



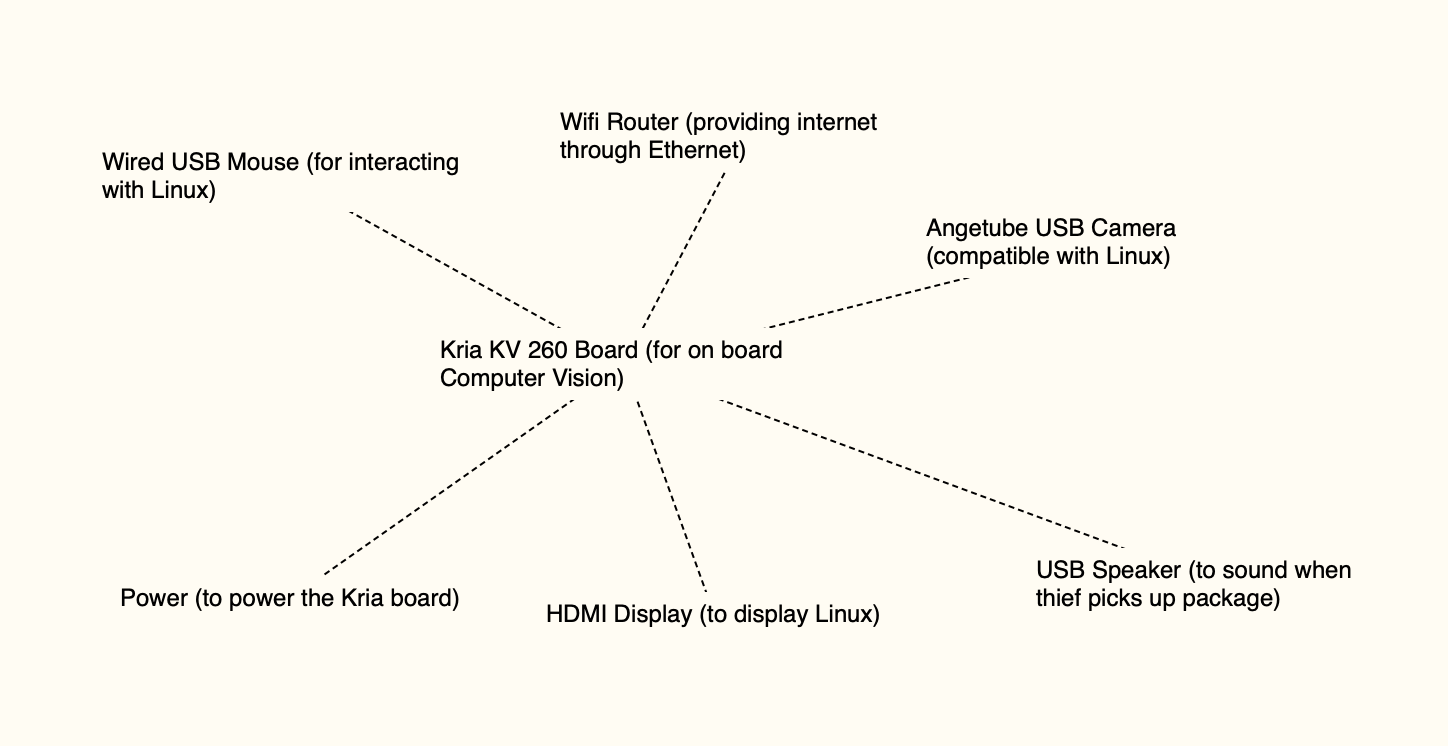
Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
In the USA, the Covid-19 pandemic coupled with government lockdown response spurred the rise of the work at home environment. Massive inflation from the FED to bail out the citizens plus the USA decision to sanction Russia for invading Ukraine drove up the price of oil further encouraged work at home life style as traveling by car became more expensive. More people ordered packages to be delivered at their front doorstep and the number of porch package thefts increased.
SolutionTo solve this porch package theft problem, existing solutions such as Amazon's Ring door bell are capable of sending a notification to the home owner when motion is detected outside of the front door. However sometimes notifications have delay or the owner has put his/her phone on Do Not Disturb. I wanted a solution that could respond to package theft in real time.
DetectionPackage theft can be detected in a number of ways. The easiest way is to detect theft is to check if the package moved upwards. The only time a package moves upwards is if the owner picks it up, or a thief picks it up. The system should allow the owner to pick up the package yet sound the alarm if a thief attempts to do so.
Ideas for sounding the alarm:
- when a thief picks up package, he/she is greeted by a loud speaker sound that says "Put it down!"
