

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
With growing technology, video surveillance system are getting cheaper and affordable solution for security purpose, with that every commercial, non-commercial, offices, household and government sectors are widely using it. Retrieving person information from those surveillance video storage system is still manual, inefficient and expensive. So our focus is on this problem space.
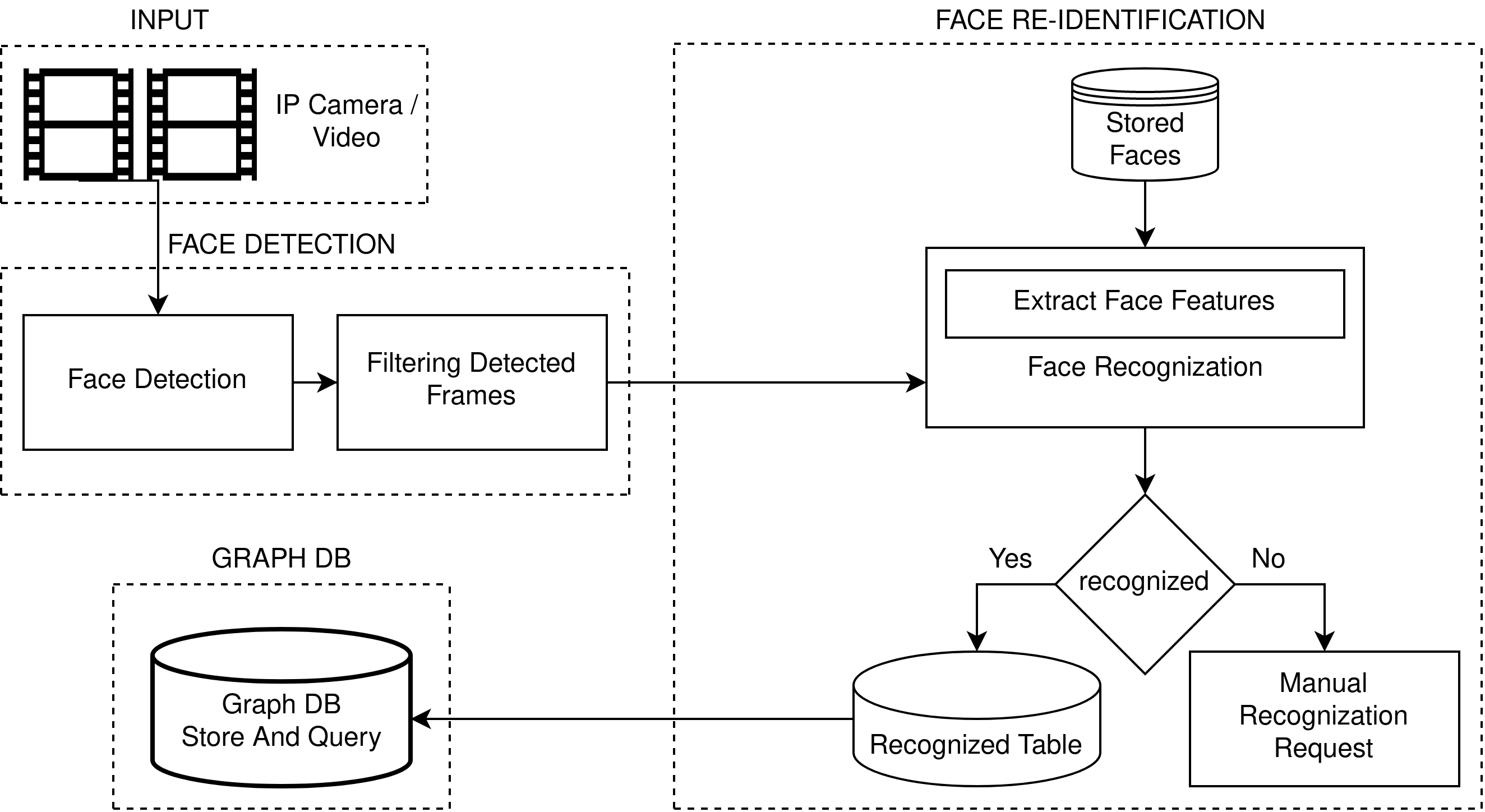
Our goal is to detect, identify and store person details from video surveillance system. In order to solve this we will be using Xilinx Vitis-ai models on VCK5000, neo4j (graph database) and spring-boot. Under Xilinx Vitis-ai models we are trying to solve this by using face-detection and face-re-identification models, which are highly efficient and optimized for this use-case. Xilinx VCK5000 Versal development card consists of 400+ AI Engines, which is suitable to process neural network very efficiently. To store and query person data, we opted neo4j, which will store data in graph format that helps in visualization and faster retrieval of data by nodes and links. Here spring-boot is used to interact with back-end pipeline and provides an user interface.
