";
auto mainbranch_runner = vart::Runner::create_runner(mainbranch_subgraph[0], "run");
LOG(INFO) << "Create Runner for skipconv. ";
auto skipconv_runner = vart::Runner::create_runner(skipconv_subgraph[0], "run");
LOG(INFO) << "Get in/out tensors of mainbranch. ";
auto mainbranch_inputTensors = mainbranch_runner->get_input_tensors();
auto mainbranch_outputTensors = mainbranch_runner->get_output_tensors();
LOG(INFO) << "Get in/out tensors of skipconv. ";
auto skipconv_inputTensors = skipconv_runner->get_input_tensors();
auto skipconv_outputTensors = skipconv_runner->get_output_tensors();
// // GraphInfo shapes;
// // const string baseImagePath = "./images/";
// // const string wordsPath = "./";
// Get input and output shapes
GraphInfo mainbranch_shape;
int mainbranch_inputCnt = mainbranch_inputTensors.size();
int mainbranch_outputCnt = mainbranch_outputTensors.size();
TensorShape mainbranch_inshape[mainbranch_inputCnt];
TensorShape mainbranch_outshape[mainbranch_outputCnt];
mainbranch_shape.inTensorList = mainbranch_inshape;
mainbranch_shape.outTensorList = mainbranch_outshape;
LOG(INFO) << "mainbranch_inputCnt: " << mainbranch_inputCnt;
GraphInfo skipconv_shape;
int skipconv_inputCnt = skipconv_inputTensors.size();
int skipconv_outputCnt = skipconv_outputTensors.size();
TensorShape skipconv_inshape[skipconv_inputCnt];
TensorShape skipconv_outshape[skipconv_outputCnt];
skipconv_shape.inTensorList = skipconv_inshape;
skipconv_shape.outTensorList = skipconv_outshape;
getTensorShape(mainbranch_runner.get(), &mainbranch_shape, mainbranch_inputCnt, mainbranch_outputCnt);
getTensorShape(skipconv_runner.get(), &skipconv_shape, skipconv_inputCnt, skipconv_outputCnt);
printTensorShape(mainbranch_shape, mainbranch_inputCnt, mainbranch_outputCnt);
printTensorShape(skipconv_shape, skipconv_inputCnt, skipconv_outputCnt);
/* run the model with batch */
// mainbranch_runner, skipconv_runner, mainbranch_shape, skipconv_shape, our_arguments
runWDSR(mainbranch_runner.get(), skipconv_runner.get(),
mainbranch_shape, skipconv_shape, our_arguments);
return 0;
}
#
# Copyright 2019 Xilinx Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1
CXX=${CXX:-g++}
os=`lsb_release -a | grep "Distributor ID" | sed 's/^.*:\s*//'`
os_version=`lsb_release -a | grep "Release" | sed 's/^.*:\s*//'`
arch=`uname -p`
target_info=${os}.${os_version}.${arch}
install_prefix_default=$HOME/.local/${target_info}
$CXX --version
result=0 && pkg-config --list-all | grep opencv4 && result=1
if [ $result -eq 1 ]; then
OPENCV_FLAGS=$(pkg-config --cflags --libs-only-L opencv4)
else
OPENCV_FLAGS=$(pkg-config --cflags --libs-only-L opencv)
fi
name=wdsr
if [[ "$CXX" == *"sysroot"* ]];then
$CXX -O2 -fno-inline -I. \
-I=/usr/include/opencv4 \
-I=/install/Debug/include \
-I=/install/Release/include \
-L=/install/Debug/lib \
-L=/install/Release/lib \
-o $name -std=c++17 \
$PWD/main.cpp \
$PWD/our_common.cpp \
-lvart-runner \
${OPENCV_FLAGS} \
-lopencv_videoio \
-lopencv_imgcodecs \
-lopencv_highgui \
-lopencv_imgproc \
-lopencv_core \
-lglog \
-lxir \
-lunilog \
-lpthread
else
$CXX -O2 -fno-inline -I. \
-I${install_prefix_default}.Debug/include \
-I${install_prefix_default}.Release/include \
-L${install_prefix_default}.Debug/lib \
-L${install_prefix_default}.Release/lib \
-Wl,-rpath=${install_prefix_default}.Debug/lib \
-Wl,-rpath=${install_prefix_default}.Release/lib \
-o $name -std=c++17 \
$PWD/main.cpp \
$PWD/our_common.cpp \
-lvart-runner \
${OPENCV_FLAGS} \
