



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
This is part of a LLaVA Multimodal Image Search Project I put together for the Radeon Pro category of the AMD Pervasive AI Developer Contest.
Why This Project?With the invention of smart phone cameras many people, myself included, amass a large collection of images and photos, but often find it really hard to organise and search through them. When backing up your precious memories you are left with the choice of trying to manually copying them over and organise them into folders or use something like Google Photos or iCloud Photos. Worse still for those users who have switched from an Android to an IPhone like myself I now have to manage two Cloud Photo storage systems. While these no doubt have really useful features such as the ability to use AI to tag your images, gone are the days of unlimited photo storage meaning if you want to continue to expand your large collection of images it gets petty costly. And with more people raising the alarm about privacy and your images being used to train AI models without your permission should we really be keeping our photos in the cloud without coming up with an alternative solution?
I have longed for a local photo storage, backup and search solution for a long time. Something that lets you store your images locally and does away with having to manual tag or organise your images into folders. It all started with an idea to automate this tedious manual process using the latest object detection and multimodal generative AI models that in theory should allow you to organise and search through your images and photos with ease.💡
Image Dataset UsedBefore I continue I wanted to talk about the image dataset I used. Any set of images would do for this project, however I wanted to find a set of images that are of different subjects/objects and sizes. Barring using my own personal photos, which for obvious privacy reasons I chose not to do here, I was on the hunt to find an image dataset. I needed to find one that was freely available to use and contained images depicting a number of objects and scenes that you would typically see in a personal photo collection. The most promising one I came across is from the Princeton Vision & Robotics Lab and is called the SUN (Scene UNderstanding) dataset. The full image dataset is very large at 39GB and is comprised of a total of 130, 519 images. I've included the link to this dataset here, but to make things much more manageable, I reduced this dataset down to 200 images that I chose at random from this dataset. I made sure to grab images from different categories which included photos of animals, arcades, beaches, cars, classrooms, construction sites, martial arts, shops, volleyball, volcanos, and waterfalls to name a few. The resulting dataset which I call SUN-mini is much smaller at only 235MB. I have made this new dataset available via HuggingFace datasets and it can be found here: https://huggingface.co/datasets/julieax/SUN-mini
Of course the intention is for you to follow along and use your own set of images or personal photos with this project so that it can help you keep them organised and easily searchable. The SUN-mini image dataset is only provided as an example.
PrerequisitesYou will need the following installed and setup before you can run this project. I have included the exact versions I used in (parenthesis) along with a link to the installation page for each:
- AMD Radeon 7000 series GPU (AMD Radeon Pro W7900 48GB)- Linux* (Kubuntu 22.04)- AMD ROCm (ROCm 6.1.2)- Python 3 (Python 3.10.12)- EXIFTool (EXIFTool 12.40)- Ollama (Ollama 0.2.7)- Docker (Docker 24.0.5)- PhotoPrism (PhotoPrism Build 240711)
*Note: Since Ollama is fully supported on Windows there is little stopping you from getting this project to work on a Windows operating system. That being said I have not updated or tested the multimodal-image-tagger.py Python script to work with Windows file paths. This should be trivial and I will be looking to add support for running this on Windows in the coming weeks.
The Search for a Suitable Local Photo Storage ApplicationThere are already several open sourced photo storage backup and organisation applications available. The two most popular that I found were Immich and PhotoPrism. While Immich is closer to the Google Photos experience I am after (Immich is a direct clone of Google Photos) it unfortunately does not support the use of image EXIF metadata to enhance it's image search capabilities, This meant it was out. And although I would have liked to create my own front end for this photo storage and search application, given the time and resource restrictions I opted to give PhotoPrism a try.
It's worth mentioning that I had also planned to train my own Facial Recognition model as part of this project, however I found that both Immich and PhotoPrism have very good Facial Detection systems already built-in. Luckily, this meant that I did not have to reinvent the wheel. What about the image labelling/classification abilties of PhotoPrism you might ask? That was something else entirely... 🤦
The Problem with PhotoPrism: Poor Image Search ExperienceOut-of-the-box PhotoPrism's built-in local image classification is no match at competing with Google Photo's image and object recognition. This is because PhotoPrism uses a pretrained model, NASNet Mobile 224, chosen for its small size and the speed at which it can process images. It is expected that most users will run PhotoPrism on underpowered hardware which only has access to a CPU. While this is a great idea, in practice the labels automatically created by the NASNet Mobile 224 model when uploading your images leave a lot to be desired.
