


Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
The more I learned about Alexa and the skills offered in the Alexa app the more I wanted a skill which does not only entertain but give real value to the user. Most of the apps satisfying these criteria are dedicated to the smart home environment or (non-)commercial online services. So what you need in order to feel the value of those apps is either having the corresponding home appliance or registering an account on the service provider side. I wanted an app which provides benefits to a user right away without being a trivia app or just crawling contents out of the Internet. Therefore, what makes a good skill for Alexa is an app which could possibly not exist without a voice interface. Too many of the skills I have seen so far just solve problems with voice assistance because it is fun. But as soon as you had your fun it cannot satisfy your actual needs efficiently enough as it is either too slow or just cumbersome. The user likely returns to the familiar interfaces in order to use a service or appliance.
With all this in mind I asked myself the question: which use case does really need vocal communications between a user and a device? Somehow I started thinking of education and what one could be taught by Alexa through a voice interface. Music is a good point of start and indeed I liked the idea of one skill (“Ukulele tuner”) which aims for being your assistant in tuning your Ukulele. From music I came to general sounds which might be interesting to listen to or to learn from. This is where Morse codes came to my mind. I thought of a skill which plays back Morse codes for you so you can level up your comprehension skills. Moreover, the learning process should be arranged in exercises so it is interactive. The skill I had in mind fits most if not all of the aforementioned needs. With this conviction and an optimistic excitement, I decided for implementing the skill.
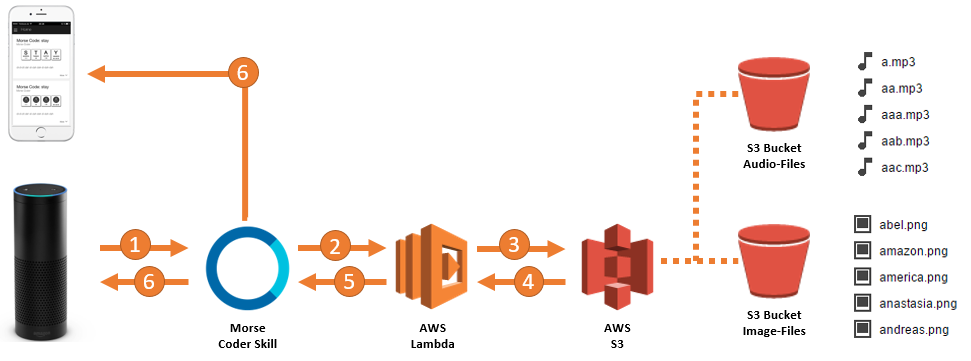
Technical solution: Audio outputThe most important parts of the skill are the audio files which contain Morse codes. In Alexa there are specific regulations on MP3s which are accepted in an audio-tag within an SSML response. To comply with these requirements, you can make use of media conversion tools like ffmpeg or AWS Elastic Transcoder. Another challenge is to have Morse codes available for any possible word as audio. Needless to say that you don’t want to have as much MP3s in your store as there are words in a dictionary of a supported language. That’s why I thought of having an MP3 for each letter of the alphabet and chain them together so they express any desired word when played back in a row. Unfortunately, Alexa limits the number of audio tags in an SSML to five per response. To not only support Morse codes of words with less than six characters I made a tradeoff. I generated and stored MP3s to S3 with all possible combinations of up to three letters which resulted in 17,576 small audio files. Therefore, I am now able to form any word with up to fifteen letters (3 letters * 5 allowed audio tags in a SSML).
All the MP3s are fully created in Java code as the sounds are monophonic and not hard to generate. Thus it is also possible to chain audio files on the fly and return it as one MP3 to Alexa. I considered this as an option to solve the problem with audio tag limitation. The reason for not doing this is increasing complexity, limited reliability and poor performance. The solution would have been something like this:
- Produce audio file as WAV in Java code
- Schedule a job in AWS Elastric Transcoder to convert to WAV to MP3
- Because the jobs work asynchronously the Lambda function handling the skill intent has to wait for a notification on transcoding complete. AWS Transcoder sends out SNS events to a topic.
