

Hardware components | ||||||
_uOW364MAan.jpg?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
Audio classification using Machine Learning could have many useful applications for daily tasks and has the potential to make our lives easier.
Machine Learning models could cover a wide variety of uses going from image classification, movement classification and even audio classification. In this project we are going to work on a ML audio model, which is not as common as image classification ones.
As human beings we are capable of identifying different noises and raise conclussions from them e.g. siren sounds tell us that the fire brigade is on its way to extinguish a fire, pitter-patter noise on the ceiling of hour houses can indicate us that is raining outside, etc. In this project my target is to train a ML model to identify different sound patterns from a running fan.
By doing so we could make a tiny microcontroller able to classify audio and trigger some outputs according to its identified category from the ML model.
This project will:
- Develop a Machine Learning model to perform audio classification of different fan noises
- Show fan operational status using Arduino Portenta's in-built LED
Project has been developed to run a ML model in an Arduino Portenta H7 + Vision Shield to detect operation conditions of a fan by measuring its noise.
Fan used in this project is small sized and powered by USB (low power consumption)
Samples have been taken considering four different conditions:
- Fan not running: Background noise
- Fan running: Normally, Soft failure or Severe failure
Failures of the fan were forced by placing objects interfering its rotation. The fan that I'm running has soft and foamy blades which are not a source of danger. If you are doing this at your home and your fan does not have soft and foamy blades do not continue with this project!
ML model will run in an Arduino Portenta H7 + Vision Shield that will measure environmental noise with its in-built microphone and will run the model to detect fan's operational condition. Expected output of the model will be the flashing of the microcontroller in-built LEDs following a color coded standard:
- Green LED ON: Fan running normally
- Orange LED ON: Fan running with soft failure
- Red LED ON: Fan running with severe failure
- LED OFF: Fan not running, just background noise
ML model outputs are in fact probabilities, where of course the sum of the categories probabilities equals to one. When the model makes its predictions what is actually doing is selecting the category with the maximum probability. But in some cases two different categories could have similar probabilities, and the model will be forced to make a decision even though its not sure enough.
For those specific situations, I had decided to add an additional condition for the model and turn ON a blue LED. In a future project, models performace could be improved by adding more samples for that confusing conditions that flashed the blue LED. By doing so we will be able to improve its performance.
So, as a quick summary decission tree will now look like this:
If the probability is lower than the theshold value:
- Blue LED ON: Unable to make a sound classification
If the probability is greater than threshold value:
- Green LED ON: Fan running normally
- Orange LED ON: Fan running with soft failure
- Red LED ON: Fan running with severe failure
- LED OFF: Fan not running, just background noise
You'll need the following:
- A device with an in-built microphone (in this case I'm using an Arduino Portenta + Vision Shield)
- An account on Edge Impulse (edgeimpulse.com)
- Arduino Web Editor (https://create.arduino.cc/editor/)
One of the most important tasks while developing a ML model is to generate its data set. It should be as similar as possible to actual operation conditions while also taking into account potential undesired sources from the environment (people chatting, music being played, etc.)
While taking the samples the ideal scenario would be to take them with the same equipment that will be used to run the model in the edge. In my case and for practical reasons, I've decided that it was not the most practical way so I've simply downloaded an app called Voice Recorder & Voice Memos from Simple Design Ltd to take the samples.
While taking the samples with a different equipment than the one that that will be used to run the model it's really important to keep in mind the characteristics of sensor that is going to measure and run the ML model, specially for audio models.
Audio files have different characteristics that define them, For this project I took the following settings:
- Format: WAV files
- Channels: 1 (Mono)
- Frequency: 16 kHz (according to Arduino Portenta)
- Bitrate: 32kbps
If you are using a different microcontroller keep this in mind to set samples frequency as the one of your microcontroller.
