



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
 |
| |||||
 |
| |||||
 |
| |||||
Hand tools and fabrication machines | ||||||
| ||||||
The smart feeder idea in this project is a novel one because existing so called units in the market are not capable of addressing some requirements outlined in the next section. Thou the idea looks simple and people quickly might think of solutions, the problem is complex and traditional methods probably will not work very well.
Requirements.The following requirements needs to be meet.
- Control the animal food intake on a day by tracking the food type and amount per day.
- Be able to work with multiple pets of type cats and dogs.
- Track pet food intake habits and statistics.
The project originally tried to address all the requirements outlined before using the Kria AI Vision capabilities. Technical challenges arise during the contest that impact the scope of the project, without going into too much detail now it is worth to mention that for this project it is absolutely important to be able to train a custom network which was primeraly the reason of limiting the scope.
A demo is presented in which the Xilinx Kria device acquire images of our pets at home as they get close to the motorized food bowl and command it to provide food to our pet.
AI Vision for Pets with Kria (cats and dogs).The original problem can be divided into different tasks related to processing the images of the animals, similar to the pedestrian detection box example, where the XIlinx Kria example is able to track on the image any pedestrian and draw a box around it. This would be the first step. For that a similar AI model can be used, in this case it was tried a Mobilenet_SSD on VOC dataset, among the 21 classes that we can detect with VOC are dog and cat. The example design tutorial here was attempted, unfortunately due to training issues with the hardware and the caffe framework it was not possible. This example can be easily integrated into the smart camera application as described here. Further processing after getting the object coordinates can be done using the VVAS framework. The coordinates can be used to track the position of the pet relative to the pet bowl for instance, it also allow further processing to be done, like infer the pet using further classification to distinguish between more than one cat or dog in the household.
An alternative was found, thou not ideal in terms of exploting the FPGA capabilities for video processing, it help to showcase the idea and possibilities of this project using the Kria AI Vitis platform.
AI model used.The model choosen was choosen so that it could be trained using our GPU Ampere architecture hardware (RTX3060), so basically limited to use Tensorflow 2.0. As mentioned before neither Caffe nor Tensorfow 1.x were appropiate for this hardware Ampere architecture as it require an older version of Cuda not compatible with those frameworks as realized during trails and reported here and here.
Fortunately not all was lost and Xilinx offers TensorFlow 2.0 examples, thou not that available variaty those other frameworks, a dogs vs cats model was identified adn used, it is located under XIlinx github Vitis-AI-Tutorials. The git page of the model linked above describe in detail all the steps needed to train the model so I will address the model deployment steps and caveats for the demo.
A log of the train process is captured here.
In order to compile the model for the Kria board you need to add the arch to the compile.sh file, basically adding this lines to the file (linked before as gist)
elif [ $1 = kv260 ]; then
ARCH=/opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.json
TARGET=kv260
echo "-----------------------------------------"
echo "COMPILING MODEL FOR KV260.."
echo "-----------------------------------------"Then change the run_all.sh file compile and target generation by commenting and adding the respective lines as below (file linked as gist as well)
source compile.sh kv260
python -u target.py -m ${BUILD}/compiled_kv260/customcnn.xmodel -t ${BUILD}/target_kv260 2>&1 | tee ${LOG}/target_kv260.logComplete the model test by following the Xilinx git guide, but in this case transfer the folder target_kv260 to your ubuntu OS home folder. I am getting ahead but you can also use Petalinux (see next section).
After testing the model demo code it was shown high accuracy on the image folder provided (I have to change directory for other reasons)
ubuntu@kria:~/target_kv260$ python3 app_mt.py -d test_img
Command line options:
--image_dir : test_img
--threads : 1
--model : customcnn.xmodel
------------------------------------
Pre-processing 1002 images...
Starting 1 threads...
------------------------------------
Throughput=267.60 fps, total frames = 1002, time=3.7444 seconds
Post-processing 1002 images..