-lopencv_videoio \
-lopencv_imgcodecs \
-lopencv_highgui \
-lopencv_imgproc \
-lopencv_core \
-lglog \
-lxir \
-lunilog \
-lpthread
fi
/*
* Copyright 2019 Xilinx Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include "our_common.h"
#include <cassert>
#include <numeric>
struct Arguments getArguments(int argc, char* argv[]) {
struct Arguments our_arguments;
if (argc < 7)
{
std::cerr << "Usage of WDSR demo: ./laparpp num_threads mainbranch_path skipconv_path random_image \
height width [input_path]";
exit(1);
}
try {
our_arguments.num_threads = atoi(argv[1]);
our_arguments.mainbranch_path = argv[2];
our_arguments.skipconv_path = argv[3];
our_arguments.height = atoi(argv[4]);
our_arguments.width = atoi(argv[5]);
our_arguments.random_image = bool(atoi(argv[6]));
}
catch (...) {
LOG(INFO) << "Fail to assign values. " ;
}
if (our_arguments.random_image == false) {
try {
our_arguments.input_path = argv[7];
}
catch (...) {
std::cerr << "Fail to get input path of the images." ;
exit(1);
}
}
LOG(INFO) << "====================== Basic Information ======================" ;
LOG(INFO) << "number of threads: " << our_arguments.num_threads ;
LOG(INFO) << "mainbranch model path: " << our_arguments.mainbranch_path ;
LOG(INFO) << "skipconv model path: " << our_arguments.skipconv_path ;
LOG(INFO) << "image height: " << our_arguments.height ;
LOG(INFO) << "image width: " << our_arguments.width ;
if (our_arguments.random_image == true) {
LOG(INFO) << "Use random image. " ;
}
else {
LOG(INFO) << "input image path: " << our_arguments.input_path ;
}
return our_arguments;
}
int getTensorShape(vart::Runner* runner, GraphInfo* shapes, int cntin,
int cntout) {
auto outputTensors = runner->get_output_tensors();
auto inputTensors = runner->get_input_tensors();
if (shapes->output_mapping.empty()) {
shapes->output_mapping.resize((unsigned)cntout);
std::iota(shapes->output_mapping.begin(), shapes->output_mapping.end(), 0);
}
for (int i = 0; i < cntin; i++) {
auto dim_num = inputTensors[i]->get_shape().size();
if (dim_num == 4) {
shapes->inTensorList[i].channel = inputTensors[i]->get_shape().at(3);
shapes->inTensorList[i].width = inputTensors[i]->get_shape().at(2);
shapes->inTensorList[i].height = inputTensors[i]->get_shape().at(1);
shapes->inTensorList[i].size =
inputTensors[i]->get_element_num() / inputTensors[0]->get_shape().at(0);
} else if (dim_num == 2) {
shapes->inTensorList[i].channel = inputTensors[i]->get_shape().at(1);
shapes->inTensorList[i].width = 1;
shapes->inTensorList[i].height = 1;
shapes->inTensorList[i].size =
inputTensors[i]->get_element_num() / inputTensors[0]->get_shape().at(0);
}
}
for (int i = 0; i < cntout; i++) {
auto dim_num = outputTensors[shapes->output_mapping[i]]->get_shape().size();
if (dim_num == 4) {
shapes->outTensorList[i].channel =
outputTensors[shapes->output_mapping[i]]->get_shape().at(3);
shapes->outTensorList[i].width =
outputTensors[shapes->output_mapping[i]]->get_shape().at(2);
shapes->outTensorList[i].height =
outputTensors[shapes->output_mapping[i]]->get_shape().at(1);
shapes->outTensorList[i].size =
outputTensors[shapes->output_mapping[i]]->get_element_num() /
outputTensors[shapes->output_mapping[0]]->get_shape().at(0);
} else if (dim_num == 2) {
shapes->outTensorList[i].channel =
outputTensors[shapes->output_mapping[i]]->get_shape().at(1);
shapes->outTensorList[i].width = 1;
shapes->outTensorList[i].height = 1;
shapes->outTensorList[i].size =
outputTensors[shapes->output_mapping[i]]->get_element_num() /