Training of ML models require a lot of samples in order to properly identify patterns. For practical reasons I decided to take just 4 samples, one for each category, of 15 minutes of length and then divide them in shorter samples. The bigger the data set the better so if you want to take longer samples go for it!
While taking the samples I tried to simulate different environmental conditions for each category e.g. people chatting, music in the background, daily noises as dogs barking, vehicle noises, etc. This is important because the model will be better at understanding what each sample of the same category has in common and discard random noise.
After you take each sample the app allows you to assign a name to it. It's always useful to be consistent and use the same name for the audio sample that you are going to use for the ML categories.
Once that you've got your samples taken now we are going to divide those samples into smaller cuts of 2 seconds of length. (15 minutes * 60 seconds/minute = 900 seconds. 900 seconds / 2 seconds per sample = 450 samples per category)
import wave
import math
sample = ["background", "normal", "severe", "soft"] // sample audio file names
// audio files are expected to be saved in the same location than this python code
for x in sample:
file = x + ".wav"
# Open the input wave file
with wave.open(file, 'rb') as wav_in:
# Get the sample rate and number of channels
sample_rate = wav_in.getframerate()
num_channels = wav_in.getnchannels()
# Calculate the number of samples in a 2-second segment
segment_length = sample_rate * 2
# Open each output wave file
for i in range(math.ceil(wav_in.getnframes() / segment_length)):
cut_name = x + " " + str(i) + ".wav"
with wave.open(cut_name, 'wb') as wav_out:
# Set the parameters for the output wave file
wav_out.setnchannels(num_channels)
wav_out.setsampwidth(wav_in.getsampwidth())
wav_out.setframerate(sample_rate)
# Read and write the 2-second segment of audio data
segment_data = wav_in.readframes(segment_length)
wav_out.writeframes(segment_data)It's always important to double check that each file that we are going to upload o train the model has the same characteristics, so please double check that there are no files that last less than 2 seconds, if there are delete them.
Last but not least, you could use data augmentation and increase the amount of samples of your model by adding some synthetic sounds to your samples. By doing so you can also include some regular sounds that were not present at the time that you took the samples.
Sampling biasesIts important to be extremely careful while taking the samples because a biased dataset could seriously affect model performance in its real world application. In other words, model will perform well if the real world measurements are similar to the ones in its training. It that's not the case, the model could see its performance seriously affected.
In this case, there are a few biases that I considered as acceptable as:
- Samples were taken from the same distance to the fan. Sound gets louder when you are closer to its source and get more quiet when you are far from it. Therefore, microphone distance to the source could affect models performance
- I only used one fan to take the samples. Different fan models could make different noises on failure. So, we can assume that this model will only perform well on this fan
- Fan failures could make different noises and many of them could have not been captured or reproduced while taking the samples
- Machinery and vehicle noises were left out of the scope
- Sample data set has human voices, but I only considered them while chatting. If they are screaming, whispering or even if there are different people talking with different voice pitches it could affect models performace
- Microphone was placed in front of the fan, without any objects interfering. Objects standing in the way could have an impact on microphones measurements and in models performance
To improve models performance and adaptability, a wider amount of samples and in different conditions should be considered (including the ones mentioned above).
Develop Machine Learning model using Edge ImpulseYou can find the finished project following this link or you can follow this step by step guideline:
First, log into Edge Impulse and select Create new project. Name it and select the Developer option prior clicking on Create new project button.
Continue by selecting Audio and then on Lets get started! button.
Now you should have been directed to your projects main page.
Once that you are there click into Data acquisition and then on Uploaddata. Select Choosefiles and then select every audio sample that we've previously cut. Then select Automatically split between training and testing and do not forget to input the label (background, normal, soft, severe) prior clicking on Begin upload. Edge Impulse will start uploading the files into their server and once that is finished it should show "Files that failed to upload: 0" on the right side of the screen.
Repeat this step for each one of the remaining categories.
To create our Impulse select on Impulse design and in Create Impulse.
