Fire When Ready
This framework uses an event-driven AI algorithm and an FPGA for energy-efficient real-time processing in computer vision applications.


The capabilities of cutting-edge artificial intelligence (AI) algorithms are of little value if they cannot be deployed where they are needed. For applications that require real-time operation, deal with sensitive information, or that cannot guarantee the availability of an internet connection, computationally-intensive AI algorithms that run in cloud-based data centers are not able to meet their needs. Cases such as these must instead rely on edge computing technologies to run the algorithms directly on the target system’s hardware.
This, of course, leads to trade-offs — an algorithm that needs a data center filled with GPUs cannot simply be loaded onto a low-power computing device with limited memory. Algorithms must be trimmed down to size and otherwise optimized, all while attempting to maintain similar levels of performance. A great deal of success in these areas has been achieved as of late, but there is still work to do. The more that we can slice these algorithms down to size, the more advanced capabilities we can enable at the edge. Furthermore, the applications we do run will be more efficient, and consume less energy.
One promising avenue for the development of more efficient edge algorithms may involve the use of Spiking Neural Networks (SNNs). These neural networks are inspired by the human brain, and perform sparse processing that is event-driven. A trio of researchers at Johns Hopkins University recently reported on their work in which they paired a novel SNN architecture with specialized hardware to develop a system that can run even computationally-intensive computer vision algorithms at the edge.
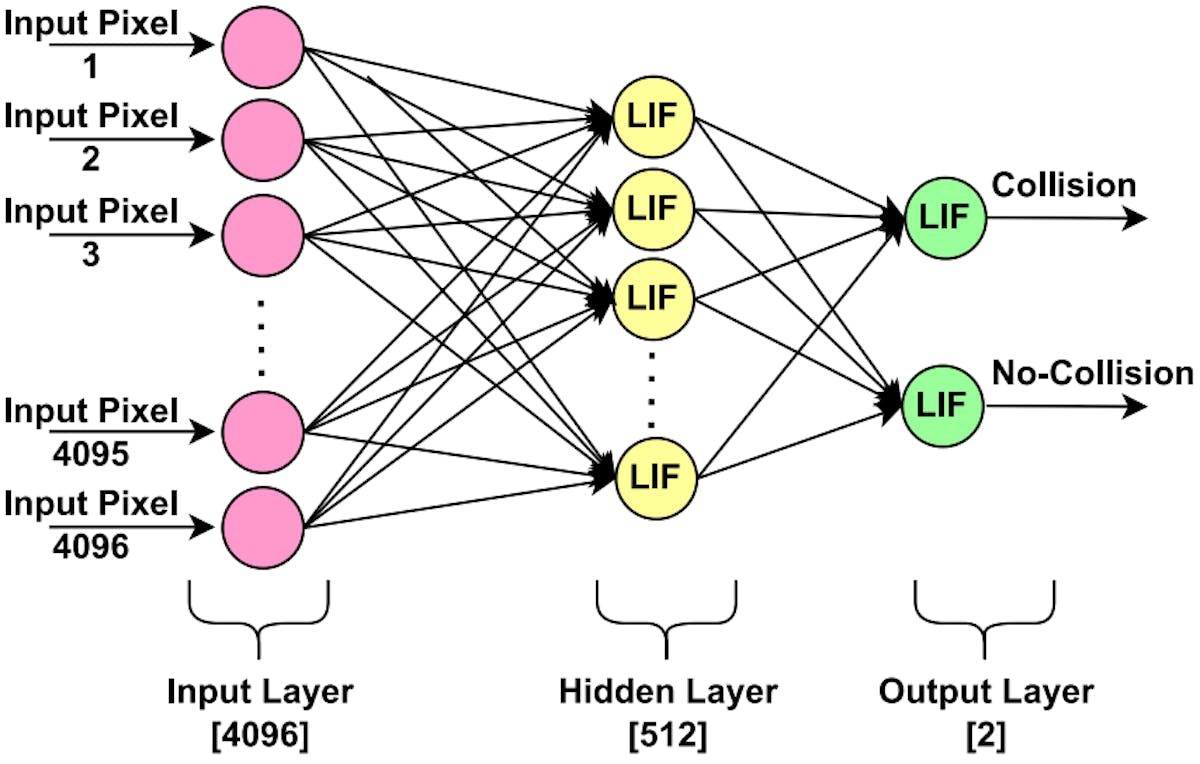
The architecture of the SNN is based on a first-order Leaky Integrate-and-Fire (LIF) model, which processes inputs as a series of spikes across multiple time steps. This spiking approach allows the network to interpret both spatial and temporal data, essential for tasks like collision detection in autonomous vehicles. The network is structured with three layers: an input layer that flattens images, a hidden layer of LIF neurons with adjustable thresholds and leak parameters, and an output layer that categorizes data into collision or non-collision classes. Additionally, the inclusion of a refractory period — a short phase during which neurons cannot fire immediately after spiking — improves the network’s biological realism and robustness, enabling it to mimic the nuanced firing patterns of actual neurons.
To implement this architecture on edge devices with limited power and processing capacity, the researchers opted for Field-Programmable Gate Arrays (FPGAs), after optimizing the SNN with binary input and output encoding. This encoding reduces memory usage, minimizes computational overhead, and supports rapid processing without complex Multiply-Accumulate operations. Instead, the SNN relies on a cascaded adder structure, which simplifies the computation needed for spike generation.
An experiment was conducted with this system to test the model’s efficiency in real-time collision detection tasks. The researchers first built and trained the SNN model on a dataset of around 32,000 images, each labeled to indicate collision or no-collision scenarios. Images were preprocessed into a 64x64 pixel grayscale format to reduce computational load before being fed into the network, which was trained on a GPU-accelerated machine using PyTorch. The model’s accuracy was tested across varying image resolutions, showing that the LIF neuron model achieved the highest testing accuracy (85%) on 64x64 images, though performance declined as image size increased.
The model was deployed to a Xilinx Artix-7 FPGA, and it was observed that real-time processing could be achieved while consuming just 495 mW of energy. This represents a meaningful step forward for low-power computer vision applications at the edge.
R&D, creativity, and building the next big thing you never knew you wanted are my specialties.