Project Planning- Started this project with creating basic block diagram
- Identified and collected all software and hardware requirements for building this project. These are shown in brief with software setup and hardware setup.
- Then started implementing each component one-by-one as per block diagram, which was described in detail in project implementation.
Block diagram:
- Install openjdk 11
- Install latest version of docker
- Install Docker - if Docker not installed on your machine yet
- Ensure your linux user is in the group docker
- Download vitis-ai docker
docker pull xilinx/vitis-ai:1.4.1.978- Clone this repository - link
git clone --recurse-submodules https://github.com/durgabhavaniv/Face_Reid_Surveillance_System.git
cd Face_Reid_Surveillance_System- Download files from, https://www.xilinx.com/member/vck5000.html#vitis, and follow below commands.
- xrt_202020.2.9.317_20.04-amd64-xrt.deb
- xilinx-vck5000-es1-gen3x16-platform-2-1_all.deb.tar.gz
- xilinx-vck5000-es1-gen3x16-2-202020-1-dev_1-3123623_all.deb
sudo apt-get insall ./xrt_202020.2.9.317_20.04-amd64-xrt.deb
tar -xzvf xilinx-vck5000-es1-gen3x16-platform-2-1_all.deb.tar.gz
cd ./xilinx-vck5000-es1-gen3x16-platform-2-1_all.deb/
sudo apt-get install ./xilinx-*
cd ..
sudo apt-get install ./xilinx-vck5000-es1-gen3x16-2-202020-1-dev_1-3123623_all.deb
cd ~/Face_Reid_Surveillance_System/setup/vck5000
source ./install.sh- Each block in this project pipeline is explained below.
- Go to this link for starting the application.
- Once application is up and running, using http://localhost:8082/, home page will get appeared as shown above.
- In this page, you need to provide camera location, date-time(yyyy-MM-dd hh:mm:ss), camera input and select all next or previous camera locations with respect to current camera location.
- Sample input video used in this project shown below.
- Once you are done with all camera inputs and their respective connections, click "next" button, which will land up you in video page.
- Add person faces which has to be re-identified in the stored_faces directory(Face_Reid_Surveillance_System/tree/master/demo/Vitis-AI-Library/stored_faces) as follows:
sai_0.jpg sai_1.jpg sai_2.jpg ....
padma_0.jpg padma_1.jpg padma_2.jpg ....
vijaya_0.jpg vijaya_1.jpg vijaya_2.jpg ....
satya_0.jpg satya_1.jpg satya_2.jpg ....Note: multiply images of same person can be added with underscore version(_*), which will improve re-identification results.
- This video page is to preview camera inputs. Once you are good with all inputs please click "process" button to start back-end pipeline.
- Here back-end pipeline starts with face detection, here are the application logs.
- Face detection consists of video decode, scale and detection process which is explained as follows.