Correct:966, Wrong:36, Accuracy:0.9641
------------------------------------A possible problem you might encounter while deploying the model is a DPU mismatch, for instance you might get the following console output on Petalinux
xilinx-k26-starterkit-2021_1:~/target_kv260$ python3 app_mt.py
Command line options:
--image_dir : images
--threads : 1
--model : customcnn.xmodel
------------------------------------
Pre-processing 1000 images...
Starting 1 threads...
WARNING: Logging before InitGoogleLogging() is written to STDERR
W0312 22:40:32.574353 1259 dpu_runner_base_imp.cpp:689] CHECK fingerprint fail ! model_fingerprint 0x1000020f6014407 dpu_fingerprint 0x1000020f6014406
F0312 22:40:32.574441 1259 dpu_runner_base_imp.cpp:661] fingerprint check failure.
*** Check failure stack trace: ***
AbortedThe problem requires you to know which DPU version you are running, in Petalinux you can do
xilinx-k26-starterkit-2021_1:~/target_kv260$ show_dpu
device_core_id=0 device= 0 core = 0 fingerprint = 0x1000020f6014406 batch = 1 full_cu_name=DPUCZDX8G:DPUCZDX8G_1Now for ubuntu image I am not sure how to query the DPU but I know the current image used the B3136 DPU.
I think the number 0x1000020f6014406 indicates the B3136 and the number 0x1000020f6014407 indicates the B4046, so basically in the example above our model was compiled with the last one.
Go to the Vitis-AI conda environment and change the arch.json file to contain
{
"target": "DPUCZDX8G_ISA0_B3136_MAX_BG2"
}you can do it with nano editor since that file resides inside the conda environment, i.e.,
sudo nano /opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.jsonYou don't need to execute the run_all.sh again, just compile, so you can use the command line (below the output)
(vitis-ai-tensorflow2) Vitis-AI /workspace/08-tf2_flow/files > source compile.sh kv260
-----------------------------------------
COMPILING MODEL FOR KV260..
-----------------------------------------
[INFO] Namespace(batchsize=1, inputs_shape=None, layout='NHWC', model_files=['build/quant_model/q_model.h5'], model_type='tensorflow2', named_inputs_shape=None, out_filename='/tmp/customcnn_org.xmodel', proto=None)
[INFO] tensorflow2 model: /workspace/08-tf2_flow/files/build/quant_model/q_model.h5
[INFO] keras version: 2.6.0
[INFO] Tensorflow Keras model type: functional
[INFO] parse raw model :100%|██████████| 71/71 [00:00<00:00, 33015.03it/s]
[INFO] infer shape (NHWC) :100%|██████████| 108/108 [00:00<00:00, 6686.72it/s]
[INFO] perform level-0 opt :100%|██████████| 2/2 [00:00<00:00, 205.98it/s]
[INFO] perform level-1 opt :100%|██████████| 2/2 [00:00<00:00, 811.43it/s]
[INFO] generate xmodel :100%|██████████| 108/108 [00:00<00:00, 6596.64it/s]
[INFO] dump xmodel: /tmp/customcnn_org.xmodel
[UNILOG][INFO] Compile mode: dpu
[UNILOG][INFO] Debug mode: function
[UNILOG][INFO] Target architecture: DPUCZDX8G_ISA0_B3136_MAX_BG2
[UNILOG][INFO] Graph name: model, with op num: 232
[UNILOG][INFO] Begin to compile...
[UNILOG][INFO] Total device subgraph number 3, DPU subgraph number 1
[UNILOG][INFO] Compile done.
[UNILOG][INFO] The meta json is saved to "/workspace/08-tf2_flow/files/build/compiled_kv260/meta.json"
[UNILOG][INFO] The compiled xmodel is saved to "/workspace/08-tf2_flow/files/build/compiled_kv260/customcnn.xmodel"
[UNILOG][INFO] The compiled xmodel's md5sum is 3708088fe0abf27b4335c421adce724d, and has been saved to "/workspace/08-tf2_flow/files/build/compiled_kv260/md5sum.txt"
**************************************************
* VITIS_AI Compilation - Xilinx Inc.
