
Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
Have you ever needed to create a ransom note, but you just didn't have the time?
Ransom notes are an age old media. Not just for criminals, they're also perfect for when you need to leave a passive aggressive note in your neighbor's mailbox, or for your roommate who keeps stealing your food in the communal fridge.
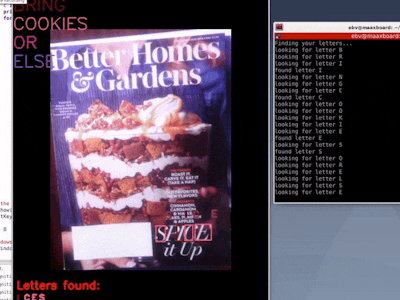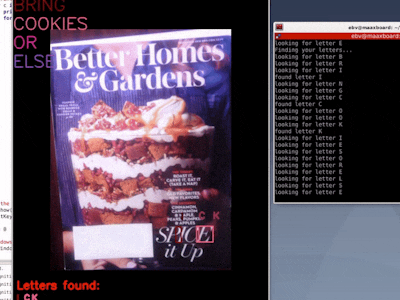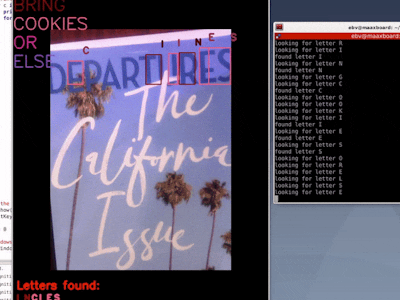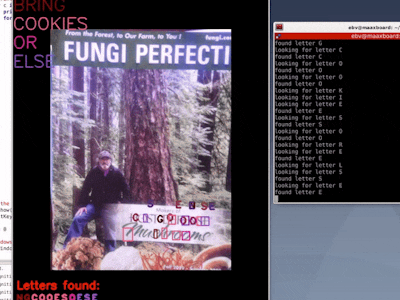
Unfortunately, it's time consuming to search for each letter on a page full of text...until now!
Finally you can create all the ransom notes you need, because MaaXBoard running pyTessearact and East quickly finds the letters for you! Busy dads and harried businesswomen will be ransoming in no time!
PREREQUISITESSee my previous tutorials to do the following:
1. Get MaaXBoard setup in headless mode (about an hour)
2. Install OpenCV (about 2 hours).
ASSEMBLE THE CAMERA AND SCREENIf you have the MIPI-CSI Camera, plug it into the board, blue side facing the board's ethernet port.
If you're using the MIPI-CSI display, plug the cable into the board, blue side facing the edge of the board.
Other than that, you're basically done with the assembly. You just need to elevate the board so that the camera can see a full page of text. I just set mine an old shoebox.
GET THE MIPI-DISPLAY TO WORK (optional)By default, the MaaXBoard is configured for HDMI, so you'll have to to edit uEnv.txt to get the display to work. Login via remote desktop or ssh using the "root" login (default password is "avnet").
Edit uEnv.txt using geany:
geany /boot/uEnv.txtComment out the first line if it's uncommented:
# fdt_file=em-sbc-imx8m.dtb
Uncomment the third line:
fdt_file=em-sbc-imx8m-dcss-dsi.dtb
MaaXBoard's linux version doesn't allow non-root users to access serial devices, like MIPI-CSI or USB cameras. You'll have to grant your user permissions.
Run:
ls -l /dev/video*This will tell you the ownership and the permissions. You should now be able to run sudo chmod for any cameras you have to grant permission to non-root users:
sudo chmod -R a+rwx /dev/video1
sudo chmod -R a+rwx /dev/video0Note: This change will only take be in effect until the MaaXBoard reboots. To create a more permanent change, while you're still logged in as root, edit /etc/rc.local file to include this line just before "exit 0":
sudo chmod -R a+rwx /dev/video0
Once you're finished, run:
sync
rebootLogin to your MaaXBoard as the ebv user that you created in the OpenCV tutorial. Copy the zipped folder with the code and images from your host computer. Don't forget the colon at the end:
scp ransomnote.zip ebv@[IP ADDRESS]:Enter the password ("ebv" if you setup your user according to the tutorial) when prompted.
Or use wget or curl (may need to install):
wget https://hacksterio.s3.amazonaws.com/uploads/attachments/1130505/ransomnote.zipConnect as your "ebv" user via remote desktop and open Terminator, the terminal client for XFCE4.
Unzip the files that we just copied.
unzip ransomnote.zipWe'll be using the Tesseract library for Optical Character Recognition (OCR). OCR is the conversion of typed, handwritten, or printed text into machine-encoded text. Tesseract is free and open source, and it's very configurable.
Install Tesseract:
sudo apt install tesseract-ocrVerify your Tesseract version:
tesseract -vTo use Tesseract with Python, we need to install pytesseract. We'll install a couple other modules that we'll need while we're at it. Make sure you're on the virtual environment you set up that has OpenCV installed before installing:
workon cv
pip install pytesseract
pip install argparse
pip install pillow
pip install imutilsTest Tesseract on one of the test images:
cd ransomnote
tesseract test1.jpg stdoutYou'll see an output of words that recognized Tesseract recognized:
Run the program on your cv virtual environment:
python ransomnote.pyThis should start your board's webcam. It will continue to take pictures until you press ctrl-c to stop it.
Optical character recognition has been around since 1959. The first application was a banking application developed by Intelligent Machine Corporation that could only read one font in one size. Despite its age, the problem of optical character recognition still not "solved." According to this article,
Deep learning models find it much more difficult to recognize digits and letters than to recognize much more challenging and elaborate objects such as dogs, cats or humans.
Recognizing text from a newspaper or magazine is extra difficult because of the highly complex layout, variable font sizes and font types, narrow space between lines, narrow gutters between columns, poor quality ink and paper, and missing text (probably due to previous letters being cut out for ransom notes).
East (Efficient accurate scene text detector)This script uses East to find the regions of the image where text is. It's more accurate than YOLO or other single shot or region based detectors, but it's less computationally intensive than a sliding window text detector. Another benefit of East is that it's available in OpenCV 4.
However, it only finds regions where text is likely to be - it doesn't actually recognize the text, which is why we need Tesseract.
TesseractTesseract was originally developed by HP between 1985 and 1994. It was open-sourced in 2005. Tesseract is good at recognizing text once it knows where it is. However, I found that it has trouble finding text regions on its own, which is why it needs to be used in conjunction with East.
Tesseract v4 uses an LSTM-based engine to recognize words and letters. An LSTM is a type of RNN (recurrent neural network). Basically, recurrent neural networks have loops that allow context from part of an image to be associated with context from the rest of the image. This makes this type of neural network good for text recognition because text-recognition involves a lot of context. For instance, characters like "l", "I" and "1" can look exactly alike, depending on the font. We need context about what word they appear in in order to parse them out.
Similarly, we need context about what words appeared previously in a sentence in order to guess the word that comes....(you guessed it)
... next!
This is also why you have to select a language as part of the config settings.
Tesseract ConfigI encourage you to play with the config to see if you can get better results than I did.
- One setting you can play with is Language
(-l). Tesseract has been trained on many languages, from Amharic to Yiddish. - Engine Mode (
--oem). Tesseract has several engine modes with different performance and speed. In order to run legacy mode you'll have to download the trained data for whichever language you've chosen.
- Page Segmentation Mode (
--psm). That affects how Tesseract splits image in lines of text and words. I found that 11 and 12 worked best for magazines.
I recommend the following tutorials if you want to dive deeper into text recognition:
And last but not least, the fantastic tutorials on PyImagSearch.com




Comments