


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
_ztBMuBhMHo.jpg?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
- My Aim: To create a simple, cheap and open source way to recover data from Amiga DD floppy disks from within Windows 10 and other operating systems.
- My Solution: An Arduino + a Windows application
- Why: To preserve data from these disks for the future. Also, a normal PC can't read Amiga disks due to the way they are written.
Project Website: http://amiga.robsmithdev.co.uk/
This is V1 of the project. V2 contains improved reading and writing!
Amiga ExperiencesI owe my career to the Amiga, specifically the A500+ that my parents purchased for me for Christmas at the age of 10. At first I played the games, but after a while I started getting curious about what else it could do. I played with the Deluxe Paint III and learnt about Workbench.
The Amiga 500 Plus:
Every month I purchased the popular Amiga Format magazine. One month had a free copy of AMOS. I entered the Amiga Format Write A Game In AMOS competition when AMOS Professional was put on a coverdisk later, and was one of the 12 (I think) winners with In The Pipe Line. You really had to chase them for prizes though!
AMOS - The Creator:
Moving on, I used it as part of my GCSEs and A-Level projects (thanks to Highspeed Pascal, which was compatible with Turbo Pascal on the PC)
Anyway, that was a long time ago, and I have boxes of disks, and an A500+ that doesn’t work anymore, so I thought about backing those disks up onto my computer, for both preservation and nostalgia.
The Amiga Forever website has an excellent list of options that include hardware, and abusing two floppy drives in a PC - Sadly none of these were an option with modern hardware, and the KryoFlux/Catweasel controllers are too expensive. I was really surprised that most of it was closed source.
Massively into electronics and having played with Atmel devices (AT89C4051) whilst at University I decided to take a look at the Arduino (credit to GreatScott for the inspiration showing just how easy it is to get started) I wondered if this was possible.
So I Googled for Arduino floppy drive reading code, and after skipping all of the projects that abused the drive to play music, I didn’t really find any solutions. I found a few discussions in a few groups suggesting it wouldn’t be possible. I did find a project based around an FPGA which was very interesting reading, but not the direction I wanted to go, so the only option was to build a solution myself.
ResearchWhen I started this project I hadn’t got a clue how the floppy drive worked, and even less how the data was encoded onto them. The following websites were invaluable in my understanding on what happens and how they work:
- The .ADF (Amiga Disk File) format FAQ by Laurent Clévy
Based on the research I now knew theoretically how the data was written to the disk, and how the disk spun.
