



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
| ||||||
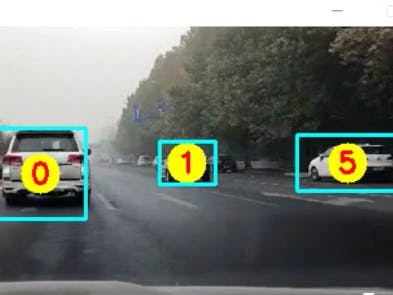
With the increasing number of cars, trucks and motors on roads, the problem of traffic jams is growing fast, especially at road intersections. If the cars and people on roads can be tracked and counted, the intellectual traffic control system can be realized and adjust the traffic flow in all directions automatically to mitigate traffic bottlenecks. We developed a vehicle identifying and counting AI system using FPGA low latency and parallel computing capability on kv260.
https://www.bilibili.com/video/BV1DY4y1i7fW/
If you can not open the video below, pls double click the link above.
https://www.bilibili.com/video/BV1XL411w7Sd/
If you can not open the video below, pls double click the link above.
Step One: Training yolov4-tiny modelChange yolov4-tiny model
For the yolov4-tiny model, there is a slice operation to realize the CSPnet, but the quantitative tools may not support the operation, so use a 1*1 convolution to replace it.
Training the yolov4-tiny model
Train the model, and save the model structure and weights as model.json and model.h5 using TensorFlow-gpu 2.2.0.
Step Two: Convert and frozen the modelConvert model.h5 to pb model and frozen the pb model using vitis ai tool.
Quantize the frozen model using vitis ai tool.
(vitis-ai-tensorflow) Vitis-AI /workspace/Yolov4-tiny > ./2_vitisAI_tf_quantize.sh
#!/bin/bash
# run quantization
vai_q_tensorflow quantize \
--input_frozen_graph ./frozon_result/model.pb \
--output_dir quantize_result \
--input_nodes input_1 \
--input_shapes ?,320,320,3 \
--output_nodes conv2d_20/BiasAdd,conv2d_23/BiasAdd \
--method 1 \
--input_fn input_fn.calib_input \
--calib_iter 100 \
echo "#####################################"
echo "QUANTIZATION COMPLETED"
echo "#####################################"#!/bin/bash
# Compile
#vai_c_tensorflow --arch /workspace/ministNumber/dnndk/dnndk/dpu.json -f quantize_results/deploy_model.pb --output_dir compile_result -n yolo_car
#vai_c_tensorflow --frozen_pb yolov2tiny/quantize/quantize_eval_model.pb -a arch.json -o yolov4tiny -n yolo_car
vai_c_tensorflow -f ./quantize_result/quantize_eval_model.pb -e "{'input_shape':'1,320,320,3'}" -a ../arch.json --output_dir compile_result -n yolo_car
echo "#####################################"
echo "COMPILATION COMPLETED"
echo "#####################################"prepare anchors file
Setting score_thresh = 0.2, ovr_limit = 0.55, not good
These parameters seem good.
xilinx-k26-starterkit-2021_1:~$ gst-launch-1.0 filesrc location=./video/cross.h264 ! h264parse ! video/x-h264, alignment=au ! omxh264dec low-latency=0 internal-entropy-buffers=2 ! video/x-raw, format=NV12, framerate=30/1 ! tee name=t ! queue ! ivas_xmultisrc kconfig="/home/petalinux/notebooks/yolov4tiny/preprocess.json" ! queue ! ivas_xfilter kernels-config="/home/petalinux/notebooks/yolov4tiny/aiinference.json" ! ima.sink_master ivas_xmetaaffixer name=ima ima.src_master ! fakesink t. ! queue ! ima.sink_slave_0 ima.src_slave_0 ! queue ! ivas_xfilter kernels-config="/home/petalinux/notebooks/yolov4tiny/drawresult.json" ! queue ! kmssink driver-name=xlnx plane-id=39 sync=false fullscreen-overlay=true'''Model post-processing'''
def eval(yolo_outputs, image_shape, max_boxes = 20):
global score_thresh
#score_thresh = 0.4
class_names = get_class(classes_path)
anchors = get_anchors(anchors_path)
# anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
anchor_mask = [[3, 4, 5], [0, 1, 2]]
# anchor_mask = [[0, 1, 2, 3, 4]]
boxes = []
box_scores = []
input_shape = np.shape(yolo_outputs[0])[1 : 3]
#print(input_shape)
input_shape = np.array(input_shape)*32
#print(input_shape)
#print(f"len(yolo_outputs)={len(yolo_outputs)}")
for i in range(len(yolo_outputs)):
_boxes, _box_scores = boxes_and_scores(yolo_outputs[i], anchors[anchor_mask[i]], len(class_names), input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
boxes = np.concatenate(boxes, axis = 0)
box_scores = np.concatenate(box_scores, axis = 0)
mask = box_scores >= score_thresh
boxes_ = []
scores_ = []
classes_ = []
for c in range(len(class_names)):
class_boxes_np = boxes[mask[:, c]]
class_box_scores_np = box_scores[:, c]
class_box_scores_np = class_box_scores_np[mask[:, c]]
nms_index_np = nms_boxes(class_boxes_np, class_box_scores_np)
class_boxes_np = class_boxes_np[nms_index_np]
class_box_scores_np = class_box_scores_np[nms_index_np]
classes_np = np.ones_like(class_box_scores_np, dtype = np.int32) * c
boxes_.append(class_boxes_np)
scores_.append(class_box_scores_np)
classes_.append(classes_np)
boxes_ = np.concatenate(boxes_, axis = 0)
scores_ = np.concatenate(scores_, axis = 0)
classes_ = np.concatenate(classes_, axis = 0)
return boxes_, scores_, classes_
count = 0
center_points_prev = []
track_objects = {}
temp_objects = {}
track_id = 0
miss_objects = {}
def draw_track(image, bboxes, classes):
"""
bboxes: [x_min, y_min, x_max, y_max, probability, cls_id] format coordinates.