I had set the Time series data with:
- Window size of 1000 ms (1 sec)
- Window increase of 500 ms (0.5 sec)
- Frequency of 16000 Hz (16 kHz)
As Processing block I selected the recommended block by Edge Impulse that was MFE.
For the Learning block I selected Classifier.
If you had followed the steps your design should look like the one in the image below. It if does click on Save Impulse.
Continue by clicking on MFE under Createimpulse. Then on Save parameters with the suggested parameters and once that the parameters have been saved click on Generate features.
MFE diagrams condense data from audio samples. In its x-axis we have the time (sec) whereas in the y-axis we have the frequencies (Hz). Different colors represent the intensity of the signal at that given frequency and time.
From the image above we can get a lot of information as: between 0.45 and 0.56 seconds the audio had its peak of intensity (intense red), there are a few frequencies that seem to be persistent in time (e.g. 355, 907, 1286, 1753, etc.), there were specific times that registered high intensities on frequencies that were calm (e.g. between 0.11 and 0.22, or between 0.34 and 0.45, or between 0.56 and 0.67)
Once that Edge Impulse had generated the features we can have a hint of how well our model is going to perform. If each of the categories is distant from the other we can conclude that model will perform well distinguishing between categories. In this case, as we are working with audio samples that have loads of parameters and that the plots only can show 2 dimensions, we won't be able to make a lean conclussion from this plot.
We continue training the model on the Classifier tab by clicking on Start Training. As it can be seen, I had left defaults training parametres.
Once that the model has been trained we will know its performance for the validation set.
If we analyze models training performance we can conclude the following:
- Accuracy is 98, 9% which is a very good value
- From the confusion matrix we can identify that the model has minor issues in seggregating between background and severe noises. This can be seen clearly in the plot due to a slight overlapping between both categories
- From the confusion matrix and the plot we can recognize the the model has no issues to identify soft noise (cloud of dots at the right) and slight issues to identify normal noise (cloud of dots at the bottom)
- Inferencing time is very low (2 ms) and will help us to run the model at a very high rate
Now that we know how the model performs with known data we are going to test the model to classify unknown data. To do so we have to select Model testing and then Classify all.
In this case we can see that the model decreases its accuracy to 95, 89% but still has a very good performance.
If we analyze this new confusion matrix we can conclude that the model has its lower performance in identifying normal noise and that usually confuses it with background noise.
Lastly, we can download the code to run the model in the Arduino Portenta + Vision Shield to test in the real world. To download the files from Edge Impulse we have to go to Deployment and select the presentation that best fits our needs.
Edge Impulse model has been designed to take sound samples, analyze them using the ML model and print on the screen the results. We can download it etiher as Arduino library or Arduino Portenta H7 firmware. As we'll be doing some slight changes to blink different LED lights according to models diagnose we'll download the Arduino library.
Arduino CodeOnce that we've downloaded the library we can continue by opening it on the Arduino IDE. We can choose between running the code from the desktop app or from the web version. As I have found some issues uploading the code into the desktop app I suggest uploading the code to the web version.
To open Arduino Web Editor you should go to its webpage (https://create.arduino.cc/editor) and log in.
On the editor we have to check a few things prior running the code downloaded from Edge Impulse. First we have to check that our boards libraries are installed. In order to do that we will search on the Libraries for Arduino Portenta boards. Once that Portenta's libraries have been installed we can test that the Web Editor is capable of uploading code to the Arduino Portenta, so we are going to run a few quick checks.
First we are going to run a code that blinks the in-built green LED on the board. To do so create a New sketch on the Web Editor and paste the following code:
void setup() {
pinMode(LEDG, OUTPUT); // Set Red LED pin to output mode
}
void loop() {
digitalWrite(LEDG, LOW); // LED is active low : 0 = LED on, 1 = LED off
delay(1000); // Hold for visibility
digitalWrite(LEDG, HIGH); // LED off
delay(1000);
}Check that your board is connected and than its selected from the drop down list and then press on the arrow pointing to the right to upload the sketch.
