

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
The integration of large language models (LLMs) like with remote sensing interpretation tasks presents an innovative approach to addressing complex user requests. Traditional methods in remote sensing interpretation require significant human intervention for task planning and execution, limiting accessibility for non-experts. SensoGPT aims to automate these processes by utilizing LLMs to interact with various AI-based remote sensing models.
The objective of this project is to provide a comprehensive design and proof of concept for an LLM-powered agent capable of understanding user requests, planning remote sensing tasks, and generating responses. This system enhances the accessibility of remote sensing techniques and aims to fully automate remote sensing image interpretation.
SensoGPT is currently able to do the following remote sensing tasks:
Land Use Classification
- Task: Classifying different land use types within the image.
- Example: Differentiating between residential, commercial, industrial, agricultural, and natural areas.
Object Detection
- Task: Detecting and identifying objects within the image.
- Example: Identifying and locating buildings, vehicles, roads, bridges, and other structures or natural features.
Image Captioning and Classification
- Task: Generating descriptive captions for remote sensing images.
- Example: Providing a textual description of what is visible in the image, such as "Aerial view of a city with high-rise buildings and a river running through the center."
Edge Detection
- Task: Identifying and outlining the edges of objects and features within the image.
- Example: Highlighting the boundaries of fields, roads, and water bodies.
Object Counting
- Task: Counting the number of specific objects within the image.
- Example: Counting the number of cars in a parking lot, the number of trees in a forested area, or the number of ships in a harbor
Image Segmentation
- Task: Segmenting the image into different regions based on various features.
- Example: Separating urban areas from rural description and captioning
SensoGPT uses a four-step process to do it tasks:
- User Request: The user submits a remote sensing image along with a specific task request.
- Analyzation: SensoGPT analyzes the prompt and the image.
- Planning: SensoGPT plans the necessary subtasks and executes them with the required tools.
- Response: A final response is generated, providing the interpretation results and image back to the user.
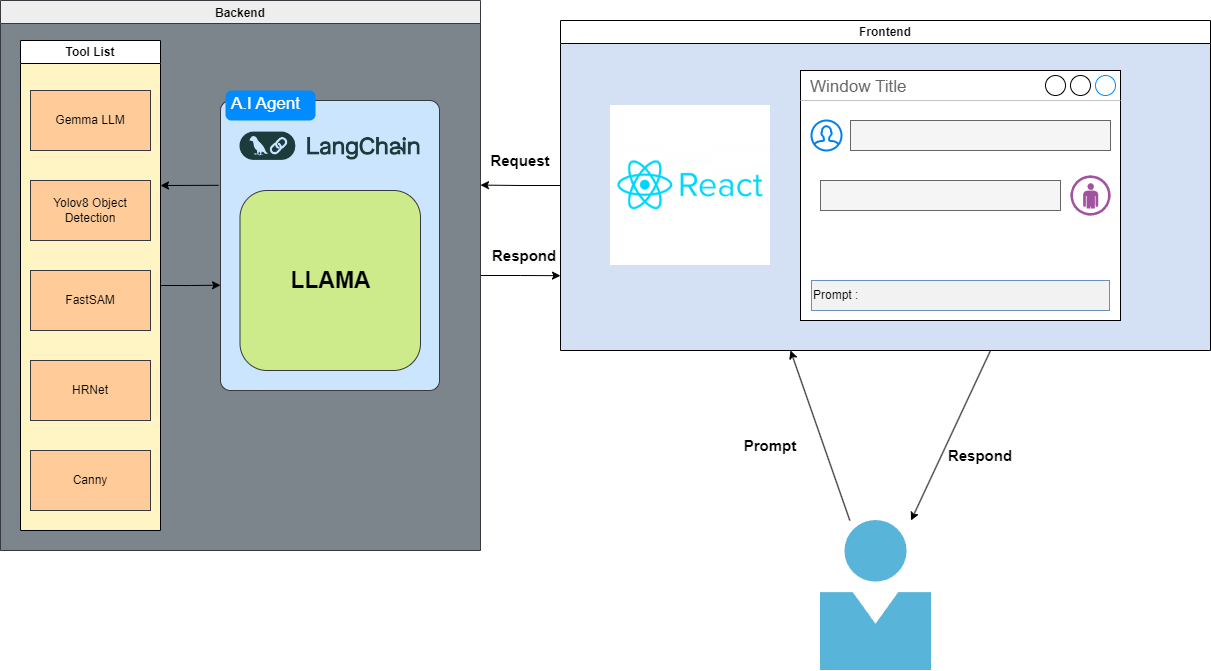
SensoGPT is a powerful and intuitive application designed for ease of use. Users simply upload an image and input a prompt. The application, built with ReactJS and utilizing Axios for requests, sends the prompt along with the serialized image data. On the backend, an AI agent developed using the LangChain Framework with LLAMA, a large language model, processes the prompt to determine the appropriate tool. This process may involve one or multiple steps, depending on the complexity of the user's request. Upon completion, the response and the processed image are sent back to the frontend and displayed in a chatbox.
