


Text-To-Speech(TTS) has been a very active field in AI research. The task usually takes a piece of text as input and output the wave form of this speech. In addition, in many cases people are interested in controlling the tone of the speech with some reference speech, and this task is called voice cloning. There are two variant of voice cloning: zero-shot and few-shot. Zero-shot voice cloning uses around 5s reference speech and don't
require gradient propagation, which mean this can clone on fly. Few-shot cloning uses around 1min refence speech as a finetune dataset, and is possible to capture the speaker's voice feature more vividly.
In our project, we use a model called GPT-SoVITS(https://github.com/RVC-Boss/GPT-SoVITS), a trending TTS model in the Chinese AI community recently. With relatively small model size, GPT-SoVITS is both capable of producing high quality speeches on zero-shot and few-shot voice cloning tasks.
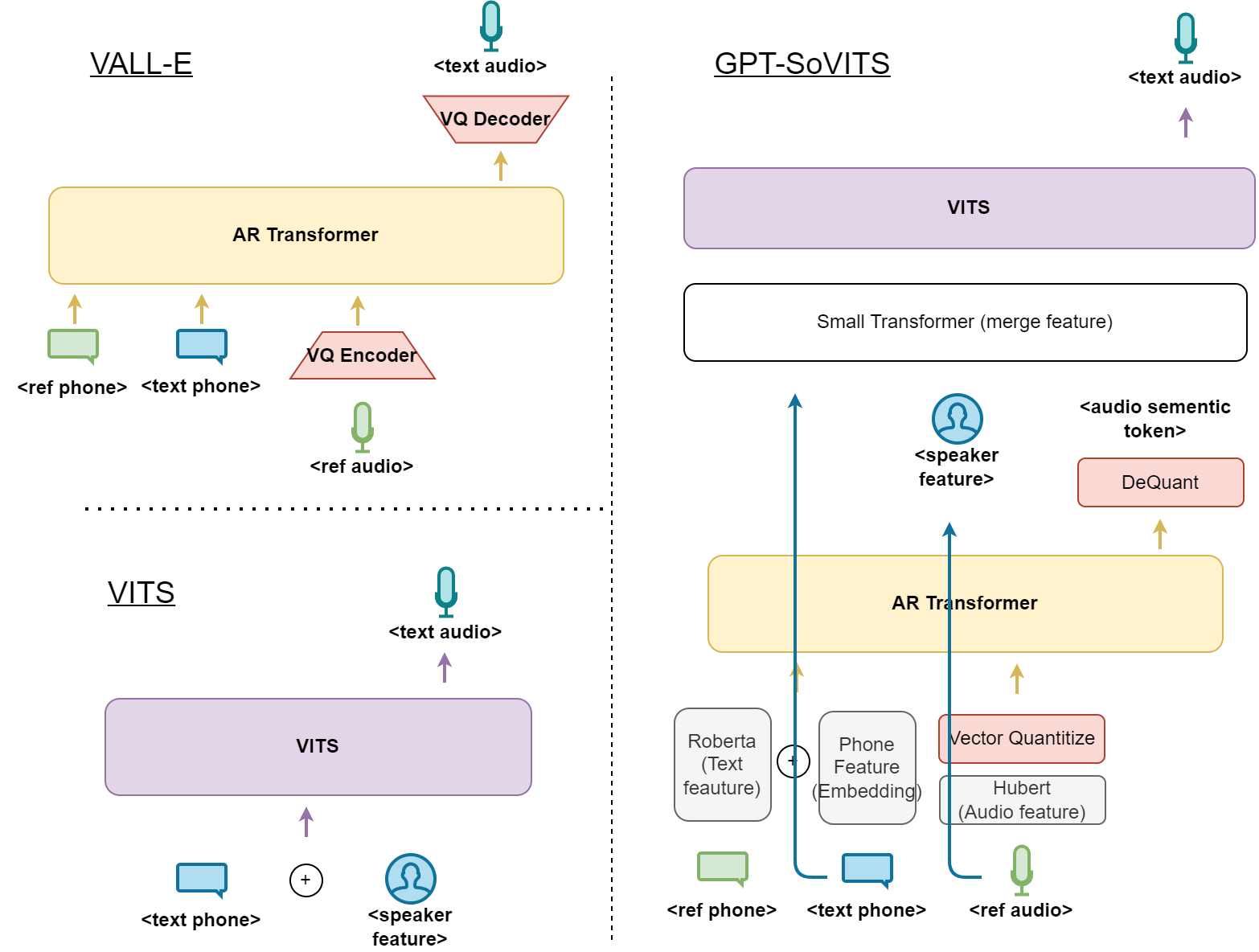
Regarding the structure, GPT-SoVITS combine two popular TTS model: VALL-E and VITS, which is respectively stage 1 and stage2. In the first stage, given text to convert, reference sound and its corresponding text, the model transform them into discrete tokens, and utilizes a autoregressive transformer to predict the sound tokens of the target speech(This is where "GPT" in the project's name come from). This strategy is initially proposed by VALL-E (https://github.com/lifeiteng/vall-e) and later widely adopted.
For VALL-E, the discrete sound tokens are produced from VQGAN trained on audio pieces ( Encodec https://github.com/facebookresearch/encodec), and token predicted by the casual transformer is mapped back to wave form through the VQGAN decoder. However, studies show TTS performance are often constrained by the VQ decoder. What's innovative about GPT-SoVITS is that is uses VITS as the discrete token decoder, which is originally capable of generate sound with high efficiency. Stacking two model together might seems redundant at first sight, but according to the project developer, this structure is effective through experiments.
The flow chart above compare the difference between VALL-E, VITS and GPT-SoVITS. It is obvious that GPT-SoVITS uses significantly more modules, including pretrain models like Hubert, Roberta-Large.
Compile on NPUThe image above demonstrate that most of the run time for GPT-SoVITS is spent on the Autoregressive transformer. Therefore, we decided to only compile this part on NPU. On the other hand it is relatively easier to compile transformer, while it would definitely be extremely challenging to compile probability flow structure used in VITS. We followed the ONNX + dynamic quantize method according to the official Ryzen AI tutorial (RyzenAI-SW/example/transformers/models/llm_onnx at main · amd/RyzenAI-SW (github.com)) and successfully compiled this component on NPU. However, because the time consumed in sending data between devices and currently small Tflops of Phoenix Point, running the model (the AR transformer part) is about 2-3 times slower than running on CPU.
The E-book readerFinally we design a E-book reader empowered by GPT-SoVITS running on NPU.
This software is a txt novel reader that integrates reading and listening functions, designed specifically for users who love literature and pursue a convenient reading experience. It not only supports traditional text reading modes, allowing users to freely adjust font size.
Here is the interface of our app.




{kind=link}
Comments
Please log in or sign up to comment.