- Lambda has to poll an SQS queue which is subscribed to that SNS topic, picks up the URL of the resulting MP3 file and returns it as audio in SSML to Alexa.
The asynchronous pattern of the transcoder job as well as its uncertain runtime duration makes it a risky procedure in my skill. As the output of those audio files is one of the core features this wasn't a feasible approach for me.
Each of the 17,576 MP3s is duplicated by a slower version of the same Morse code it has recorded. Therefore, this skill actually stores 35k+ audio files. These slowed down audio files are created with the exact same Java snippet with just another input parameter defining the length of a DOT (.) in a Morse code. The length of any of the other elements in a Morse code including the pauses between Morse letters and words derive from the DOT(.)-length according to an international standard. A DASH(-) is three times as long as a DOT(.) whereas a space between two words is seven DOT(.)s and so on.
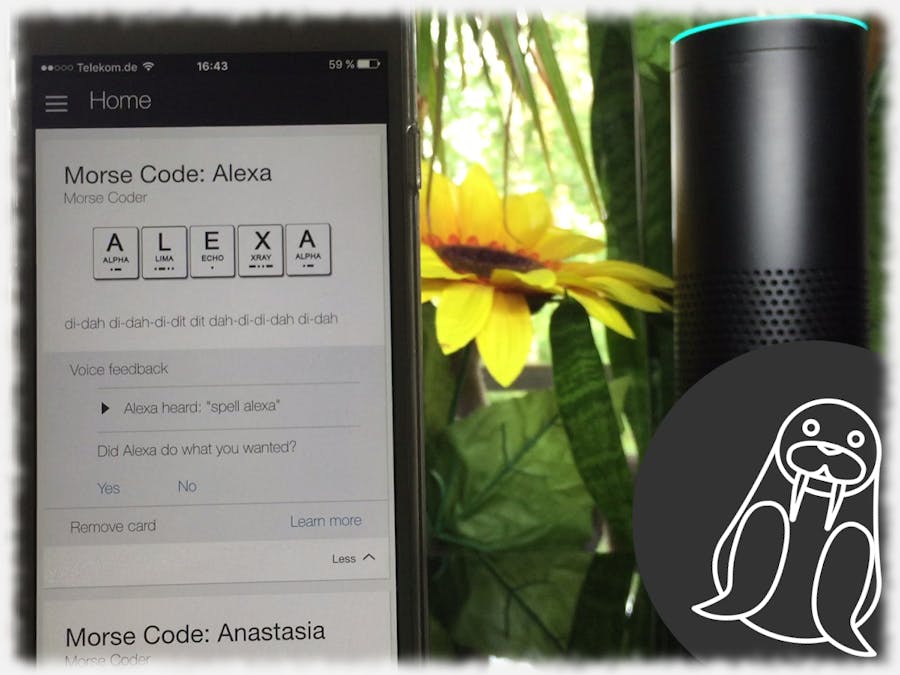
Technical solution: Images in Alexa AppAnother core feature of Morse Coder is to display a played back code in the Alexa app. I’ve got images of each letter illustrating a single Morse code, the actual letter and its corresponding code word out of the NATO phonetic alphabet (e.g. C = Charlie).
What should be displayed in Alexa app is the whole word so chaining together letter images according to the spelled out word is the easiest approach on this. Indeed, Java makes it easy to code this task and to save the resulting image representing the formed word to an S3 bucket. S3, because it is most convenient to comply with all requirements to embedded images in Alexa cards (need SSL encryption, has to have CORS configured). Finally, the limitation of Alexa to the resolution of the images needs to be taken into consideration. Due to the fact that there is no word longer than fifteen characters returned by the skill it is only a matter of a proper image arrangement within the resulting image to fit into the given resolution constraints.