To test this out I uploaded the SUN-mini image dataset to PhotoPrism without first running them through the Multimodal AI Image Tagging enhancements we will implement below. The images uploaded are the original images from the SUN-mini dataset and are missing the description and keyword EXIF data we will add automatically using the multimodal-image-taggging.py script, an AMD Radeon GPU, Ollama and the llava:34b model. As you can see from the video below sadly the out-of-the-box image classification model fails miserably as most of the things we tried to search for turn up no results. 😓
From the below image you can see that there were a number of labels (image classification categories) created by PhotoPrism. While some of these labels are accurate only a small number of objects have been detected. The majority of images and objects have been missed:
What's worse is that some of the labels seem completely random and non-intuitive. For example the image classification created a label for "indoor" which comprises of 2 images, one image of the inside of a clothing store and the other one being a martial arts class practising Karate. While the model is not wrong in categorising these two images as being "indoor" I think everyone can agree that this label is not very useful in helping us organise and make sense of our photo collection.
In another strange example of the built-in image classification gone wrong a label was created for "portrait", but the images in this label category have very little in common. As seen in the picture below this category contains a picture of two cello players, a child's bedroom, an arcade, an aquarium, a helicopter and a mannequin standing in front of a shop. Perhaps these photo were all in a portrait aspect ratio. That is the only thing I can think of that maybe lead the model to make this label, who knows. 🤷 Regardless of the reason, the label once again does not do us any good.
As you can guess this gets frustrating really quickly when all you want to do is find a fast and efficient way of organising and searching through your photo collection without having to manually create and fix labels or add descriptions and keywords to every individual photo. Luckily I've come up with a solution!
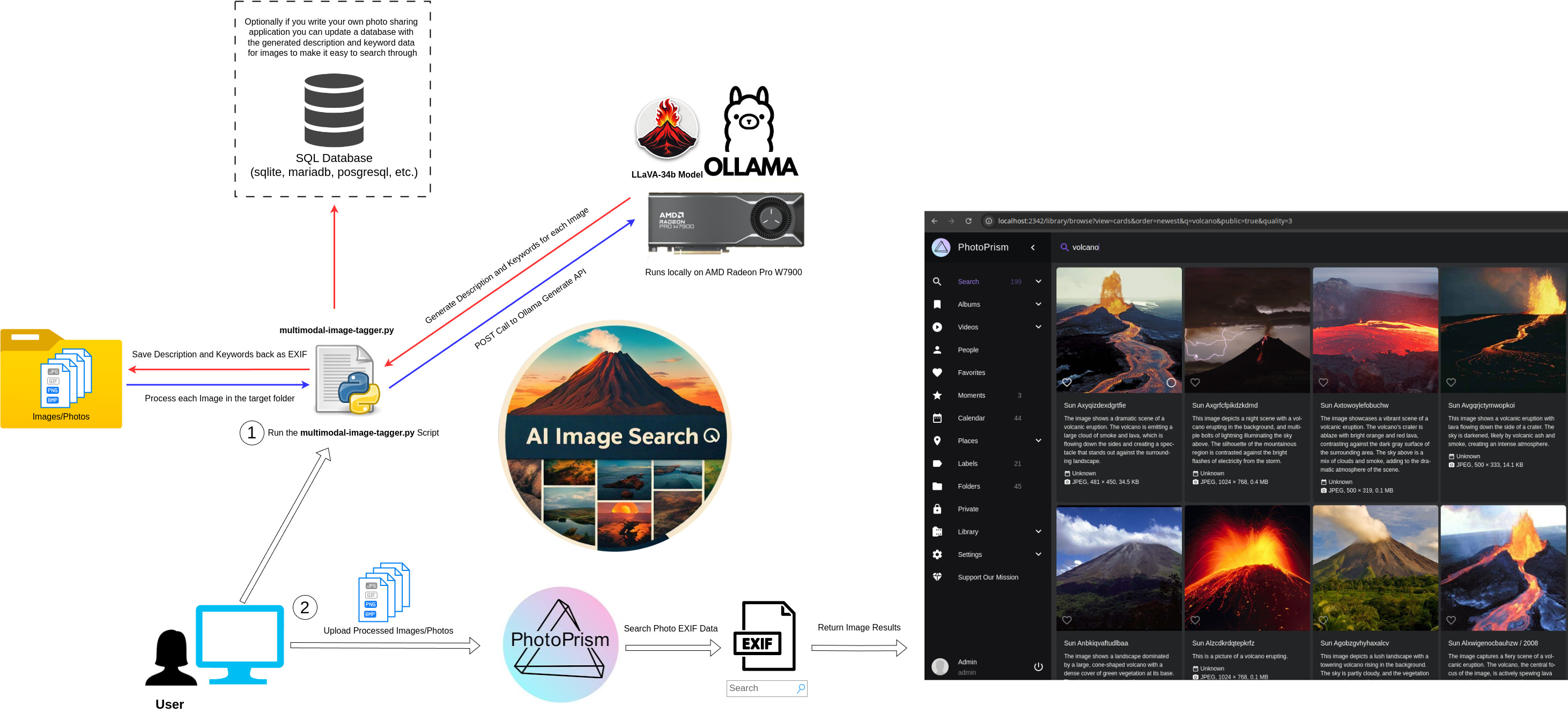
The Idea in Diagram FormWhile this diagram may be daunting at first I will try my best to explain it in the most simplest terms possible. In a nutshell this project will have you:
(1) Run a python script I put together to process images in a given folder. Each image will be read in, converted to base64 encoding and sent to the Ollama generate API along with a prompt telling it to use the LLaVA model to first generate a list of keywords for the image, then a short description of the image. Both the keywords and description will then be written back to the images EXIF data using the description and keyword field stored in each image file. I've also written the script to save this description and keyword data to a sqlite database. While this currently doesn't serve any purpose I wanted to include an example of how you could use this as part of your own image classification or photo storage system. The SQL calls in this script could very easily be updated to write to a different database such as MariaDB or PostgreSQL as part of your own custom solution.
(2) Once all the images have been processed the resulting new processed image folder can then be uploaded to PhotoPrism where we can take advantage of the EXIF data to quickly search through and find the photos we are looking for. This creates a much more seamless and enjoyable experience than what is available out-of-the-box with an application like PhotoPrism.
If you like where this is going let's get started on this project!
Installing Ollama and Downloading the LLaVA ModelWhile I am not going to cover the installation of AMD ROCm, Python, or EXIFTool (instruction for those can be found by clicking on the links provided in the Prerequisites section above) I will walk you through how to setup Ollama. While there is many ways to download and run the LLaVA model I chose Ollama as it is the easiest to setup and use. To download and install Ollama on Linux run the following:
curl -fsSL https://ollama.com/install.sh | shOnce installed you will have to decide which LLaVA model you can run. There are many to choose from on Ollama's Model Registry. The main deciding factor on which model you should choose is how much VRAM you have on your AMD GPU. Since I am using the AMD Radeon Pro W7900 I have access to 48GBs of VRAM and can easily run the largest LLaVA model at 34 billion parameters! 💪
To download llava:34b (20GB) using Ollama run:
ollama pull llava:34bAlternatively you can download a smaller LLaVA model** such as llava-llama3:8b (5.5GB):
ollama pull llava-llama3**Note: If you are using a LLaVA model other than llava:34b you will need to change the model name used in the multimodel-image-tagger.pyscripthere and here.
Once the model has finished downloading you can confirm that you have the model by running:
ollama listIn order to process your images and have them automatically tagged with description and keywords EXIF data you will need to run the python script in this projects GIT repo.