**************************************************
-----------------------------------------
MODEL COMPILED
-----------------------------------------The next step is to generate the target folder with model, follow below command and see output result.
(vitis-ai-tensorflow2) Vitis-AI /workspace/08-tf2_flow/files > python -u target.py -m ${BUILD}/compiled_kv260/customcnn.xmodel -t ${BUILD}/target_kv260 2>&1 | tee ${LOG}/target_kv260.log
------------------------------------
3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 06:08:53)
[GCC 9.4.0]
------------------------------------
Command line options:
--target_dir : ./build/target_kv260
--image_dir : build/dataset/test
--input_height : 200
--input_width : 250
--num_images : 1000
--app_dir : application
--model : ./build/compiled_kv260/customcnn.xmodel
------------------------------------
Resizing and copying 1000 images...
100%|██████████| 1000/1000 [00:11<00:00, 84.49it/s]
Copying application code from application ...package
Copying compiled model from ./build/compiled_kv260/customcnn.xmodel ...You should get a new build/target_kv260 folder under it. Just a hint for later, if you edit files in that folder make sure to make a back up, it seems the compile command whipes out the whole directory and create it again.
An odd issue you might also get with DPU, specially with the ubuntu OS image is due to the fact that the image does not contain any DPU by default. The issue and how to solve is explained in next secction.
The AI model works well for images of dogs or cats but with images not containing any dog or cats does not work as shown here because the model was trained on only those two, the DNN have only two outputs.
For time constraints changing the model was not possible, so a quick dirty fix was to analyze the weights of the output and make a threshold that accept the output. But before jumping into that topic, let's do some test on captured images of my cats at home and see how it goes.
I have modified the application to test the model to run the test on my own pictures and save those in a res folder under the target_kv260 which should contain two folders names correct and wrong, the images are saved under images folder in mycats folder and the command to run is
python3 app_mt_mod.py -d images/mycats2I am printing the weights on the console output, here is partially some of the outputs (complete here).
ubuntu@kria:~/target_kv260$ python3 app_mt_mod.py -d images/mycats2
Command line options:
--image_dir : images/mycats2
--threads : 1
--model : customcnn.xmodel
------------------------------------
Pre-processing 51 images...
Starting 1 threads...
(1, 200, 250, 3)
(1, 2)
51
[ 2 -2]
[ 11 -11]
[-7 7]
[ 12 -12]
[0 0]
[-13 13]
[ 5 -5]
[-6 6]
[ 16 -16]
[ 4 -4]
[-13 13]
[-9 9]
...
...
classification as cat
wrong image: 112915.jpg
has threshold: 8
(0, 8)
classification as cat
wrong image: 112078.jpg
has threshold: 8
correct image: 112490.jpg
correct image: 112146.jpg
correct image: 112605.jpg
correct image: 112219.jpg
correct image: 112734.jpg
correct image: 112032.jpg
(0, 6)
classification as cat
wrong image: 112426.jpg
has threshold: 6
Correct:26, Wrong:25, Accuracy:0.5098
------------------------------------The first part of the above console output prints the numpy arrays of 2 elelments that correspond to the outputs of dogs and cats, the argmax function is used to get the position of the maximun value, position 0 will indicate a dog animal prediction and 1 will indicate cat animal prediction. Since we are also interested in the value, a tupple containing the position and value is saved to the global list out_q.
out_q[write_index] = (pos, value)For this test I found that accuracy was not that good, all the pictures are from only cats with just a few that might be not good. One possibility is to add those images to the training set and train again.
The script below is on this gist.