There are two different images per letter. One is the aforementioned image with all the information on Morse code, literal representation and NATO code word. Another is nearly the same image but it hides the literal representation and NATO code word with the walrus logo of this skill (b.t.w. Morse is the French word for walrus). The second image will be used and displayed in the Alexa app if an exercise is ongoing and a user is asked to find out the meaning of a played back Morse code.
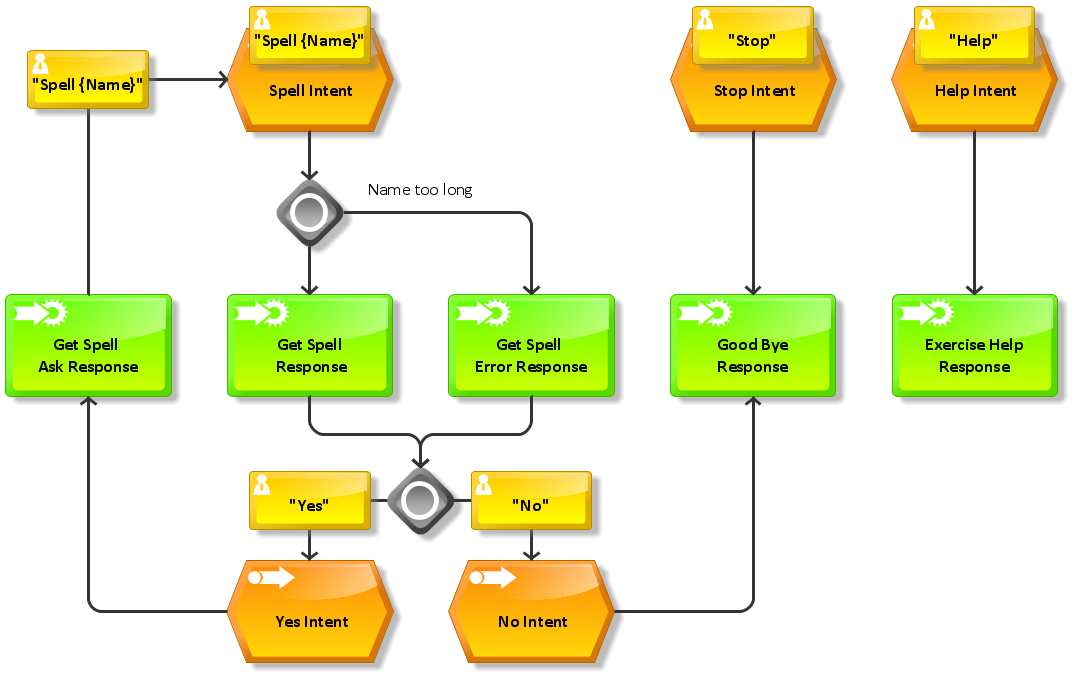
The encode feature is the first of three intents the Morse Coder can handle. It awaits a common US first name which is represented by a placeholder (also called slots in Amazon speak) in the to-be-defined utterances. One sample utterance for the encode features (indicated by the preceding “Encode”) is:
Encode play back {Name}
See complete list of utterances
Of course the skill is not limited to handling only US first names but it is not a best practice to make use of AMAZON.LITERAL as a slot type so I decided for the first names as this is a default value composition by Amazon almost all of us is familiar with. Moreover, all of us have a first name so if someone has neither an idea of nor an interest in Morse codes, can at least enjoy her own name in Morse code.
This is an example of an output in Morse Coder for the word “comprehension”. As already described the audio of Morse codes is stored in S3 in any possible combination of up to three letters. Fortunately, you cannot hear the gaps between the audio files. The maximum length of fifteen letters per word is due to the aforementioned constraint on the number of audio-tags in a SSML response.
Along with the audio play back there is a standard card sent to the Alexa app which displays the letter cards of the corresponding Morse code.
Technical solution: Spell-out featureSimilar to the Encode feature this intent is made for spelling out US first names (or better: playing back single letter Morse codes one by one). This sample utterance kicks off the feature (indicated by the preceding word “Spell” which is not part of the actual utterance):
Spell spell the name {Name}
See complete list of utterances
The Lambda function handling the request divides the received {Name} by its letters and returns their corresponding MP3-files by referencing them in audio-tags. Below example is a response spelling out the {Name} Alexa.