outputTensors[shapes->output_mapping[0]]->get_shape().at(0);
}
}
return 0;
}
static int find_tensor(std::vector<const xir::Tensor*> tensors,
const std::string& name) {
int ret = -1;
for (auto i = 0u; i < tensors.size(); ++i) {
if (tensors[i]->get_name().find(name) != std::string::npos) {
ret = (int)i;
break;
}
}
assert(ret != -1);
return ret;
}
int getTensorShape(vart::Runner* runner, GraphInfo* shapes, int cntin,
std::vector<std::string> output_names) {
for (auto i = 0u; i < output_names.size(); ++i) {
auto idx = find_tensor(runner->get_output_tensors(), output_names[i]);
shapes->output_mapping.push_back(idx);
}
getTensorShape(runner, shapes, cntin, (int)output_names.size());
return 0;
}
void ListImages(string const& path, vector<string>& images) {
/**
* @brief put image names to a vector
*
* @param path - path of the image direcotry
* @param images - the vector of image name
*
* @return none
*/
images.clear();
struct dirent* entry;
/*Check if path is a valid directory path. */
struct stat s;
lstat(path.c_str(), &s);
if (!S_ISDIR(s.st_mode)) {
fprintf(stderr, "Error: %s is not a valid directory!\n", path.c_str());
exit(1);
}
DIR* dir = opendir(path.c_str());
if (dir == nullptr) {
fprintf(stderr, "Error: Open %s path failed.\n", path.c_str());
exit(1);
}
while ((entry = readdir(dir)) != nullptr) {
if (entry->d_type == DT_REG || entry->d_type == DT_UNKNOWN) {
string name = entry->d_name;
string ext = name.substr(name.find_last_of(".") + 1);
if ((ext == "JPEG") || (ext == "jpeg") || (ext == "JPG") ||
(ext == "jpg") || (ext == "PNG") || (ext == "png")) {
images.push_back(name);
}
}
}
closedir(dir);
}
void LoadWords(string const& path, vector<string>& kinds) {
/**
* @brief load kinds from file to a vector
*
* @param path - path of the kinds file
* @param kinds - the vector of kinds string
*
* @return none
*/
kinds.clear();
ifstream fkinds(path);
if (fkinds.fail()) {
fprintf(stderr, "Error : Open %s failed.\n", path.c_str());
exit(1);
}
string kind;
while (getline(fkinds, kind)) {
kinds.push_back(kind);
}
fkinds.close();
}
void printTensorShape(GraphInfo shapes, int input_num, int output_num)
{
// print input tensor list
LOG(INFO) << "========== Input Tensor List ==========" ;
struct TensorShape* inTensorList = shapes.inTensorList;
for (int i = 0; i < input_num; i++) {
LOG(INFO) << "< " << inTensorList[i].size <<
", " << inTensorList[i].channel <<
", " << inTensorList[i].height <<
", " << inTensorList[i].width << " >.";
}
// print output tensor list
LOG(INFO) << "========== Output Tensor List ==========" ;
struct TensorShape* outTensorList = shapes.outTensorList;
for (int i = 0; i < output_num; i++) {
LOG(INFO) << "< " << outTensorList[i].size <<
", " << outTensorList[i].channel <<
", " << outTensorList[i].height <<
", " << outTensorList[i].width << " >.";
}
return ;
}
void CPUMulSum(std::vector<std::unique_ptr<xir::Tensor>> inputs_1,
std::vector<std::unique_ptr<xir::Tensor>> inputs_2)
{
}
/*
* Copyright 2019 Xilinx Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef __OUR_COMMON_H__
#define __OUR_COMMON_H__
#include <glog/logging.h>
#include <sys/stat.h> // store the status information for a file
#include <iostream>
#include <algorithm>
#include <fstream>
#include <mutex> // std::mutex, a lockable object for multithreading programming
#include <stdlib.h> // some general purpose functions, e.g., dynamic memory management,
// random generation, communication, sorting, stc.
