



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 2 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
Update 08-15-2015: Project converted to Visual Studio 2015 RTM
Windows 10 IoT Core Speech Recognition
One of the major feature of the recently released Windows 10 IoT Core for Rapsberry Pi was USB Audio support. This features open the Speech Recognition on Raspberry Pi. Previously it was working only for MinnowBoard MAX. Here is s project I worked last weekend using this feature.
To run this project you need following items:
- Raspberry Pi 2
- USB Microphone
- 1 Red Led and 1 Green Led
- One Relay Control
- One Electrical Light
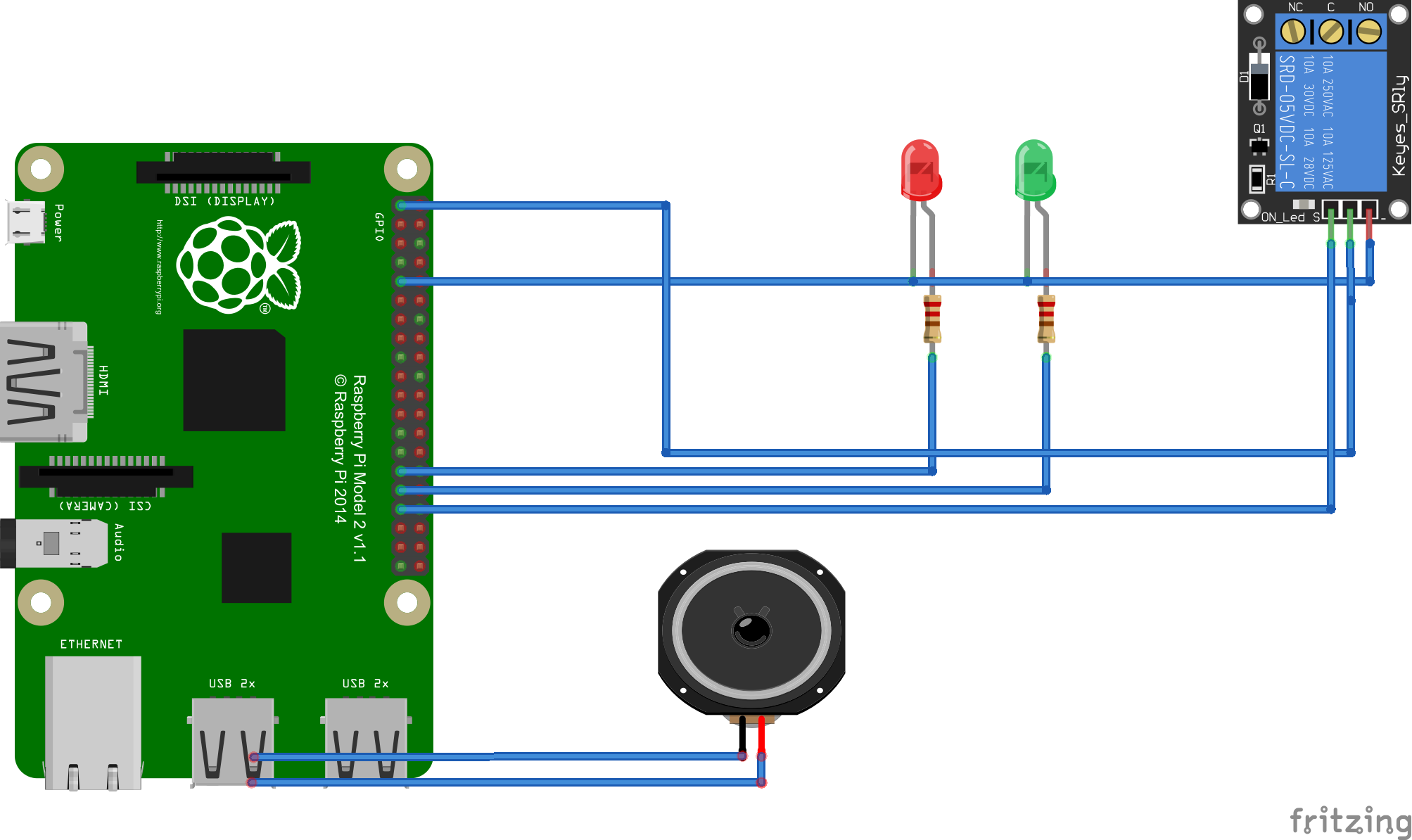
Two Leds are connected to GPIO Pins 5 and 6 respectively. The Relay control is connected to GPIO Pin 13. The light is connected to the Relay control.