The images were capture on my Tapo C100 camera using the following openCV snippet, which resizes the images to 250x200 pixels so they can be used.
import cv2
import random
cap = cv2.VideoCapture("rtsp://adminlogin:password@192.168.1.16/stream1")
width = int(cap.get(3)) # float `width`
height = int(cap.get(4)) # float `height`
num = random.randint(112000, 112999)
print("width: ", width)
print("height: ", height)
ret, frame = cap.read()
if cap.isOpened():
_, frame = cap.read()
cap.release() # releasing camera immediately after capturing picture
if _ and frame is not None:
# feeder = frame[200:height, 300:width - 100]
# cv2.imwrite('images/latest.jpg', feeder)
image = cv2.resize(frame, (250, 200), interpolation=cv2.INTER_CUBIC) # Resize image
cv2.imwrite('images/cat.'+str(num)+'.jpg', image)A small app to take pictures
import cv2
import random
cap = cv2.VideoCapture("rtsp://tapoadmin:160816@192.168.1.16/stream1")
width = int(cap.get(3)) # float `width`
height = int(cap.get(4)) # float `height`
num = random.randint(112000, 112999)
print("width: ", width)
print("height: ", height)
ret, frame = cap.read()
if cap.isOpened():
_, frame = cap.read()
cap.release() # releasing camera immediately after capturing picture
if _ and frame is not None:
# feeder = frame[200:height, 300:width - 100]
# cv2.imwrite('images/latest.jpg', feeder)
image = cv2.resize(frame, (250, 200), interpolation=cv2.INTER_CUBIC) # Resize image
cv2.imwrite('images/cat.'+str(num)+'.jpg', image)And some of the pictures
The AI model trained in the previous step can be used in Petalinux or Ubuntu image. Both were tried but Ubuntu was finally used as we were interested in getting images from a WiFi camera. The Petalinux image was tried with a USB camera and works similar. The problem with the Petalinux image was to make the openCV framework capture the RTSP stream from the WiFi camera, possible related to some GStream package not well configured.
To install Ubuntu first download it from XIlinx website and transfer to an SD card following the steps in the getting started guide.
After installing ubuntu, in order to make the openCv works you have to install it, you can use
sudo apt update
sudo apt upgrade
sudo apt install python3-opencvVerify it is install by opening a terminal and typing the below command (below the output on my system)
ubuntu@kria:~$ python3 -c "import cv2; print(cv2.__version__)"
4.2.0Going back to the DPU issue mention before, the issue with ubuntu you might encounter looks like this
python3 app_mt.py
Command line options:
--image_dir : images
--threads : 1
--model : customcnn.xmodel
WARNING: Logging before InitGoogleLogging() is written to STDERR
F0312 14:05:43.736797 1057 dpu_controller.cpp:44] Check failed: !the_factory_methods.empty()
*** Check failure stack trace: ***
AbortedYou need to install a DPU, at the moment only thing you can do is install the xlnx-nlp-smartvision as shown below.
sudo snap install xlnx-config --classic
sudo xlnx-config --snap --install xlnx-nlp-smartvisionthat should install it, now loaded it by doing
sudo xlnx-config --xmutil loadapp nlp-smartvisionand verify by doing
ubuntu@kria:~/target_kv260$ sudo xlnx-config --xmutil listapps
[sudo] password for ubuntu:
Accelerator Base Type #slots Active_slot
nlp-smartvision nlp-smartvision XRT_FLAT 0 0,The original code that read image files from the images directory was modified to process images from a WiFI camera stream using RTSP protocol. This is accomplished by using openCV under python.
The code works by creating a single thread that runs until stopped when the user hits the letter q on the video window. The captured frames are resized to images of 250 by 200 pixels before been displayed by doing
image = cv2.resize(frame, (250, 200), interpolation=cv2.INTER_CUBIC) # Resize image
cv2.imshow('output', image)The result of the inference (tuple of pos and value) as shown before is sent to the calling thread using a queue.