Video decode and scale:
- Decode the input video to frames using video decoder and scale the frames to 360p.
code :
cv::VideoCapture camera(video_file_); // capture input video
video_fps = camera.get(CV_CAP_PROP_FPS); // Get video FPS
DecodeThread(int channel_id, const std::string& video_file, queue_t* queue)
: MyThread{},
channel_id_{channel_id},
video_file_{video_file},
frame_id_{0},
video_stream_{},
queue_{queue} {
open_stream();
auto& cap = *video_stream_.get();
if (is_camera_) {
cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 360);
}Face detection on decoded frame :
- Using Xilinx Vitis-ai densebox_640_360 neural network model, we are detecting faces of the person and drawing the bounding box of the person face in each frame.
Code :
int main(int argc, char *argv[]) {
std::string model = argv[1];
return vitis::ai::main_for_video_demo(
argc, argv,
[model] {
return vitis::ai::FaceDetect::create(model);
},
process_result, 2);
}- Face detection output for 5 channels is shown as below.
- Here on an average, we are able to achieve 30 FPS for 5 parallel input videos of face detection, where as each input video is of 1080p@30fps.
Cropping face :
- Crop the faces from the detected frames and then apply resizing to obtain evenly cropped images.
Code :
image_save = cv::Rect{cv::Point(r.x * image.cols, r.y * image.rows), cv::Size{(int)(r.width * image.cols), (int)(r.height * image.rows)}};
if (0 <= image_save.x // box within the image plane
&& 0 < image_save.width
&& image_save.x + image_save.width < image.cols
&& image_save.width < image.cols
&& image_save.height < image.rows
&& image.cols > 0
&& 0 <= image_save.y
&& image_save.y + image_save.height < image.rows
&& image.rows > 0 ){
croppedFaceImage = image(image_save).clone();
cv::resize(croppedFaceImage, croppedFaceImage,
cv::Size(100,100));
}Remove redundancy :
- All cropped images are compared with each other sequentially based on threshold value.
- If compare value is greater than threshold then save cropped images, else neglect cropped images.
Code :
if (toggle == 0){
toggle = 1;
old_image.cols = 100;
old_image.rows = 100;
old_image = croppedFaceImage.clone();
}
if (toggle == 1){
cv::compare(old_image , croppedFaceImage , result_cmp , cv::CMP_EQ );
cv::cvtColor(result_cmp, result_cmp, CV_BGR2GRAY);
diff = cv::countNonZero(result_cmp);
old_image = croppedFaceImage.clone();
if(diff > 3000){
bool check = cv::imwrite(path,croppedFaceImage);
count_num++;
}
}- Neglecting of redundant cropped images will reduce processing time and complexity.
- Using Xilinx Vitis-ai reid neural network model, we are extracting face features of cropped faces and stored faces.
Code :
int main(int argc, char* argv[]) {
auto model_name = argv[1];
auto det = vitis::ai::Reid::create(model_name);
...
}- Calculate the cosine distance between the cropped face features and the stored face features.
Code :
double cosine_distance(Mat feat1, Mat feat2) { return 1 - feat1.dot(feat2); }
Mat featx = det->run(imgx).feat;
Mat featy = det->run(imgy).feat;
double dismat = cosine_distance(featx, featy);- If cosine distance value is less than threshold value, then cropped face is considered as a match with stored faces and vice versa.
- Unmatched faces with time are stored in text file(output_rem.txt), which can be furture processed for manual face recognizance.
- Matched faces are stored with name and time in a text file(output.txt).
Code :
if(dismat < 0.05){
cout << file_without_extension_2 << "," << file_without_extension_3 << endl;
std::string input = file_without_extension_2 + "," + file_without_extension_3;
std::ofstream outfile;
outfile.open("/workspace/demo/Vitis-AI-Library/output/output.txt", std::ios_base::app);
outfile << input << endl;
}
else{
std::string input2 = file_without_extension_2+ ",not," + file_without_extension_3;;
std::ofstream outfile2;
outfile2.open("/workspace/demo/Vitis-AI-Library/output/output_rem.txt", std::ios_base::app);
outfile2 << input2 << endl;
}- Here output text file includes camera number, time and person name, as shown below.
1_Gate,6,sai- Here 1_Gate indicates camera name, 6 indicates time point in video file and sai indicates the recognized person name.
