AI Takes Flight
Using deep reinforcement learning and an actor-critic training scheme, autonomous drones have been taught to fly in as little as 18 seconds.


Autonomous aerial vehicles (AAVs) have really taken off (no pun intended) in recent years, reshaping industries ranging from logistics to agriculture and beyond. Capable of navigating and performing tasks without direct human intervention, swarms of AAVs are already being used to efficiently deliver packages and autonomously inspect infrastructure, like bridges and wind turbines, for damage. Precision agriculture, environmental monitoring, search and rescue operations, and disaster relief efforts have similarly benefited from the latest advances in AAVs.
But to fully realize the potential of this technology, further work will be needed. As it presently stands, controlling a typical AAV requires the precise coordination between multiple Proportional-Integral-Derivative (PID) controllers, each dedicated to a specific aspect of flight like position, velocity, attitude, and angular rate. These controllers constantly analyze sensor data and adjust motor commands, ensuring the AAV navigates precisely and smoothly.
Yet, designing these control systems is no easy feat. Each AAV platform, with its unique design and capabilities, requires finely-tuned control algorithms of its own. Additionally, external factors like wind gusts or turbulence introduce unpredictable disturbances that the system must adapt to in real-time.
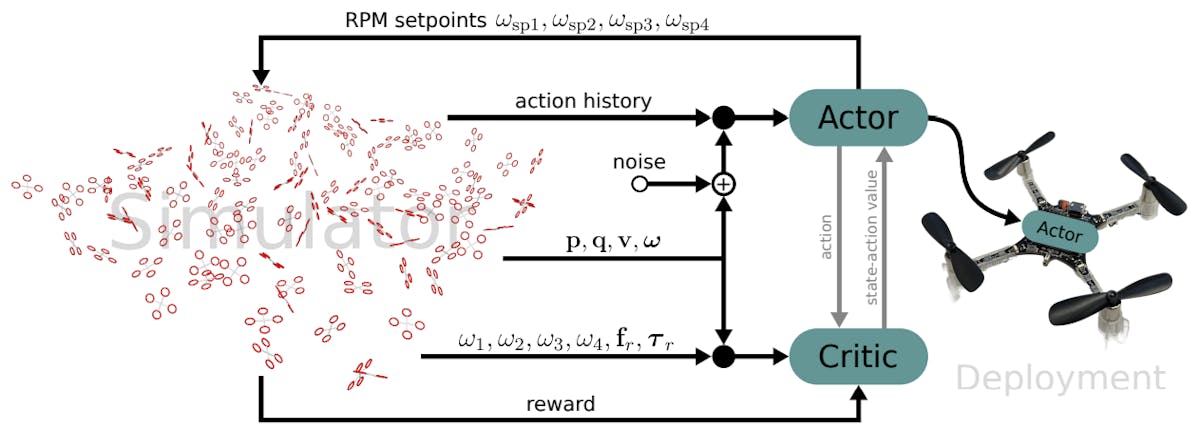
To simplify the control of these vehicles and provide a more generalized solution, many researchers have explored the possibility of leveraging deep reinforcement learning. While this approach has a lot of potential, the successes that have been achieved in computer simulations have not proven to be transferable to real-world scenarios. Factors like model inaccuracies, noise, and other disturbances contribute to these discrepancies, and there is no clear path forward to solve these problems.
A trio of engineers at New York University has recently put forth a potential solution that could allow future AAVs to be reliably controlled by reinforcement learning algorithms. The approach utilizes a neural network that was trained to translate sensor measurements directly into a motor control policy. Impressively, the novel system devised by the team was shown to be capable of producing accurate control plans after being trained for just 18 seconds on a consumer-grade laptop. Moreover, real-time execution of the trained algorithm was achieved on a low-power microcontroller.
To train the reinforcement learning agent, the team designed an actor-critic scheme. Using this technique, the actor is responsible for selecting actions based on the current state of the environment, while the critic evaluates these actions and provides feedback on their quality. Through this iterative process, the actor learns to improve its decision-making process. This approach allows for more efficient and effective training compared to other reinforcement learning methods.
For simplicity, the model was trained in a simulated environment. But to help overcome some issues previously seen in translating simulation results to real-world results, the researchers took a few additional steps. For starters, noise was injected into the sensor measurements to account for imperfections that occur in real-world measurements. Curriculum Learning was also leveraged to help the algorithm learn to handle more complex scenarios over time, with greater generalization and less risk of hitting plateaus in learning. Furthermore, the actor-critic architecture was provided with additional information, like actual motor speeds, that is not readily available in the real-world, but helps to improve the accuracy of the model.

After training with simulated data, the model was deployed to the microcontroller onboard a physical Crazyflie Nano Quadcopter. It was shown that the reinforcement learning-based algorithm could effectively and efficiently provide a stable flight plan, proving the system’s utility in the real-world.
The full source code of the project has been made available to assist other research teams in further advancing the state of the art in AAV technology.
R&D, creativity, and building the next big thing you never knew you wanted are my specialties.