"""
# coor = np.array(bbox[:4], dtype=np.int32)
# fontScale = 0.5
# score = bbox[4]
# for i, bbox in enumerate(bboxes):
# coor = np.array(bbox[:4], dtype=np.int32)
# fontScale = 0.5
# score = bbox[4]
# class_ind = int(bbox[5])
# if class_ind == 5: # only show cars
# print(f"class_ind = {class_ind}")
# bbox_color = colors[class_ind]
# bbox_thick = int(0.6 * (image_h + image_w) / 600)
# c1, c2 = (coor[0], coor[1]), (coor[2], coor[3])
# cv2.rectangle(image, c1, c2, bbox_color, bbox_thick)
center_points_current = []
global count
global center_points_prev
global track_objects
global track_id
for i, bbox in enumerate(bboxes):
class_ind = int(bbox[5])
if class_ind == 6: # only show cars
#coor = np.array(bbox[:4], dtype=np.int32)
#print(f"coor = {coor}")
(x1, y1, x2, y2) = bbox[:4]
#print(f"t(x1, y1, x2, y2) = {x1, y1, x2, y2}")
(x, y, w, h) = (x1, y1, x2-x1, y2-y1)
cx, cy = int((x+x+w)/2), int((y+y+h)/2)
center_points_current.append((cx,cy))
#cv2.rectangle(img, (x,y), (x+w,y+h), (255,255,0), 2)
cv2.rectangle(img, (x1,y1), (x2,y2), (255,255,0), 2)
#print(f"center_points_current = {len(center_points_current)}")
#print(f"t(x1, y1, x2, y2) = {x1, y1, x2, y2}")
print(f"count = {count}")
if count <= 2:
# define all track id for the second frame
print(f"count1 = {count}")
print(f"center_points_current = {center_points_current}")
print(f"center_points_prev = {center_points_prev}")
for pt1 in center_points_current:
print(f"pt1 = {pt1}")
for pt2 in center_points_prev:
print(f"pt2 = {pt2}")
distance = math.hypot(pt2[0]-pt1[0], pt2[1]-pt1[1])
print(f"distance ={distance}")
if distance < 20:
track_objects[track_id] = pt1
print(f"track_id = {track_id}")
print(f"track_objects = {track_objects}")
track_id += 1
else:
#print(f"track_objects = {track_objects}")
temp_objects = {}
for k in sorted(track_objects): # sort according key
temp_objects[k] = track_objects[k]
#print(f"temp_objects = {temp_objects}")
#track_objects_new = track_objects.copy()
track_objects_new = temp_objects.copy()
for object_id, pt2 in track_objects_new.items():
object_exist = False
for pt1 in center_points_current:
distance = math.hypot(pt2[0]-pt1[0], pt2[1]-pt1[1])
if distance < 40: # orignal 20 change to 40
print(f"pt1 = {pt1}")
track_objects[object_id] = pt1 # inherit track id
object_exist = True
center_points_current.remove(pt1)
continue
if object_exist == False:
track_objects.pop(object_id)
miss_objects[object_id] = pt2 # all missing objects record
#print(f"miss_objects = {miss_objects}")
# add new object id and still use original id d < 40
print(f"track_id = {track_id}")
for object_id, pt2 in miss_objects.items():
object_exist = False
for pt1 in center_points_current:
distance = math.hypot(pt2[0]-pt1[0], pt2[1]-pt1[1])
if distance < 40: # orignal 20 change to 40
#print(f"pt1 = {pt1}")
track_objects[object_id] = pt1 # inherit track id after missing objects a while
object_exist = True
center_points_current.remove(pt1)
continue
else:
track_objects[track_id] = pt1
#print(f"track_id = {track_id}")
track_id += 1
# for pt in center_points_current: # available points after removing
# track_objects[track_id] = pt
# print(f"track_id = {track_id}")
# track_id += 1
for object_id, pt in track_objects.items():
# print(f"object_id = {object_id}")
# add circle for tracking objects
cv2.circle(img, pt, 15, (0,255,255), -1)
# show id
cv2.putText(img, str(object_id), (pt[0]-7, pt[1]+7), 0, 0.7, (0,0,255),2)
center_points_prev = center_points_current.copy()
return image

Comments
Please log in or sign up to comment.