5. FrontendSensoGPT client application is made entirely with ReactJS and Typescript. React is a JavaScript library for building user interfaces, primarily for single-page applications. It allows developers to create large web applications that can change data, without reloading the page.
SensoGPT UI contain many components but the most important one is the VisionContainer component. This component allow the users to have a chat with the A.I agent and make request. The component is designed to provide a seamless user experience for interacting with the remote sensing analysi services. It leverages React hooks for state and context management, ensuring efficient updates and rendering. The component handles form submission, API interactions, and displays the chat history in a user-friendly manner.
The most important function in the VisionContainer is the makeApiCall function. The makeApiCall function is an asynchronous function that sends a user prompt along with media data to a backend API. It handles the response by updating the chat history and managing loading states. This function is memoized using useCallback to prevent unnecessary re-renders.
Detailed Breakdown
1. Filtering Invalid Media Data:
- The function starts by filtering out any invalid media data from the
mediaDataList. This ensures that only valid media data is included in the API request.
const validMediaData = mediaDataList.filter(
(data) => data.data !== "" && data.mimeType !== "
)2. Preparing Media Data for the API Call:
- The function prepares the media data by removing the
data:image/...;base64,prefix from each base64-encoded media string. - It also extracts the MIME types of the media items.
- The function constructs the request body as a JSON string. This includes the message, the base64-encoded media data, the media MIME types, general settings, and safety settings.
const mediaBase64 = validMediaData.map((data) =>
data.data.replace(/^data:(image|video)\/\w+;base64,/, "")
);
const mediaTypes = validMediaData.map((data) => data.mimeType)
const body = JSON.stringify({
message,
media: mediaBase64,
media_types: mediaTypes,
general_settings: generalSettings,
safety_settings: safetySettings,
});3. Making the API Call
- The function uses the
fetchAPI to send a POST request to the backend server. The request includes the request body and headers specifying the content type as JSON.
const response = await fetch(`http://127.0.0.1:8000/run-image`, {
method: "POST",
body,
headers: {
"Content-Type": "application/json",
},
});4. Handling the Response
- If the response is not OK (i.e., the status code is not in the range of 200-299), the function throws an error.
- If the response is OK, it parses the JSON response to extract the status, prompt result, and image data.
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const responseData = await response.json();
const { status, prompt_result, image } = responseData;5. Updating the Chat History:
- The function updates the
chatHistorystate by appending the new chat entry, which includes the user's prompt, the response from the API, and the optional image data.
setChatHistory((prevChatHistory) => [
...prevChatHistory,
{ prompt: message, response: prompt_result, image: image },
]);To None, all the API is endpoint is on a backend local server that ultilize the GPU capability of the AMD Radeon Pro W7900 to do various task such as request handling, image description, image segmentation etc...
6. BackendFor the backend, Langchain is the main framework that allow for orchestrate various AI models and tools, enabling seamless interactions between different functionalities and the conversational agent.