Along with the audio playback there is a standard card sent to the Alexa app which displays the letter cards of the corresponding Morse code.
Because of the constraint of a maximum of five audio tags per SSML response only words with up to five letters are supported in the spell-out feature. If the skill receives or word longer than five character it returns an error message.
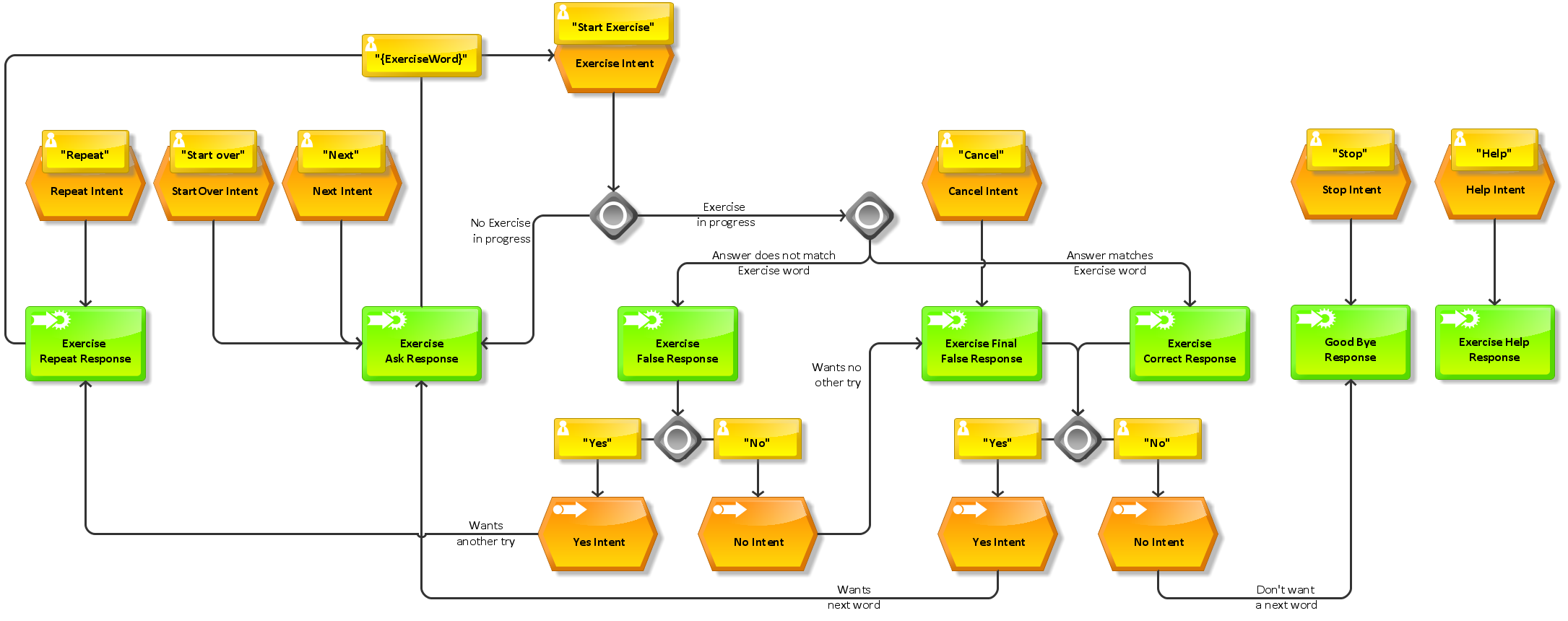
Technical solution: Exercise featureThe exercise is the core feature of the skill as it is the one who teaches the user on Morse codes by interacting with her in auditive exercises. An exercise can be started with the following utterances (where the preceding word “Exercise” indicates the intent and is not part of the actual utterance)
Exercise start exercise
See complete list of utterances
The Lambda function which reacts on this intent picks a random word out of a local file-repository of more than 2,500 words and plays it back the way it did in the encode-feature but without mentioning the literal meaning of the code. The response SSML is something like this:
Because Lambda-function and the speechlet implementation itself are stateless the given word has to be stored in the user-session. Otherwise there’s no chance for the Lambda-function to evaluate the upcoming answer as true or false. The word “funny” out of the above sample is stored in a session variable an is returned in the upcoming request triggered by the user’s answer:
Exercise {ExerciseWord}
There are more session variables used for having complex conversations with the user without losing context. E.g. for YesNo intents this means to remember the questions asked before.