- Once face re-identification completed and we have generated output file, back-end process will read output file and update person to camera relationship in GraphDB.
- We can validate the same on neo4j web interface on localhost:7474 (username: neo4j, password: test).
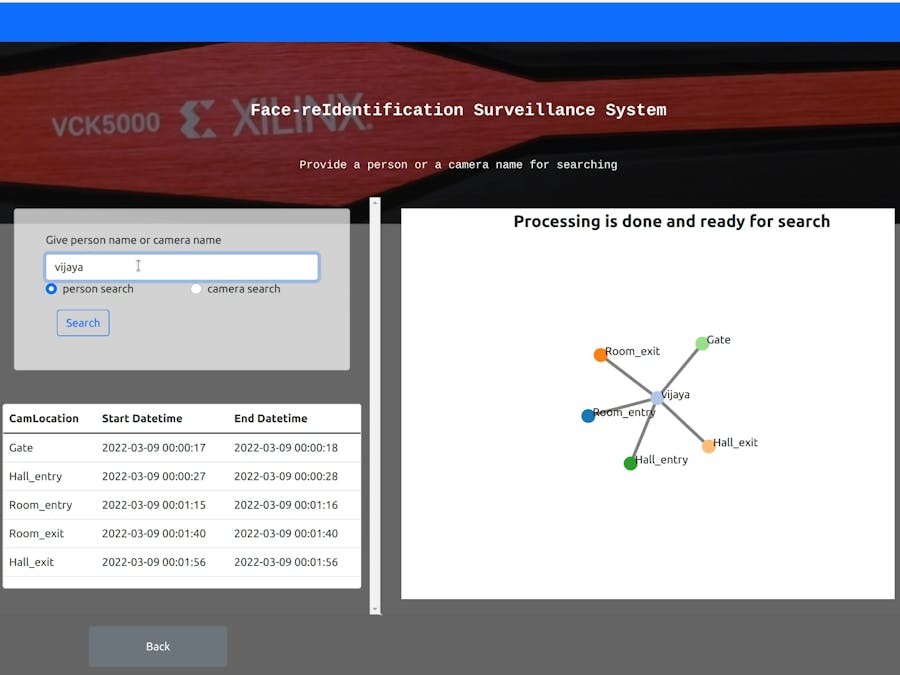
- Once process is done, we can see the massage "Processing is done and ready for search", then we can perform a search either based on person or camera name.
- The following image shows the person based search, person name will be same as stored faces file name excluding underscore version(_*).
- Here table provides information like person start and end date-time with respect to camera location, eventually we are able track person.
- As you can see along with the table information, we are generating a graphical representation to analyze person location with respect to camera.
- The following image shows camera based search.
- Here table provides information like all persons start and end date-time with respect to the camera. The graphical representation shows all persons with respect to search camera.
- If you want to start fresh process, then press back button here which redirects to home page, using delete all button you can clean up DB.
- We provide a step by step guide for working with Face-re-identification Surveillance System in the GitHub repository.
- Check for the detailed instructions in README.
- For those who want to work on full application, they can choose master branch - https://github.com/durgabhavaniv/Face_Reid_Surveillance_System/tree/master
- For those who want to work on only hardware part, they can choose master-hardware branch - https://github.com/durgabhavaniv/Face_Reid_Surveillance_System/tree/master-hardware
- Enjoy your own Face-re-identification Surveillance System.
- Using Xilinx face detection model, I am able to achieve on an average of 30FPS for processing five parallel video inputs, where as each video input is of 1080p@30fps. So this makes processing time to near real-time.
- Due to powerful Vitis-ai tool, Xilinx optimized models and high efficient FPGA(VCK5000) with AI-engine, the project implementation became smoother.
- Able to generate better visualization using GraphDb and D3js, which helps in easy understanding of complex person tracking.
- In comparison with sequential CPU processing and parallel FPGA (VCK5000) processing of face re-identification, FPGA is giving 30x performance.






{kind=link}
Comments