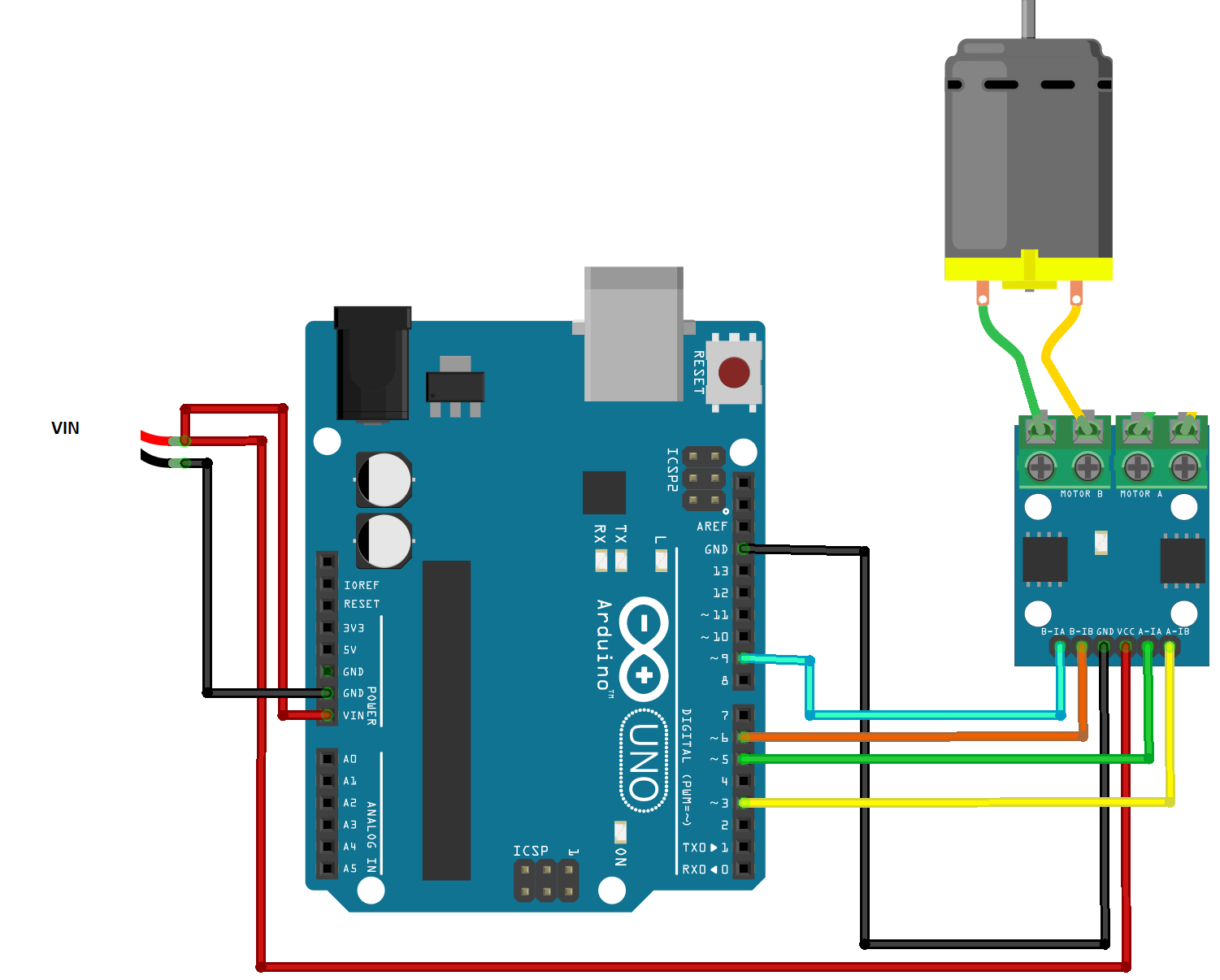
q.put_nowait((pos,value))The pet feeder is a cool hack on a commercial pet feeder. All you need is a few parts and access to a 3D printer. An N20 motor was used to rotate the plate. A simple hook up board of L9110 motor driver was used. The motor is controlled using PWM to produce a smooth movement.