Putting it all together: The skill is implemented in Java and runs in a Lambda function on AWS. The media files which are sent back to the frontend (Alexa device, Alexa app) are stored in S3 buckets.
Architecture diagram in full-size
Usability: Encode names to Morse codeIf you are interested in Morse codes expressing common US first names, go for something like:
"Alexa, ask Morse Coder to encode {Name}"
where {Name} is any common first name of your choice.
With this intent Alexa plays back the corresponding Morse code. Moreover, this skill provides the Morse code to your Alexa App.
Due to technical limitations by Amazon on audio tags this feature is only supported for names shorter than sixteen letters.
VUI diagram of encode feature in full-size
Usability: Spell out names in Morse codeSimilar to the encode feature of Morse Coder this feature lets Alexa spell out a common US first name of your choice in Morse code.
The spell-out feature is designed for newcomers who want to learn Morse code letter by letter. Try out:
"Alexa, spell out {Name}"
where {Name} is any common US first name of your choice. Once again Alexa even returns the Morse code to your Alexa App.
Due to technical limitations by Amazon on audio tags this feature is only supported for names shorter than six letters.
VUI diagram of spell-out feature in full-size
Usability: Exercises / Learn Morse CodeAs soon as you got the basics on Morse codes you can test your comprehension. Start an exercise by saying:
"Alexa, start exercise"
and Alexa starts playing a Morse code and asks you to decode and pronounce the word being played. If Alexa doesn't get what you're saying, try to spell the correct answer.
If you are not sure Alexa tries to help you by slowing down the playback speed of the code as soon as you give a wrong answer or wait for several seconds without giving an answer.
Another option to simplify things for you is to look in your Alexa App. There you can find the written Morse code along with a spelled version of it ("Di-dah-dit ...").
Actually the Alexa App is the best resource for you while exercising as you can learn a lot from the cards provided by the Morse Coder.
Optionally you can skip or cancel an exercise by saying "Next" or "Cancel". If you need help free to ask for "Help" at any time. If you want to listen to a code again, just ask Alexa to "Repeat".
You can interrupt an exercise at any time by using one of the above features ("Spell out {Name}", "Encode {Name}") and get back to the exercise just by expressing your guess to last played code. Also "Repeat" brings you back to the exercise.
The capability of switching between an exercise and the other features helps you researching for the correct answer.
VUI diagram of exercise feature in full-size
ScoringFor each word you decode correctly you get points which sum up in your personal score. The score persists throughout one session.
Alexa starts with asking you to decode a randomly picked word with five letters.
If you guess the word, Alexa increases the length of the next word. Otherwise Alexa decreases the length to make things easier for you.
Words in Morse Coder have a minimum length of three characters and a maximum length of eight characters.
The longer a word the more points you get out of an answer. Wrong answers on the other hand could degrade your score.
If you are switching between the features your score persists and doesn't get lost.
General features"Repeat" during an exercise plays back a code again in a slower version. It also is an option to get back to your exercise if you switched to the spell-out or encode feature.
"Next" or "Start over" at any time should guide you to the next random code. The current exercise will be skipped.
"Stop" quits the skill and stops the exercise. You are provided with your final score.
"Help" gives some information on what to say.
"Cancel" stops the current exercise. Alexa will give you the correct word for the current code and asks you to continue with another code.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.