After a few seconds you should see a success message at the bottom of your screen and the in-built LED should start flashing every second.
If our first test was sucessful, we continue with our next test where we are going to flash 4 different colors. Once again, select on create New sketch and paste the following code:
void setup()
{
pinMode(LEDR, OUTPUT); // Set Red LED pin to output mode
pinMode(LEDG, OUTPUT); // Set Green LED pin to output mode
pinMode(LEDB, OUTPUT); // Set Blue LED pin to output mode
}
void loop()
{
//red color
digitalWrite(LEDR, LOW); // LED is active low : 0 = LED on, 1 = LED off
delay(200); // Hold for visibility
digitalWrite(LEDR, HIGH); // LED off
delay(200); // Hold
//green color
digitalWrite(LEDG, LOW); // LED is active low : 0 = LED on, 1 = LED off
delay(200); // Hold for visibility
digitalWrite(LEDG, HIGH); // LED off
delay(200);
//blue color
digitalWrite(LEDB, LOW); // LED is active low : 0 = LED on, 1 = LED off
delay(200); // Hold for visibility
digitalWrite(LEDB, HIGH); // LED off
delay(200);
//orange color
digitalWrite(LEDR, LOW); // LED is active low : 0 = LED on, 1 = LED off
digitalWrite(LEDG, LOW); // LED is active low : 0 = LED on, 1 = LED off
delay(200); // Hold for visibility
digitalWrite(LEDR, HIGH); // LED off
digitalWrite(LEDG, HIGH); // LED off
delay(200); // Hold
}After uploading the sketch to your board you should see the LED lights flashing in the following order: red, green, blue and orange.
If the check was correct we can be sure that the LEDs are working correctly. Now its time to check Arduino Portenta + Vision shield in-built microphone. To do it please search for the PDMSerialPlotter example in Web Editor's search bar or upload the following code:
#include <PDM.h>
static const char channels = 1; // default number of output channels
static const int frequency = 16000; // default PCM output frequency and the one that matches with our samples
short sampleBuffer[512]; // Buffer to read samples into, each sample is 16-bits
volatile int samplesRead; // Number of audio samples read
void setup() {
Serial.begin(9600);
while (!Serial);
PDM.onReceive(onPDMdata); // Configure the data receive callback
// Optionally set the gain
// Defaults to 20 on the BLE Sense and 24 on the Portenta Vision Shield
// PDM.setGain(30);
// Initialize PDM with:
// - one channel (mono mode)
// - a 16 kHz sample rate for the Arduino Nano 33 BLE Sense
// - a 32 kHz or 64 kHz sample rate for the Arduino Portenta Vision Shield
if (!PDM.begin(channels, frequency)) {
Serial.println("Failed to start PDM!");
while (1);
}
}
void loop()
{
// Wait for samples to be read
if (samplesRead)
{
for (int i = 0; i < samplesRead; i++)
{
if(channels == 2)
{
Serial.print("L:");
Serial.print(sampleBuffer[i]); // Print samples to the serial monitor or plotter
Serial.print(" R:");
i++;
}
Serial.println(sampleBuffer[i]);
}
samplesRead = 0; // Clear the read count
}
}
void onPDMdata() {
int bytesAvailable = PDM.available(); // Query the number of available bytes
PDM.read(sampleBuffer, bytesAvailable); // Read into the sample buffer
samplesRead = bytesAvailable / 2; // 16-bit, 2 bytes per sample
}Note that the frequency variable (static const int) has been set by default at 16000. That frequency matches the one that we used to take our samples.
Once that the sketch has been uploaded to the board we can check if the board is actually measuring noise by opening the Monitor. If the sketch is running correctly you should see numbers popping into the screen.
So, if you had reached this point let me tell you that we are just two steps far from having our project up and running.
