Less Is More
V-JEPA, Meta AI's new vision model, seeks to efficiently understand the world by learning from just a few observations, much like a human.

You would have to be living under a rock to be unaware of the enormous advances in machine learning that have taken place in recent years. These days, we can readily access a variety of AI-powered tools that can streamline tasks across countless domains, from natural language processing to image recognition and even medical diagnosis. With algorithms becoming increasingly sophisticated, the potential applications seem limitless. Whether it is predicting consumer behavior, optimizing supply chains, or personalizing user experiences, machine learning has become the cornerstone of innovation in the digital age.
The view of these tools that is available to their users is not the whole story, however. When you learn how the sausage is made, so to speak, these advanced algorithms lose some of their luster. Training them, in particular, is incredibly inefficient. Consider how a baby can learn to recognize what a cat is, or grasp a fundamental force of physics, by simply observing a cat or a cup falling from a table a few times. A machine learning model, on the other hand, must be shown many thousands, or even millions, of examples to become even remotely as proficient as the child.
All of that training requires huge amounts of energy, which is unsustainable as we try to scale up and improve these AI applications. The cost of the electricity, and the massive amounts of computational resources that are required, also prices many individuals and organizations out of the game, hindering future developments in the field. In order to continue along the present trajectory of rapid innovation, more efficient algorithms and training methods are sorely needed.
In the midst of this technological boom, Meta AI has emerged as something of an unexpected hero to the open source community. With the release of models like LLaMA, they have accelerated progress in the field, and have also made the tools more accessible, even to individuals without large budgets and computer clusters. This trend has continued with the release of their latest model, Video Joint Embedding Predictive Architecture (V-JEPA). V-JEPA is an innovative model, released under a Creative Commons NonCommercial license, that seeks to gain an understanding of the physical world after just a few observations, much like the way a human learns.
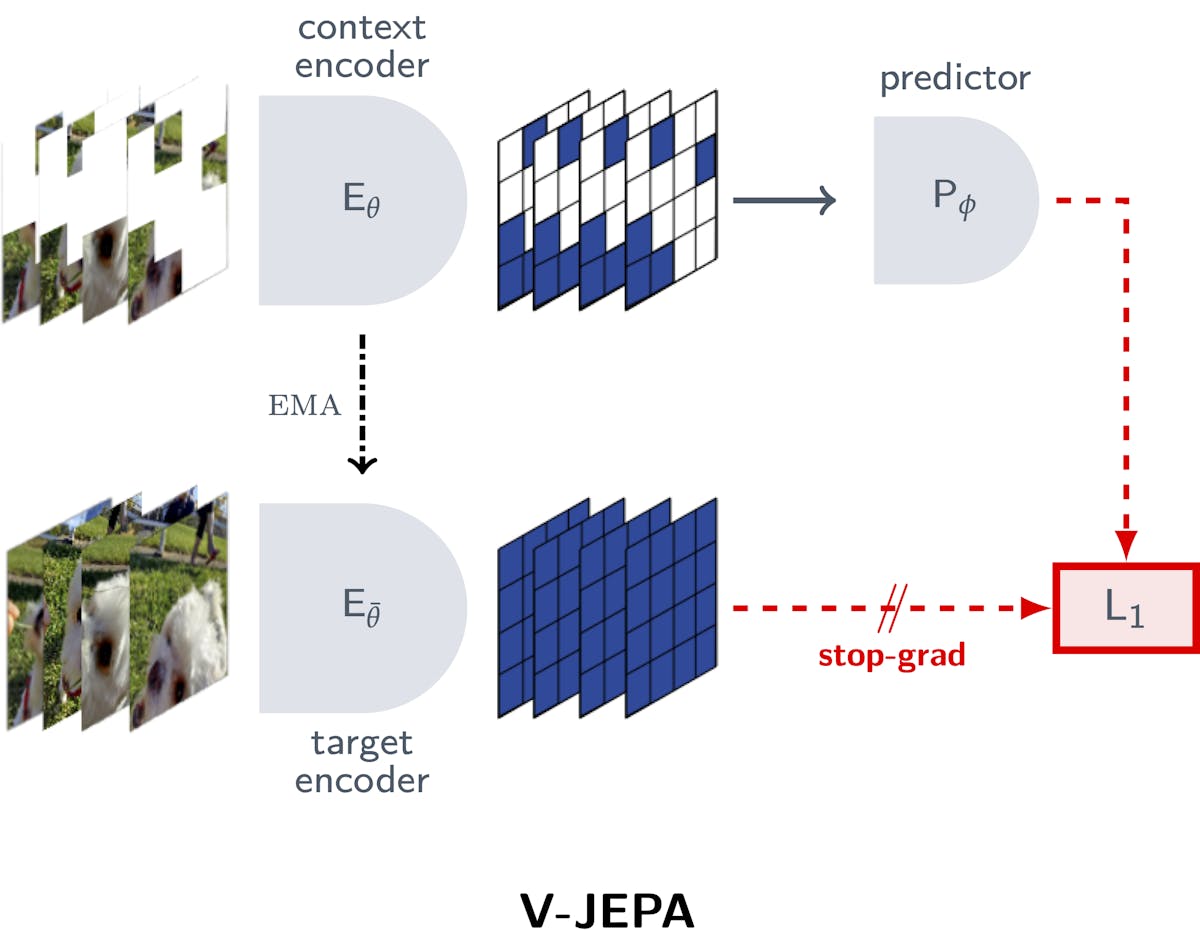
V-JEPA learns by attempting to predict what is happening in masked or missing parts of a video. It is not a generative model, which means that it does not need to predict a value for every missing pixel. The model instead learns a more abstract representation, and if a region is unpredictable or uninformative, it can simply be ignored, greatly improving training efficiency. Compared to other approaches commonly used today, V-JEPA improves training efficiency by 1.5 to 6 times.
The algorithm is first pre-trained on unlabeled data. This is important because labeling a large dataset can be extremely time-consuming and expensive, not to mention error-prone. Once the model has been trained, a smaller labeled dataset can then be utilized to fine-tune it for a particular use case. These factors also serve to make cutting edge algorithms more widely accessible.
As a next step, the developers are considering making V-JEPA multimodal by incorporating audio into the predictions. They are also exploring the possibility of making predictions over a longer time horizon to make the system more useful.
The code and model are freely available on GitHub for anyone that would like to experiment with them.
R&D, creativity, and building the next big thing you never knew you wanted are my specialties.