LangChain's initialize_agent function is used to set up a conversational agent that can utilize the registered tools to perform tasks based on user inputs. LLM model I use for the agent is Nous Hermes 2 on Mistral 7B. The below show how to initialize a local Generative A.I agent
class SensoChatGPT:
def __init__(self, gpt_name, load_dict, proxy_url):
self.models = {}
for class_name, device in load_dict.items():
self.models[class_name] = globals()[class_name](device=device)
self.tools = []
for instance in self.models.values():
for e in dir(instance):
if e.startswith('inference'):
func = getattr(instance, e)
self.tools.append(Tool(name=func.name, description=func.description, func=func))
self.llm = GPT4All(model="Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf")
self.memory = ConversationBufferMemory(memory_key="chat_history", output_key='output')
def initialize(self):
self.memory.clear()
PREFIX, FORMAT_INSTRUCTIONS, SUFFIX = RS_SENSOGPT_PREFIX, RS_SENSOGPT_FORMAT_INSTRUCTIONS, RS_SENSOGPT_SUFFIX
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
stop=["\nObservation:", "\n\tObservation:"],
agent_kwargs={'prefix': PREFIX, 'format_instructions': FORMAT_INSTRUCTIONS, 'suffix': SUFFIX},
)- Model Initialization: The
__init__method initializes the necessary models and tools based on the providedload_dict. - Tool Collection: The tools are collected and added to a list that will be used by the agent.
- Agent Initialization: The
initializemethod sets up the agent usinginitialize_agentfrom LangChain, which ties together the tools, memory, and language model.
Next, I need to initialize the tools for the A.I agent to use. These tool are named such as ImageCaptioning, LanduseSegmentation, ObjectDetection etc...
# ObjectDetection class definition
class ObjectDetection:
def __init__(self, device):
self.func = DetectionFunction(device)
@prompts(name="Detect the given object",
description="Useful when you only want to detect the bounding box of certain objects in the picture according to the given text. "
"For example: detect the plane, or can you locate an object for me. "
"The input to this tool should be a comma separated string of two values: "
"representing the image_path, and the text description of the object to be found.")
def inference(self, inputs):
image_path, det_prompt = inputs.split(",")
updated_image_path = get_new_image_name(image_path, func_name="detection_" + det_prompt.replace(' ', '_'))
log_text = self.func.inference(image_path, det_prompt, updated_image_path)
return log_textThe final building to make this work is the api endpoint function. The endpoint function receive request from the frontend and pass the request and the image to the A.I agent to process its.
@app.post("/run-image")
async def run_image_endpoint(request: RequestBody):
global state
# Decode and save the images
for i, media in enumerate(request.media):
image_data = base64.b64decode(media)
image_path = f'image/{uuid.uuid4()}.png'
with open(image_path, "wb") as buffer:
buffer.write(image_data)
result_image = request.media
state, result = bot.run_image(image_path, state, txt=request.message)
result_string = result[1]
# Processing result_string to extract image paths and encode the images
# (similar logic applied based on result_string content)
return JSONResponse(content={"status": "success", "prompt_result": result_string, "image": result_image})Currently, SensoGPT is ultilizing 5 other models for various task that it can perform. Gemini is use for image caption, scence classification, and object counting. YoloV8-OBB is used for remote sensing object detection. FastSAM (Fast Segment Anything) is used along with YoloV8 for instance segmentation. HRNet is used for Landuse Segmentation and analysis. Finally, Canny Edge Detection is use to generate the edge image of the input image. Below is an example code of the ObjectDetection tool :
from ultralytics import YOLO
import os
from skimage import io
from PIL import Image
class YOLOOBB:
def __init__(self, device):
self.model = YOLO("yolov8x-obb.pt") # load an official model
def inference(self, image_path, det_prompt, updated_image_path):
image = Image.open(image_path)
results = self.model(image, save=True, show_labels=True, save_txt=False) # predict on an image
print('---------------------------------------------')
for result in results:
print(result.save_dir)
# List all files in the directory
files = os.listdir(result.save_dir)
# Filter to find the image file (assuming it has a common image file extension)
image_extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.gif', '.tiff')
image_files = [f for f in files if f.endswith(image_extensions)]
image_path_new = os.path.join(result.save_dir, image_files[0])
print(image_path_new)
return det_prompt + ' object detection result in ' + image_path_newThis script defines the ObjectDetection tool which uses the YOLO model for object detection locally. The inference method performs the following steps:
- Opens the input image.
- Runs the YOLO model on the image to detect objects.
- Saves the results and retrieves the path to the saved image.
- Returns a message indicating the result of the object detection along with the path to the saved image.
Some additional capability I'm currently working on is to have the application be able to analyze and answer question about hyperspectral image. In addition, it would be nice to give the application more generative capability in term of generating hyperspectral image or 3D view from a single RGB image.



{kind=link}
Comments