- when thief picks up package, he/she is greeted by recorded shotgun clicking sound
Ideas for allowing owner to pick up package:
- before owner picks up package, he/she hits a button to disable the package theft detection system temporarily for 1 minute allowing a window of opportunity for picking up the package
- owner picks up the package anyway. He/she already expects the theft detection response and so will not be surprised by it
In my head I imagined the end result for my prototype be something like this:
When the green rectangle moves up for a sustained period of time, ie. 10 frames, then a package theft is detected. Here is a video example: https://youtu.be/83lW-O9whUY.
I created the above Tensorflow2 mobilenet prototype by following this video
.
I also created a similar Pytorch Yolo prototype albeit with package detection accuracy by following this video
To generate the prototypes, I used these datasets:
- https://storage.googleapis.com/openimages/web/visualizer/index.html?set=train&type=segmentation&r=false&c=%2Fm%2F025dyy
- https://public.roboflow.com/object-detection/packages-dataset/6
- pictures of me holding a a brown cardboard package box at different angles and perspectives
Next I tried to load the projects to the Kria KV 260 board.
I could not load the Tensorflow mobilenet notebook because I could not download Tensorflow for ARM architecture which the Kria board is based on.
I was able to load the Pytorch yolo notebook and download the required python packages. I was not able to train the computer vision on the Kria board. Loading a pretrained yolo model seemed to work. However the performance was poor. Package detection ran at a quarter of a frame per second.
I hoped to speed up the package detection using Xilinx's Vitis AI DPU. I opened up Kria-Pynq and launched the jupyter notebook. I explored the examples and the one that caught my attention was the dpu_resnet50 notebook with the fox.
The performance looked promising: 22.489 FPS. I thought if only I could make the my package detection work with DPU then that would be fast.
I cloned Vitis-AI 1.4 and visited the AI model zoo. Then I tried replaced the dpu_resnet50.xmodel with each of the xmodels in the model zoo to see which ones worked best.
Among the results that successfully detected the fox were:
inception_v1.xmodel, inception_v2.xmodel, resnet18.xmodel, resnet50.xmodel, resnet50_tf2.xmodel, resnet_v1_101_tf.xmodel, resnet_v1_152_tf.xmodel, vgg_16_tf.xmodel
I decided to go with resnet50_tf2.xmodel. My idea was that if I could build the xmodel from scratch then I could make it detect packages.
To test out building the xmodel from scratch, I download the the resnet50_tf2 GPU version of the model and I extracted the archive into a folder. I loaded in the imagenet dataset.
I thought to myself if I prove everything works with the xmodel then I will come back later and use my custom datasets to train for package detection.
I followed the README file step by step and built the xmodel. Where I deviated was the README expects Ubuntu with Nvidia Cuda GPU whereas I used macOS Docker with CPU. I had tried
In the end although I was able to build an xmodel with macOS Docker, I was not able to load it into the dpu_resnet50 notebook in Kria Pynq because I kept getting a "RuntimeError: bad any_cast" error. This is effectively where my project stopped.
FutureLet us look at hypotheticals. If my xmodel had worked with DPU. My next step would have been to draw a green box around the package or to find a way to solve the package detection without doing that.
The DPU examples in Pynq seem to show that the computer vision targets the entire image and guesses what is in it. Perhaps I could modify my theft detection system to detect theft based on the order of detections.
Here is an example of a theft detection triggering sequence:
1. Detect no package
2. Detect a person and a package, aka the mailman is delivering
3. Detect a package
4. Detect a person, aka the thief
5. Detect no package, aka someone stole the package
6. Sound the alarm
Of course this sequence can be modified to exit early if it detects the owner is picking up the package in step 4. I will not go in depth for the sake of simplicity but I imagine their are strategies to differentiate the owner from the thief such as:
- checking if the front door opens, ie. owner opened the door to pick up the package
- checking if the car door opens, ie. owner steps out of the car to pick up the package
- checking if the owner hits a button on his/her phone that sends a bluetooth signal telling the package detection system to temporarily disable itself, ie. owner is back from a run in the neighborhood and wants to disable the porch pirate detection system temporarily as not to sound the alarm
Detecting a package is a major challenge. Typically packages come in different shapes and sizes, ranging from envelopes to cardboard boxes. This is a problem I realized while training my models. My results seems to generalize to only the image data provided. If I even slightly tilted the package held in my hand at a different angle, the model would not detect. Perhaps I just needed augmented and varied data.
{kind=link}

Comments
Please log in or sign up to comment.