

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
This application implements the wake word example from Tensorflow Lite for Microcontrollers on the Raspberry Pi Pico.
The wake word example shows how to run a 20 kB neural network that can detect 2 keywords, "yes" and "no". More information about this example is available on the Tensorflow Lite Micro examples folder.
We use as input an electret microphone to detect the words "yes" or "no" and turn the on-device LED on and off in response.
DemoBecause of my slight northern English accent, I struggle to get the demo consistently working with my own voice (even the high quality OS X version). Here is a clip of me placing my microphone next to my speaker for somebody else to say "yes".
OverviewThe micro_speech app for the Raspberry Pi Pico is an adaptation taken from the "Wake-Word" example on Tensorflow Lite for Microcontrollers. Pete Warden's and Daniel Situnayake's TinyMLbook gives an in-depth look into how this model works and how to train your own. This repository ports the example to work on the Pico.
The application works by listening to the microphone and processing the data before sending it the model to be analyzed. The application takes advantage of Pico's ADC and DMA to listen for samples, saving the CPU to perform the complex analysis.
The Pico does not come with an onboard microphone. For this application, we use the Adafruit Electret Microphone Amplifier breakout.
Before You BeginWe will now go through the setup of the project. This section contains two sub-sections, hardware setup and software setup.
Hardware SetupAssembly
- Solder headers onto your Raspberry Pi Pico
- Solder headers onto your Adafruit Electret Microphone
Wiring
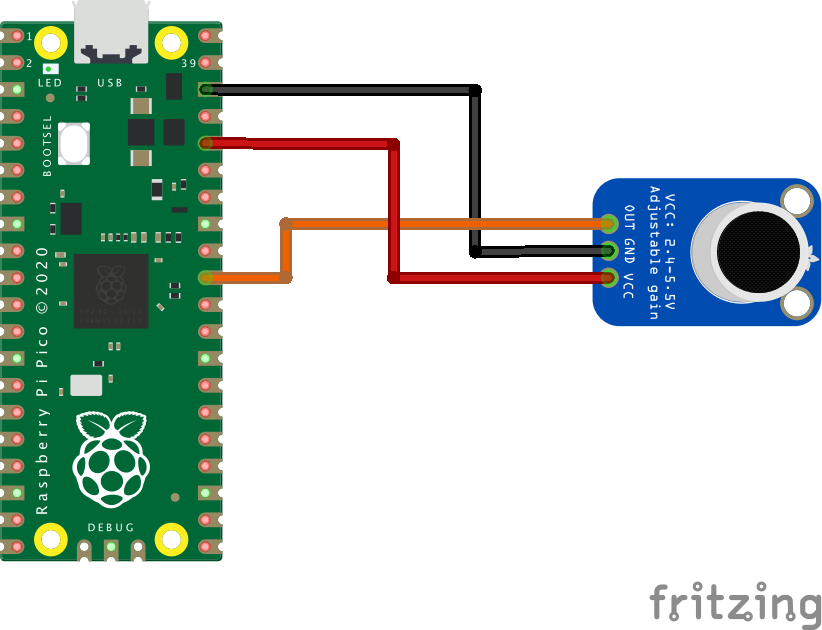
The electret microphone breakout is an analog input, meaning we can connect it to one of the ADC pins on the Raspberry Pi Pico. Make the following connections:
(in the format Microphone -> Pico)
- Out -> ADC0 - Pin31
- GND -> Any ground pin
- VCC -> 3V3(OUT) - Pin36
The final step before using this application is to set up the software stack (CMake and compilers). The easiest way to do this is to follow the steps on the Raspberry Pi Pico SDK repository. Once done you can test your toolchain setup by running some of the examples found in the Pico examples repository.
Alternatively, you can use the provided Dockerfile if you would prefer to build your application in an isolated environment.
You can now clone the application repository:
git clone https://github.com/henriwoodcock/pico-wake-word.gitWith the Pico-SDK setup on your machine, building the application is the same as building any other Pico application.
Change directory into this repository
- Change directory into this repository
cd pico-wake-word- Make a build directory
mkdir build- Generate the Makefiles
cd build
cmake ..- Finally run the Makefile
make -j8Once done, your micro_speech.uf2 file is located in build/micro_speech.
The Raspberry Pi Pico is the latest product by the Raspberry Pi foundation. It is a low-cost microcontroller board (<£4) which features the new RP2040 chip by Raspberry Pi.