1. First let's grab the code by cloning the repository from Github:
git clone https://github.com/julieax/multimodal-ai-image-search.git
cd multimodal-ai-image-search2. Install the required python pip packages:
pip install -r requirements.txt3. Run the python image processing script and watch it process your image files. Be sure to update the --image_folder_name and --image_folder_path arguments with the folder name and path of the images you want to process.
python3 multimodal-image-tagger.py --image_folder_name="SUN-mini" --image_folder_path="/home/$USER/Documents/multimodal-ai-image-search/SUN-mini"Once the images have been processed via the `multimodal-image-tagger.py` you should see a new folder beside the original folder you had of your images. The folder will be named "[image_folder_name]-processed" and will contain the processed images each tagged with the generated descriptions and keywords from the LLaVA model.
Let's now upload these to PhotoPrism and see what kind of results we get now that we should be able to use the description and keyword EXIF data created by the image tagger script to easily search through the images to make it easier to organise and find the photos we are looking for.
Running PhotoPrism and Uploading the ImagesThere are many ways to run PhotoPrism, but by far the easiest is to run it inside a container with a single Docker run command. While this is not the proper way to run PhotoPrism long-term it will do for our demonstration:
docker run -d \
--name photoprism \
--security-opt seccomp=unconfined \
--security-opt apparmor=unconfined \
-p 2342:2342 \
-e PHOTOPRISM_UPLOAD_NSFW="true" \
-e PHOTOPRISM_ADMIN_PASSWORD="insecure" \
-v /photoprism/storage \
-v ~/Pictures/photoprism:/photoprism/originals \
photoprism/photoprismLet's break down the above docker command. We are running the latest version of PhotoPrism using the photoprism/photoprism container and giving it a name of photoprism, easy so far. We are also exposing the container on port 2342 so that the web UI can be accessed on our local machine by going to http://localhost:2342.
PHOTOPRISM_UPLOAD_NSFW="true" may look scary, but it just means that PhotoPrism will not automatically block image uploads that it thinks are NSFW. While this behaviour may be something you want it to do, in practice we have already seen how bad the default image classification is with PhotoPrism and often times you will see it will flag a bunch of images as needing to be reviewed and approved before being searchable (you can see me approving a bunch of images in the above and below PhotoPrism videos as a result).
The default username/password for PhotoPrism are admin/insecure. Although you can change the default password by updating the PHOTOPRISM_ADMIN_PASSWORD="insecure" line you really should really be finding a better way to run PhotoPrism more long term like with the Docker Compose installation method.
Lastly, additional volumes are attached to the docker container with the most notable being the -v ~/Pictures/photoprism:/photoprism/originals volume which mounts a local folder, /home/$USER/Pictures/photoprism in this case, to the containers /photoprism/orignals directory. This is the directory where all the uploaded images are stored.
Once the conatiner is up and running access the PhotoPrism Web UI by going to http://localhost:2342 and logging in with username: admin and password: insecure.
Enhanced Multimodal AI Image Search Thanks to LLaVAFinally the fruits of our labour have paid off! As you will see from the video below unlike when we first uploaded our images to PhotoPrism and got poor results, the search experience has greatly improved. Not only are we able to find and sort through our photos, but we also have descriptions for all our images. Mind you the LLaVA model's attempt at generating descriptions isn't always perfect. Under the covers PhotoPrism is now using the EXIF data that we automatically tagged every image with. The resulting descriptions and keywords contain a wealth of information that can easily be searched through. This is the kind of experience I was after all along!
Closing ThoughtsAll-in-all I learned a ton from this project, had fun doing it and will be using this project as my new local image storage and organisation solution so that I can finally move away from Google Photos, not have to worry about running out of cloud storage, and keep my photos and images private. I feel I will now be able to find more uses for the photos I've been collecting over the years and can better cherish all the memories I have made. Thank you Hackster.io and thank you AMD for hosting this contest and enabling me to do this! ❤️
If you have gotten this far and are still reading I'm hope too that you have learned something and will find some use out of this project.
Epilogue: What do I have in store for this project?I will continue to work on and improve the code in my Github repo. I am already thinking of adding new features such as support for Windows and newer multimodal models as they come out. I will also love for the multimodal image tagging to be directly integrated into the photo storage application that I am using. Whether that will end up resulting in me integrating my code directly into PhotoPrism itself or writing on my own local AI and AMD powered photo storage and search application remains to be seen... 🤔




{kind=link}
Comments
Please log in or sign up to comment.