Microcontrollers Telling Micro Stories
With a few optimizations, Dave Bennett showed that it is possible to run a large language model locally on an ESP32-S3 microcontroller.

Microcontrollers are one of the most useful tools available to electronics hobbyists. These tiny processing units often cost less than a cup of coffee, yet they can power devices ranging from handheld gaming consoles to home assistants and wearable activity trackers. But while these chips are incredibly versatile, they certainly do have their limits. The processing power and memory of a microcontroller is highly constrained, so you would not be able to do something like run a large language model (LLM) locally on one.
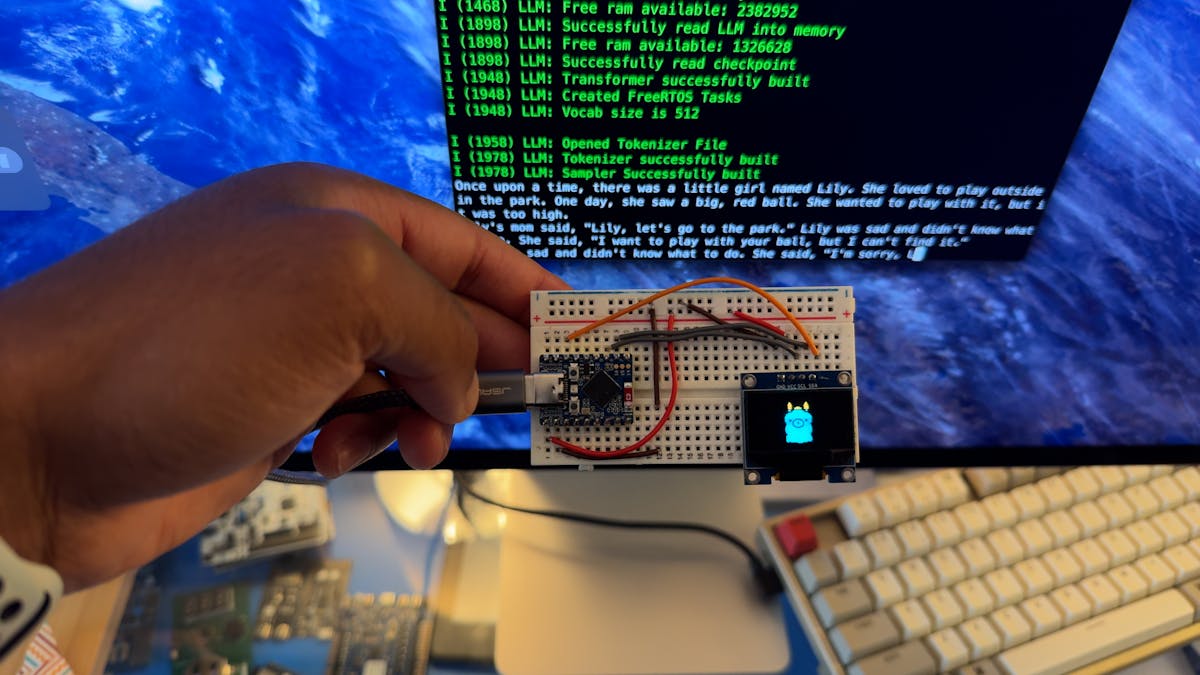
Or could you? Software engineer and filmmaker Dave Bennett has recently demonstrated that it is in fact possible to run an LLM locally on a microcontroller, but with a few caveats, of course. To make this work, Bennett started with an ESP32-S3 chip, which is fairly beefy in the world of microcontrollers. It comes equipped with dual processing cores running at up to 240 MHz, 4 MB of flash memory, and 2 MB of PSRAM.
To eke out as much from the ESP32 as possible, Bennett also modified the execution runtime of an existing LLM such that both cores of the chip would always be used during math-intensive portions of the algorithm. Furthermore, both processing cores were clocked to their maximum speed. Functions from the ESP-DSP library were also leveraged to speed up dot product calculations, which are crucial to neural networks. The performance gains are largely achieved by utilizing the SIMD instructions that are available to the ESP32-S3.