Next step is going to be importing Edge Impulse code into the Web Editor. Doing it is pretty straight forward: click on Libraries and then on the Upload icon, then on Import and select Arduino's library ZIP file downloaded from Edge Impulse.
Once imported click back on Libraries and now in Custom ant then select your board and microphone_continuous example (in my case was portenta_h7 and portenta_h7_microphone_continuous). Our sketch should now be there. Simply select it and upload that sketch to your board. This time might be a longer wait but still should be fast enough.
When the upload has been finished select on Monitor and you should see how the board is not only measuring the audio but also classifying it!
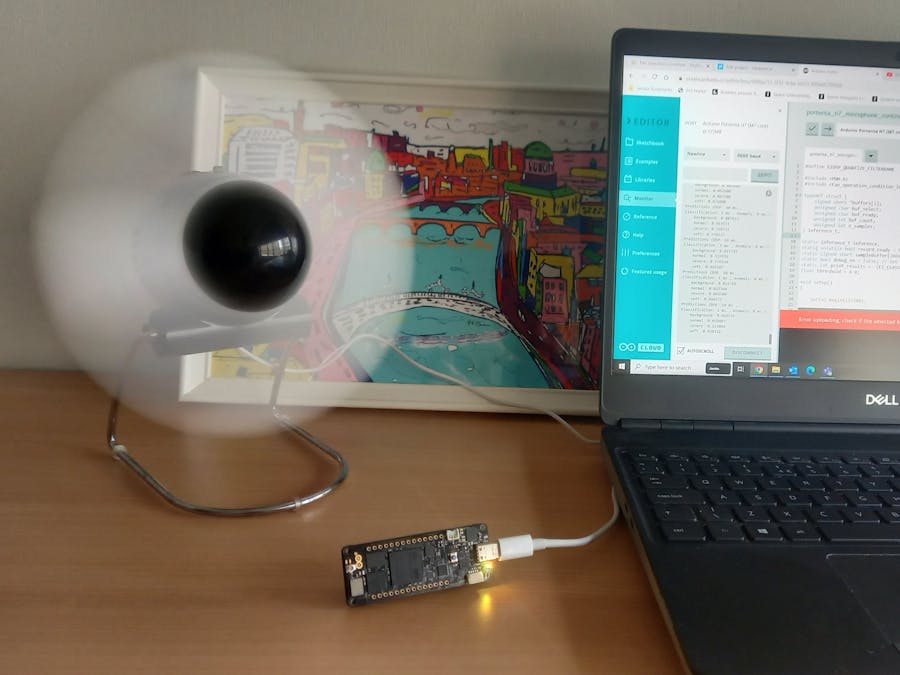
PHOTO (BOARD + FAN + SERIAL MONITOR)
Last step is now to incorporate our LED functionalities to Edge Impulse's code. To include them copy and paste the following code and upload the sketch to your board:
#define EIDSP_QUANTIZE_FILTERBANK 0
#include <PDM.h>
#include <Fan_operation_condition_inferencing.h>
typedef struct
{
signed short *buffers[2];
unsigned char buf_select;
unsigned char buf_ready;
unsigned int buf_count;
unsigned int n_samples;
} inference_t;
static inference_t inference;
static volatile bool record_ready = false;
static signed short sampleBuffer[2048];
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static int print_results = -(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW);
float threshold = 0.8;
void setup()
{
Serial.begin(115200);
pinMode(LEDR, OUTPUT);
pinMode(LEDG, OUTPUT);
pinMode(LEDB, OUTPUT);
while (!Serial);
Serial.println("Edge Impulse Inferencing Demo");
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: ");
ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf(" ms.\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
run_classifier_init();
if (microphone_inference_start(EI_CLASSIFIER_SLICE_SIZE) == false)
{
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
}
void loop()
{
bool m = microphone_inference_record();
if (!m)
{
ei_printf("ERR: Failed to record audio...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_SLICE_SIZE;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = {0};
EI_IMPULSE_ERROR r = run_classifier_continuous(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK)
{
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
if (++print_results >= (EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW))
{
ei_printf("Predictions "); // print the predictions
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)", result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++)
{
//0: background, 1: normal, 2: severe, 3: soft
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
}
if (result.classification[0].value > threshold)
{
//LEDs turned off if background
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
}
else if (result.classification[1].value > threshold)
{
//Green LED turned on if normal
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, LOW);
digitalWrite(LEDB, HIGH);
}
else if (result.classification[2].value > threshold)
{
//Red LED turned on if severe
digitalWrite(LEDR, LOW);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, HIGH);
}
else if (result.classification[3].value > threshold)
{