An arduino WiFi is used for simplicity of connectivity with the Kria board, handy as well because my cats are not having the feeder in my home office. The commands to move the food containers on the feeder are simple, move plate to next position or previous position using a letter such as n (for next) or p (previous). The code has also commands to allow testing like move right, left and stop. All command should be terminated by carriedge return character.
This is done by using dc motor with an encoder and counting pulses, it will probably need some way to calibrate its position as the number of pulses drift over time but it's fair enough for demo time. For simplicity the communication is done using UDP protocol. The code is available here.
The code for the dogs vs cats seen before was modified to do a simple demo that once the pet is detected it sends a command to the PetFeeder via UDP to open the feeder for the animal to eat. The code is neglating false positives and applying a threshold to allow the background image to not trigger a detection - as it was seen before any image will be detected as a dog :(
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
classes = ['dog','cat']
feederpos = False
feedTimer = time.time()
while True:
try:
res = q.get(timeout=2) # 3s timeout
except queue.Empty:
print("Image feed ended")
break
except KeyboardInterrupt:
break
q.task_done()
prediction = classes[res[0]]
threshold = res[1]
if threshold <= 15:
# print("not a dog or a cat, th=%d" % threshold)
continue
else:
print("classification as %s" % prediction)
print("has threshold: %s" % repr(threshold))
if prediction == "dog":
continue
if feederpos == False:
feed_my_pet(sock, True)
feederpos = True
feedTimer = time.time()
else:
feedTimer = time.time() # reinitialize the feeder timer
if feederpos == True:
if time.time()-feedTimer >= 120.0:
feederpos = False
feed_my_pet(sock, False)The function feed_my_pet simple send the UDP message
def feed_my_pet(sock, state):
if state is True:
print("Smart feeder is open for pets")
sock.sendto(bytes(FEEDMSG_open, "utf-8"), (UDP_IP, UDP_PORT))
else:
print("Smart feeder is close for pets")
sock.sendto(bytes(FEEDMSG_open, "utf-8"), (UDP_IP, UDP_PORT))The code is available here.
The code was tested with my cats as shown in the following video. Once the cat is detected, the food plate spins to become available, a timer is restarted if the pet is detected again. Below is a video of the console and openCV window during the demo.
There is an ugly error produced by decoding layer of h.264, as far as I know it is related to decoding process and not really affecting the application, perhaps some frames are dropped. The error is something similar to the following
ubuntu@kria:~/target_kv260$ python3 app_mt_mod_rtsp_v2.py
width: 1920
height: 1080
Command line options:
--model : customcnn.xmodel
loop to get values
[h264 @ 0x224266c0] error while decoding MB 17 44, bytestream -5
[h264 @ 0x2246cba0] error while decoding MB 103 26, bytestream -5
[h264 @ 0x223fd060] error while decoding MB 58 39, bytestream -5
[h264 @ 0x2246cba0] error while decoding MB 23 26, bytestream -5And can be appreciated it is present while the demo code runs as in below video.
And the same video captured using the TAPO camera app.
Conclusions.This project highlights the potential of this technology for the home market. The Kria KV260 SOM is able to handle concurrent different video streams as Xilinx demo shows, so this application can be one of many running simultaneosly for a home user, this way the cost of the pet feeder will not take into account the full SOM module, so it is viable and sustainable to think of a future in which normal users can have this at home like todays WiFi routers and smartphones.
The project example illustrate the idea but the requirements for a product in the market will require refinement of the AI model. Other requirements will put the Vitis AI to the test such as make the AI engine detect a specific pet in the household and provide a different food, this is convinient when having senior pets with younger fellows, both requireing different nutrition. It also can be used to control the amount of food a given animal have ingested during the day. All this ideas can become real with AMD-XIlinx Vitis -AI technology running on low cost hardware like the Kria KV260.
{kind=link}

Comments
Please log in or sign up to comment.