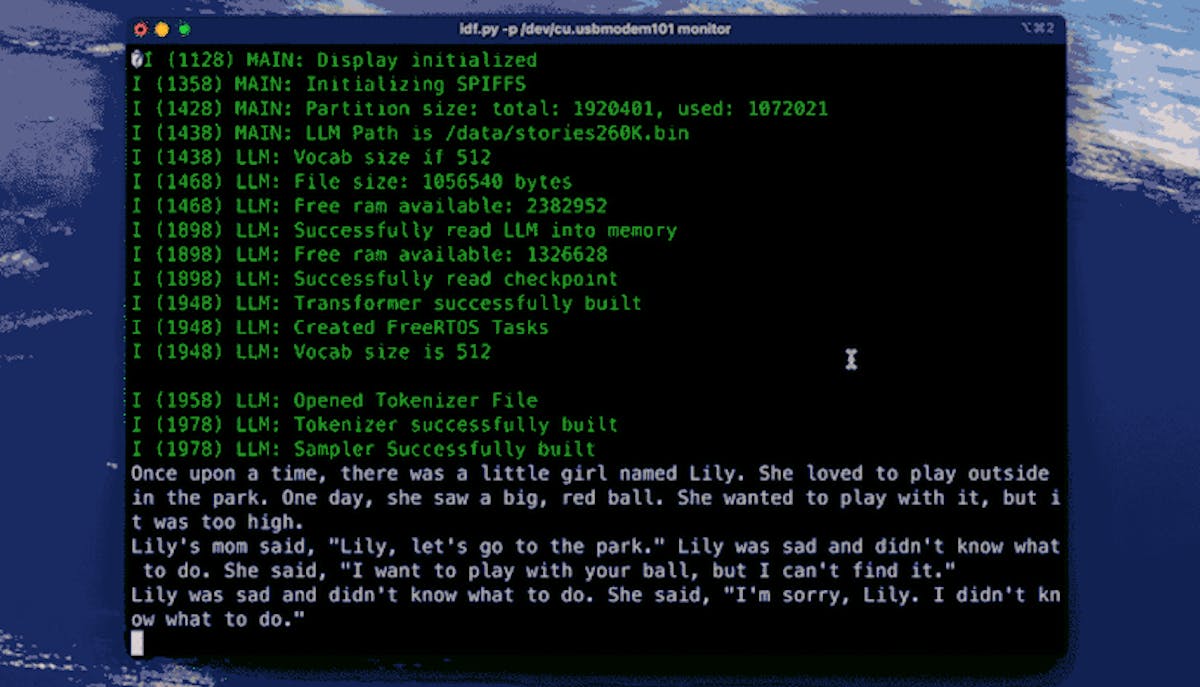
In order to run the LLM model, the llama2.c framework was selected. Of course running a GPT-4 class model was completely out of the question, but there was enough PSRAM available to run a 260,000 parameter tinyllamas model. That is a far cry from the billions or trillions of parameters present in state of the art LLMs, but a model of this size can still be useful in its own right.
As a result of these hacks, Bennett was able to achieve a processing speed of over 19 tokens per second.
The LLM was trained only on the TinyStories dataset, which consists of very short stories and a limited vocabulary. As such, it is not good for much aside from making up some creative short stories of its own. It is certainly not a general-purpose LLM that you can ask questions about virtually any topic — at least not if you are hoping for a reasonably accurate response, anyway.

Only light details are available, so this project might be tough to get up and running unless you are already familiar with ESP32 microcontrollers and the associated toolchains. But if you are, the full source code is available on GitHub to get you going. A microcontroller that can tell stories could make for some very interesting projects, so make sure to post anything you create on Hackster so that we can take a look!
R&D, creativity, and building the next big thing you never knew you wanted are my specialties.