Wiring
- LEDs connected to GPIO Pins 5 and 6 respectively
- Relay Control 3.3v to RPi 3.3v
- Relay Control GND to RPi GND
- Light connected to Relay Control
- USB Microphone connected to one of the USB
The project is simple Proof of Concept Home Automation device. Using this application uses voice recognition to turn on/off different devices attached to the RPi. For this POC I have attached two LEDs (one Red and another Green) and one electrical light using a single channel relay control. You can control these devices using voice. If you say "Turn on red led" then it will turn on the RED led attached to GPIO pin 5, "Turn on green led" will turn on green led attached to GPIO pin 6 and "Turn on bedroom light" will turn on electrical light attached to GPIO pin 13. This is only a Proof of Concept application but you can attach any devices to RPi and modify the application to control the devices.
Basically for grammar based speech recognition on Windows 10, you the steps:
- Create and initialize SpeechRecognition object
- Add and compile grammar file constraint
- Start a continuous speech recognition session
- Process the recognition results using the event handlers
For this application I have created a simple SRGS grammar file (attached below). You can find a detailed explanation on how to create SRGS grammer here. This link provides a simple and detailed explanation. Here is the grammar file I am using:
<?xml version="1.0" encoding="utf-8" ?>
<grammar
version="1.0"
xml:lang="en-US"
root="automationCommands"
xmlns="http://www.w3.org/2001/06/grammar"
tag-format="semantics/1.0">
<rule id="root">
<item>
<ruleref uri="#automationCommands"/>
<tag>out.command=rules.latest();</tag>
</item>
</rule>
<rule id="automationCommands">
<item>
<item> turn </item>
<item>
<ruleref uri="#commandActions" />
<tag> out.cmd=rules.latest(); </tag>
</item>
<one-of>
<item>
<ruleref uri="#locationActions" />
<tag> out.target=rules.latest(); </tag>
</item>
<item>
<ruleref uri="#colorActions" />
<tag> out.target=rules.latest(); </tag>
</item>
</one-of>
<item>
<ruleref uri="#deviceActions" />
<tag> out.device=rules.latest(); </tag>
</item>
</item>
</rule>
<rule id="commandActions">
<one-of>
<item>
on <tag> out="ON"; </tag>
</item>
<item>
off <tag> out="OFF"; </tag>
</item>
</one-of>
</rule>
<rule id="locationActions">
<one-of>
<item>
bedroom <tag> out="BEDROOM"; </tag>
</item>
<item>
porch <tag> out="PORCH"; </tag>
</item>
</one-of>
</rule>
<rule id="colorActions">
<one-of>
<item>
red <tag> out="RED"; </tag>
</item>
<item>
green <tag> out="GREEN"; </tag>
</item>
</one-of>
</rule>
<rule id="deviceActions">
<one-of>
<item>
light <tag> out="LIGHT"; </tag>
</item>
<item>
led <tag> out="LED"; </tag>
</item>
</one-of>
</rule>
</grammar> When the speech recognizer recognize words based on the grammar file provided, it calls the result generated event handler. Inside this event handler we check tags generated based on the recognized words. Tags will be generated as per the SRGS Grammar file we supplied. you can see in the grammar file we have specified some <tag> XML elements. These tags will be present on the recognition result. We can check the presence of these tags and determine what action to be performed, in this application write to particular GPIOs.
Screenshots
Demo Video
https://www.youtube.com/watch?v=MN18Uo_063g





{kind=link}
Comments