For Better TinyML, Just Go with the Flow
MicroFlow, a Rust-based framework, optimizes AI for microcontrollers and outperforms even TensorFlow Lite in terms of memory utilization.


Every single year tens of billions of microcontrollers are shipped by manufacturers. As you might expect from this statistic, there is a staggering number of these chips powering almost every conceivable electronic device that we use on a daily basis. Microcontrollers are ideal for ubiquitous deployment because they are generally very inexpensive, however, they are also very constrained in terms of their available resources. Memory, in particular, is at a premium when it comes to microcontrollers.
This makes it challenging to build the next generation of intelligent devices. Artificial intelligence algorithms are demonstrating tremendous potential in a wide range of applications, but they tend to consume a lot of resources. Running them on a low-power system with just a few kilobytes of memory is no small task.
But that is exactly what the field of tinyML seeks to do. By heavily optimizing algorithms to run on small, resource-constrained systems, it has been demonstrated that they can handle some very useful tasks — like person or wake-word detection — on tiny platforms. There is still much work to be done, however, to effectively run these applications on the smallest of platforms. A trio of engineers at the University of Padua in Italy is working to make that possible with a framework that they call MicroFlow.
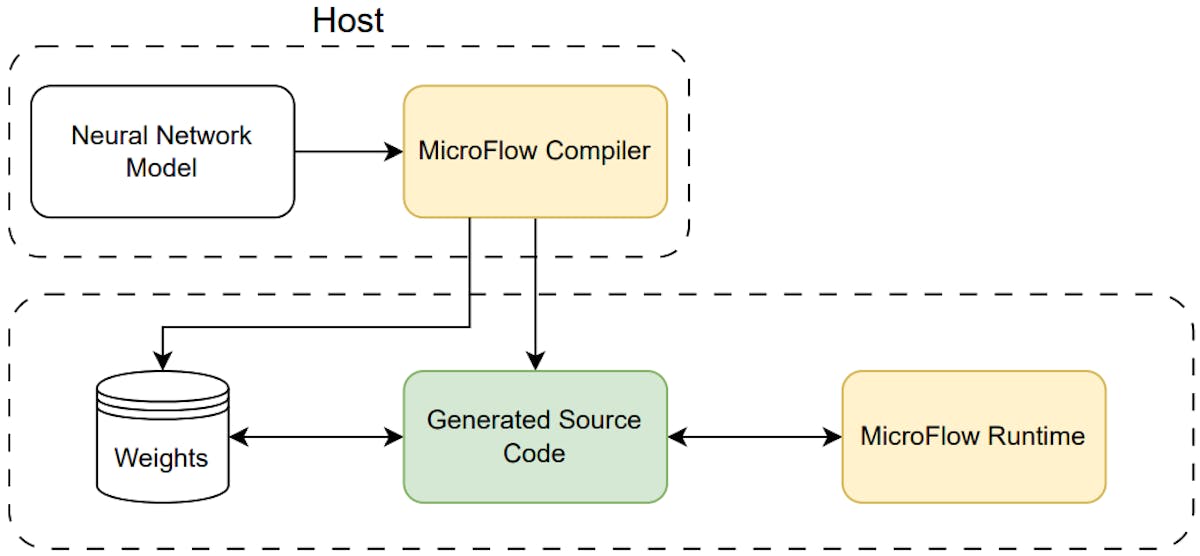
Written in the Rust programming language, MicroFlow prioritizes memory safety and efficiency, which makes it more reliable and secure compared to traditional solutions written in C or C++. Rust’s inherent memory safety features, such as protection against null pointer dereferences and buffer overflows, provide robust memory management. MicroFlow utilizes static memory allocation, where the memory required for the inference process is allocated at compile-time, ensuring efficient use of memory and eliminating the need for manual memory management.
Furthermore, MicroFlow employs a page-based memory access method, which allows only parts of the neural network model to be loaded into RAM sequentially, making it capable of running on devices with very limited resources, such as eight-bit microcontrollers. The engine is also modular and open source, enabling collaboration and further improvements within the embedded systems and IoT communities.
The experimental validation of MicroFlow involved testing its performance on three distinct neural network models of varying sizes and complexities — a sine predictor, a speech command recognizer, and a person detector. These models were run on a range of embedded systems with varying resource constraints, from the high-performance 32-bit ESP32 to the eight-bit ATmega328. MicroFlow was compared against TensorFlow Lite for Microcontrollers (TFLM), a state-of-the-art tinyML framework, in terms of accuracy, memory usage, runtime performance, and energy consumption.
In terms of accuracy, both engines performed similarly across the different models. Minor differences between the results of MicroFlow and TFLM were attributed to rounding errors and slight differences in floating-point implementations due to the engines' different programming languages.
But when it came to memory usage, MicroFlow consistently used less Flash and RAM across all tested models and microcontrollers. For instance, on the ESP32, MicroFlow used 65 percent less memory compared to TFLM. This memory efficiency allowed MicroFlow to run on extremely resource-constrained devices, such as the eight-bit ATmega328, which TFLM could not.
In terms of runtime performance, MicroFlow was up to ten times faster than TFLM on simpler models like the sine predictor, benefiting from Rust's efficient memory management and the reduced overhead of not relying on an interpreter. However, for more complex models like the person detector, the performance gap narrowed, with TFLM slightly outperforming MicroFlow by about six percent, due to the use of optimized convolutional kernels.
Finally, energy consumption for both engines was proportional to their execution times, as both utilized similar operations and peripherals, making MicroFlow's energy efficiency an extension of its faster inference times.
The team is presently at work to improve the performance of MicroFlow even more. And as an open source project, they are hoping that the community will also help to improve the framework further.
R&D, creativity, and building the next big thing you never knew you wanted are my specialties.