The RP2040 is built on a "high-clocked" dual-core Cortex M0+ processor, making it a "remarkably" good platform for endpoint AI. Find out more about the Pico and the RP2040 from James Adams, COO, Raspberry Pi on arm.comhere.
We will now go through the changes made to the Tensorflow micro_speech example to allow it to work with the Pico. The Tensorflow team have already done a port of Tensorflow Lite Micro for the Pico.
The two files that you need to be edit for the micro_speech application are the audio_provider.cc and the command_responder.cc. The audio_provider.cc connects a device's microphone hardware to the application, and the command_responder.cc takes the model output and produces an output to react to the spoken word.
But before that, let's introduce a couple of concepts required to make this to work.
ADC
ADC stands for analog-to-digital converter. It is a system that converts an analog signal, such as the one from our microphone, and converts it to a digital signal. The Pico has four ADCs on the board (including the built-in temperature sensor), all of which can output a 12bit integer. Luckily for us, this is more than enough for our microphone.
DMA
DMA stands for Direct Memory Access. A DMA controller can write and read data directly into the main system memory without requiring the CPU.
This leaves processors free to attend to other tasks, or enter low-power sleep states, RP2040 Datasheet.
Once the DMA transfer is complete, it can create an interrupt request, allowing the CPU to process the transferred data.
RingBuffer
A ring buffer (AKA circular buffer) is a fixed-size array that acts as if the memory is continuous or a ring, meaning as the array is updated and becomes filled, data wraps around back to the start. When using a ring buffer, it is important to save the index. This way, you can always access the latest data.
We are now ready to dive into the code.
AudioProvider
The audio_provider.cc works by continuously collecting data from the microphone and saving the data into an array. This means collecting data while other parts of the code are running, so the current audio can be analysed while new audio is collected. We need to implement two functions for this to work with the rest of the application. These are `GetAudioSamples()` and LatestAudioTimestamp().
How this works:
- DMA to collect data from the microphone
- Interrupt function to clean up the collected data and put it into a ring buffer
To do this, we first make a function, setup(), this initializes the ADC, the DMA and an interrupt. For more examples on the Pico's DMA and ADC, please take a look at the Pico-Examples repository.
Let's break down this function. The first step is setting up the ADC:
#define CLOCK_DIV 3000
adc_gpio_init(26 + CAPTURE_CHANNEL);
adc_init();
adc_select_input(CAPTURE_CHANNEL);
adc_fifo_setup(
true, // Write each completed conversion to the sample FIFO
true, // Enable DMA data request (DREQ)
1, // DREQ (and IRQ) asserted when at least 1 sample present
false, // We won't see the ERR bit because of 8 bit reads; disable.
false // Shift each sample to 8 bits when pushing to FIFO
);
// set sample rate
adc_set_clkdiv(CLOCK_DIV);The final line sets the rate at which data is collected from the ADC into the FIFO. This is based on the 48MHz ADC clock. Because the `micro_speech` mode expects 16kHz input audio, we must be sampling at that rate.
For example, a CLOCK_DIV of 3000 means a sample is taken every (1 + 3000) cycles, which gives a sample rate of 48000000Hz / 3000 = 16000Hz or 16kHz.
With the ADC setup, we can now set up the DMA to transfer the data from the ADC FIFO into an array. To do this, we claim a DMA channel and set the DMA to read a set amount called NSAMP from the ADC FIFO before completing it. We do not set a write location at this step as we do this during the callback.
#define NSAMP 1024
uint dma_chan = dma_claim_unused_channel(true);
cfg = dma_channel_get_default_config(dma_chan);
// Reading from constant address, writing to incrementing byte addresses
channel_config_set_transfer_data_size(&cfg, DMA_SIZE_16);
channel_config_set_read_increment(&cfg, false);
channel_config_set_write_increment(&cfg, true);
// Pace transfers based on availability of ADC samples
channel_config_set_dreq(&cfg, DREQ_ADC);
dma_channel_configure(dma_chan, &cfg,
NULL, // dst
&adc_hw->fifo, // src
NSAMP, // transfer count
false // do no start immediately
);The last step is to create the interrupt callback and set up the callback to trigger when the DMA is complete. To do this, we first create the callback function called CaptureSamples(). A lot of this function is copied from the Tensorflow micro_speech examples, so it is helpful to get a brief understanding before reading this function. We start by defining a large array (the ring buffer), a smaller array (the buffer the DMA will write to) and a timestamp (used to calculate the index):
uint16_t g_audio_sample_buffer[NSAMP]; // the dma write location
constexpr int kAudioCaptureBufferSize = NSAMP * 16;
int16_t g_audio_capture_buffer[kAudioCaptureBufferSize]; // the ring buffer
volatile int32_t g_latest_audio_timestamp = 0;We can now define the interrupt function. When the DMA is complete, we want to calculate the index of where to store the new data in the ring buffer. This is done by converting the current timestamp into an index and using memcpy to transfer the bytes to that location.
