





Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Guoming Sun (gs45)
Tianyue Yuwen (ty26)
Liuhao Ouyang (lo12)
Ruitao Xu(rx9)
IntroductionWake words are words like “Hi Siri” and “OK Google”. We use these words to wake up our smart assistants and ask them to provide useful information. To protect users’ privacy and keep lower energy consumption, the wake word detection function could be moved to low-powered chips. When it detects wake word, it leaves rest of the work to other parts.
In this project, we define “yes” and “no” as wake works and tried to classify “yes”, “no” and other words with our board Arduino Nano 33 BLE Sense. We use the color of its LED light: red, green and blue to represent the different categories. We implemented wake word detection through a trained model on the board with TinyML. When people speak words around the Arduino board, it will detect them automatically.
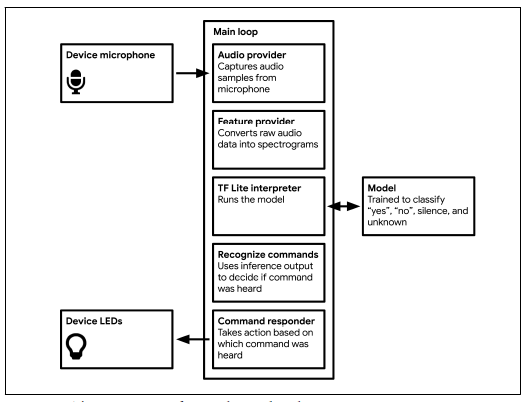
ProcessFirst, we need to obtain the input. We used the built-in microphone on Arduino Nano 33 BLE sense to obtain the raw audio for input, then we used related interface to fetch it to our program.
The we pre-process the input to extract features suitable to feed the model. After getting the audio training example, we first need to extract the features from the raw audio. It uses the FFT to transform the raw audio to a spectrogram. Then we extract the features from the spectrogram. After that we run inference on the processed input. We use this input to train our model. Our model will output a set of probabilities of the known word we say. If the probability is over a threshold, we can say the word we speak is that word over the probability.
The model we use is trained to recognize the words “yes”, “no”, unknown words, and silence or background noise. It inputs one second worth of data each time. It outputs four probability scores, one for each of these four classes. It can predict what kind of classes the data is. The model doesn’t take in raw audio sample data. Instead, it works with spectrograms.
One second worth of data is a spectrogram represented as a 2D array with 43 columns and 49 rows. For each row, we run a 30ms slice of audio input through a Fast Fourier transform algorithm (FFT), which analyzes and creates an array of 256 frequency buckets. Then we average together into 6 groups.To build the entire 2D array, we combine the results on 49 consecutive 30ms slices of audio, with each slice overlapping the last by 10ms.
Since a spectrogram is a 2D array, we feed it into the model as a 2D tensor. We use convolutional networks which can be used with any multidimensional vector input. It turns out they are very well suited to working with spectrogram data.
After running the program on computer, we deploy it on the Arduino Nano 33 BLE Sense board by using the Arduino. And track the result by both seeing the lights on the board and Arduino’s tool serial monitor.
ResultWe run the program on Arduino Nano 33 BLE Sense board, it can distinguish yes, no and other unknown words.
In this project, we deployed a trained audio classification model to the Arduino Nano 33 BLE Sense with TinyML. In this way, we successfully implemented the wake word detection function on the low-powered chip, thus making privacy-secure and energy-saving digital assistance possible.






{kind=link}
Comments
Please log in or sign up to comment.