#include <unistd.h> // standard constants and types
#include <chrono> // date and time utilities
#include <assert.h>
#include <dirent.h> // retrieve information about files and directories
#include <stdio.h>
#include <opencv2/opencv.hpp>
#include <queue>
#include <string>
#include <thread>
#include <vector>
#include <cmath>
/* header file for Vitis AI unified API */
#include <vart/mm/host_flat_tensor_buffer.hpp>
#include <vart/runner.hpp>
#include <vart/runner_ext.hpp>
#include <xir/graph/graph.hpp>
#include <xir/tensor/tensor.hpp>
#include <xir/util/data_type.hpp>
struct Arguments {
// 0 file name
int num_threads = 1; // 1
std::string mainbranch_path; // 2
std::string skipconv_path; // 3
// int channel = 1;
int height = 360; // 4
int width = 640; // 5
bool random_image = true; // 6
std::string input_path; // 7
};
struct TensorShape {
unsigned int height;
unsigned int width;
unsigned int channel;
unsigned int size;
};
struct GraphInfo {
struct TensorShape* inTensorList;
struct TensorShape* outTensorList;
std::vector<int> output_mapping;
};
struct Arguments getArguments(int argc, char* argv[]);
int getTensorShape(vart::Runner* runner, GraphInfo* shapes, int cntin,
const std::vector<std::string> output_names);
int getTensorShape(vart::Runner* runner, GraphInfo* shapes, int cntin,
int cnout);
void printTensorShape(GraphInfo shapes, int input_num, int output_num);
inline std::vector<std::unique_ptr<xir::Tensor>> cloneTensorBuffer(
const std::vector<const xir::Tensor*>& tensors) {
auto ret = std::vector<std::unique_ptr<xir::Tensor>>{};
auto type = xir::DataType::FLOAT;
ret.reserve(tensors.size());
for (const auto& tensor : tensors) {
ret.push_back(std::unique_ptr<xir::Tensor>(
xir::Tensor::create(tensor->get_name(), tensor->get_shape(),
xir::DataType{type, sizeof(float) * 8u})));
}
return ret;
}
inline std::vector<const xir::Subgraph*> get_dpu_subgraph(
const xir::Graph* graph) {
auto root = graph->get_root_subgraph();
auto children = root->children_topological_sort();
auto ret = std::vector<const xir::Subgraph*>();
for (auto c : children) {
CHECK(c->has_attr("device"));
auto device = c->get_attr<std::string>("device");
if (device == "DPU") {
ret.emplace_back(c);
}
}
return ret;
}
class CpuFlatTensorBuffer : public vart::TensorBuffer {
public:
explicit CpuFlatTensorBuffer(void* data, const xir::Tensor* tensor)
: TensorBuffer{tensor}, data_{data} {}
virtual ~CpuFlatTensorBuffer() = default;
public:
virtual std::pair<uint64_t, size_t> data(
const std::vector<int> idx = {}) override {
uint32_t size = std::ceil(tensor_->get_data_type().bit_width / 8.f);
if (idx.size() == 0) {
return {reinterpret_cast<uint64_t>(data_),
tensor_->get_element_num() * size};
}
auto dims = tensor_->get_shape();
auto offset = 0;
for (auto k = 0; k < tensor_->get_shape().size(); k++) {
auto stride = 1;
for (auto m = k + 1; m < tensor_->get_shape().size(); m++) {
stride *= dims[m];
}
offset += idx[k] * stride;
}
auto elem_num = tensor_->get_element_num();
return {reinterpret_cast<uint64_t>(data_) + offset * size,
(elem_num - offset) * size};
}
private:
void* data_;
};