void CaptureSamples() {
// data processing
const int number_of_samples = NSAMP;
// Calculate what timestamp the last audio sample represents
const int32_t time_in_ms = g_latest_audio_timestamp + (number_of_samples / (kAudioSampleFrequency / 1000));
// Determine the index, in the history of all samples, of the last sample
const int32_t start_sample_offset = g_latest_audio_timestamp * (kAudioSampleFrequency / 1000);
// Determine the index of this sample in our ring buffer
const int capture_index = start_sample_offset % kAudioCaptureBufferSize;
// Read the data to the correct place in our buffer
memcpy(g_audio_capture_buffer + capture_index, (void *)g_audio_sample_buffer, sizeof(int16_t)*number_of_samples);
// Clear the interrupt request.
dma_hw->ints0 = 1u << dma_chan;
// Give the channel a new wave table entry to read from, and re-trigger it
dma_channel_set_write_addr(dma_chan, g_audio_sample_buffer, true);
g_latest_audio_timestamp = time_in_ms;
}We now add the interrupt callback onto the dma channel.
dma_channel_set_irq0_enabled(dma_chan, true);
// Configure the processor to run dma_handler() when DMA IRQ 0 is asserted
irq_set_exclusive_handler(DMA_IRQ_0, CaptureSamples);
irq_set_enabled(DMA_IRQ_0, true);Finally, with all this complete, we can now start the ADC and initialize the DMA by manually calling the CaptureSamples() function.
adc_run(true); //start running the adc
CaptureSamples();CommandResponder
The command_responder.cc implements one function, RespondToCommand(). In this implementation, we will turn the onboard LED on when "yes" is said and turn the onboard LED off when "no" is said. The first part to this is initializing the onboard LED:
// led settings
static bool is_initialized = false;
const uint LED_PIN = 25;
// if not initialized, setup
if(!is_initialized) {
gpio_init(LED_PIN);
gpio_set_dir(LED_PIN, GPIO_OUT);
is_initialized = true;
}With the onboard LED initialized, we can now use the input variables to handle the output. This has two steps: the first step is to log the output into the error_reporter:
if (is_new_command) {
TF_LITE_REPORT_ERROR(error_reporter, "Heard %s (%d) @%dms", found_command,
score, current_time);
}Step two is to turn the LED on or off based on the heard command:
if (is_new_command) {
if (found_command == "yes"){
//turn led on
gpio_put(LED_PIN, 1);
}
else {
//turn led off
gpio_put(LED_PIN, 0);
}
}Putting this all together, we get the following function:
void RespondToCommand(tflite::ErrorReporter* error_reporter, int32_t current_time, const char* found_command, uint8_t score, bool is_new_command) {
// led settings
static bool is_initialized = false;
const uint LED_PIN = 25;
// if not initialized, setup
if(!is_initialized) {
gpio_init(LED_PIN);
gpio_set_dir(LED_PIN, GPIO_OUT);
is_initialized = true;
}
if (is_new_command) {
TF_LITE_REPORT_ERROR(error_reporter, "Heard %s (%d) @%dms", found_command,
score, current_time);
if (found_command == "yes"){
//turn led on
gpio_put(LED_PIN, 1);
}
else {
//turn led off
gpio_put(LED_PIN, 0);
}
}
}This project has shown how you can implement the "Wake Word" application on your Raspberry Pi Pico. The application is not perfect, and it may take some attempts for it to recognise your voice. The full code can be found on GitHub. The GitHub repository has steps on how to install the app and make changes to the app.
If you have any improvements, feel free to make a pull request!






{kind=link}
Comments