//Orange(Red + Green) LED turned on if soft
digitalWrite(LEDR, LOW);
digitalWrite(LEDG, LOW);
digitalWrite(LEDB, HIGH);
}
else
{
//Blue LED turned on if model cannot predict with high confidence
digitalWrite(LEDR, HIGH);
digitalWrite(LEDG, HIGH);
digitalWrite(LEDB, LOW);
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
print_results = 0;
}
}
static void pdm_data_ready_inference_callback(void)
{
int bytesAvailable = PDM.available();
int bytesRead = PDM.read((char *)&sampleBuffer[0], bytesAvailable);
if ((inference.buf_ready == 0) && (record_ready == true))
{
for(int i = 0; i < bytesRead>>1; i++)
{
inference.buffers[inference.buf_select][inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples)
{
inference.buf_select ^= 1;
inference.buf_count = 0;
inference.buf_ready = 1;
break;
}
}
}
}
static bool microphone_inference_start(uint32_t n_samples)
{
inference.buffers[0] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[0] == NULL)
{
return false;
}
inference.buffers[1] = (signed short *)malloc(n_samples * sizeof(signed short));
if (inference.buffers[1] == NULL)
{
ei_free(inference.buffers[0]);
return false;
}
inference.buf_select = 0;
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
PDM.onReceive(&pdm_data_ready_inference_callback);
PDM.setBufferSize(2048);
if (!PDM.begin(1, EI_CLASSIFIER_FREQUENCY))
{
ei_printf("ERR: Failed to start PDM!");
return false;
}
record_ready = true;
return true;
}
static bool microphone_inference_record(void)
{
bool ret = true;
if (inference.buf_ready == 1)
{
ei_printf("Error sample buffer overrun. Decrease the number of slices per model window ""(EI_CLASSIFIER_SLICES_PER_MODEL_WINDOW)\n");
ret = false;
}
while (inference.buf_ready == 0)
{
delay(1);
}
inference.buf_ready = 0;
return ret;
}
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr)
{
numpy::int16_to_float(&inference.buffers[inference.buf_select ^ 1][offset], out_ptr, length);
return 0;
}
static void microphone_inference_end(void)
{
PDM.end();
ei_free(inference.buffers[0]);
ei_free(inference.buffers[1]);
record_ready = false;
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endifMain changes in this new sketch from the previous one are:
- Taking into consideration that the output is a probability, I decided to set a threshold variable and to light the green, red and orange LED's only when the output of the model was more than 80% certain. If it's certainty was less than the threshold it will flash the blue LED.
- Included IF's to flash the LED's according to the color coded standard mentioned above
We've been able to develop a Machine Learning model that classifies different audio patterns and triggers an action (flash a LED) according to it.
We've uploaded the model developed by Edge Impulse to an Arduino Portenta H7 + Vision Shield through Arduino's Web Editor. We could confirm that it performed very well taking into account the limited data used for the training steps. In the near future would be interesting to see if models performance could be improved by data augmentation with synthetic audios.
Lastly, It's worth to mention that this model has many biases, but as long as its running under specific conditions we can have a lean performance with just a few audio samples.






Comments
Please log in or sign up to comment.