void ListImages(string const& path, vector<string>& images);
void LoadWords(string const& path, vector<string>& kinds);
void CPUMulSum(std::vector<std::unique_ptr<xir::Tensor>> inputs_1, std::vector<std::unique_ptr<xir::Tensor>> inputs_2);
#endif
import torch
from torch import nn
class ResBlock(nn.Module):
def __init__(self, n_feats, expansion_ratio, res_scale=1.0):
super(ResBlock, self).__init__()
self.res_scale = torch.tensor(res_scale)
self.module = nn.Sequential(
nn.Conv2d(n_feats, n_feats * expansion_ratio, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(n_feats * expansion_ratio, n_feats, kernel_size=3, padding=1)
)
def forward(self, x):
return x + self.module(x)# * self.res_scale
class MainBranch(nn.Module):
def __init__(self, args):
super(MainBranch, self).__init__()
head = [nn.Conv2d(3, args.n_feats, kernel_size=3, padding=1)]
body = [ResBlock(args.n_feats, args.expansion_ratio, args.res_scale) for _ in range(args.n_res_blocks)]
tail_conv = [nn.Conv2d(args.n_feats, 3 * (args.scale ** 2), kernel_size = 3, padding=1)]
self.head = nn.Sequential(*head)
self.body = nn.Sequential(*body)
self.tail_conv = nn.Sequential(*tail_conv)
def forward(self, x):
x_1 = self.head(x)
x_2 = self.body(x_1)
x_3 = self.tail_conv(x_2)
return x_3
import torch
from torch import nn
class SkipConv(nn.Module):
def __init__(self, args):
super(SkipConv, self).__init__()
self.skip = nn.Conv2d(3, 3 * (args.scale ** 2), kernel_size = 5, padding=2)
def forward(self, x):
return self.skip(x)
from utils import *
import torch
from pytorch_nndct.apis import torch_quantizer, dump_xmodel
if __name__ == '__main__':
args = get_args()
channel = args.channel
height = args.height
width = args.width
# original = torch.load('epoch_30.pth',map_location=torch.device('cpu'))
# new={"model_state_dict":original["model_state_dict"]}
if args.model == 'skip':
from SkipConv import SkipConv
model = SkipConv(args)
model.load_state_dict(torch.load('skip.pth',map_location=torch.device('cpu')))
elif args.model == 'main':
from MainBranch import MainBranch
model = MainBranch(args)
model.load_state_dict(torch.load('main.pth',map_location=torch.device('cpu')))
else:
raise NotImplementedError("Unsupported model")
model.eval()
dummy_inputs = torch.randn([1, args.channel, args.height, args.width])
print("dummy_inputs.shape: ", dummy_inputs.shape)
quantizer = torch_quantizer('calib', model, dummy_inputs)
quantized_model = quantizer.quant_model
tune_loader = []
tune_loader.append(torch.randn([1, args.channel, args.height, args.width]))
quantizer.fast_finetune(evaluate, (quantized_model, tune_loader))
quantizer.load_ft_param()
quantizer.export_quant_config()
quantizer.export_xmodel(deploy_check=False)
quantizer = torch_quantizer('test', model, dummy_inputs)
quantized_model = quantizer.quant_model
val_loader = []
val_loader.append(torch.randn([1, args.channel, args.height, args.width]))
quantizer.fast_finetune(evaluate, (quantized_model, val_loader))
quantizer.load_ft_param()
quantizer.export_quant_config()
quantizer.export_xmodel(deploy_check=False)
os.rename('quantize_result', args.output)

Comments
Please log in or sign up to comment.