I began to work out some numbers. Based on the speed the double density disk rotated at (300rpm) and the way the data is stored (80 tracks, 11 sectors per track and 512 bytes per sector, encoded using MFM), to read the data accurately I needed to be able to sample the data at 500Khz; that’s quite fast when you consider the Arduino is only running at 16Mhz.
In the attempts that follow I’m only talking about the Arduino side. Jump to decoding.
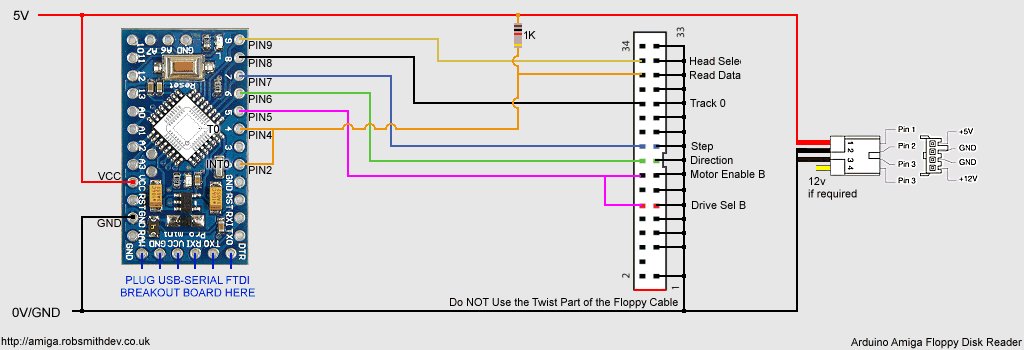
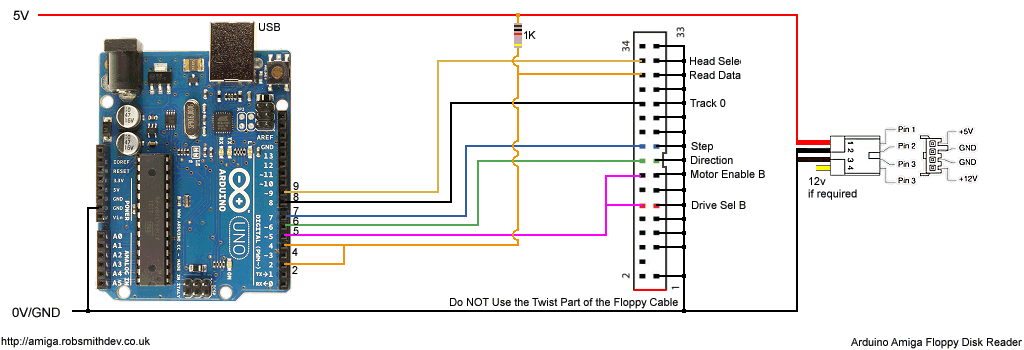
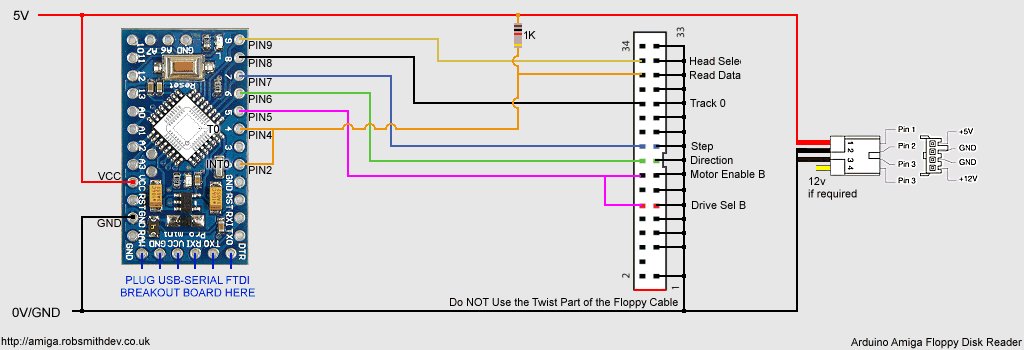
Attempt 1:First I needed to gather the hardware and interface to the floppy drive. The floppy drive I took from an old PC at work, and grabbed its IDE cable at the same time.
Below is a photo of liberated floppy drive from an old PC:
Studying the pinout of the drive I realised I only needed a few of the wires from it, and after looking at the drive I realised it didn't use the 12v input either.
Getting the drive spinning was achieved by selecting the drive and enabling the motor. Moving the head was simple. You set the /DIR pin high or low, and then pulsed the /STEP pin. You could tell if the head had reached track 0 (the first track) by monitoring the /TRK00 pin.
I was curious about the /INDEX pin. This pulses once each rotation. As the Amiga doesn't use this to find the start of the track I didn't need it and could ignore it. After this its just a matter of choosing which side of the disk to read (/SIDE1) and connecting up /RDATA.
With the high data rate requirement my first thought was to find a way to make this less of an issue by trying to reduce the requirements on this rate.
The plan was to use two 8-bit shift registers (SN74HC594N) to reduce the required sampling frequency by a factor of 8. I used was what Ebay called Pro Mini atmega328 Board 5V 16M Arduino Compatible Nano (so I dont know what that is officially, but this does work on the Uno!) to buffer this parallel data and send it to the PC using it’s serial/USART interface. I knew this needed to be running faster than 500Kbaud (with all of the serial overhead involved too).
After ditching the standard Arduino serial library, I was really pleased to find I could configure the USART on the Arduino at uptp 2M baud, and with one of those F2DI break-out boards (eBay called it Basic Breakout Board For FTDI FT232RL USB to Serial IC For Arduino - see below) I could happily and send and receive data at this rate (62.5Khz) but I needed to do this accurately.
The FTDI breakout board that perfectly fits the interface on the Arduino board:
First, I used the Arduino to setup on of the 8-bit shift registers only one of the 8 bits clocked high. The other received a feed directly from the floppy drive (thus providing serial to parallel conversion).
The following is a crazy picture of the breadboard I built this on at the time:
I used one of the Arduinos timers to generate a 500Khz signal on one of its output pins and as the hardware manages this it is very accurate! - Well, my multimeter measured it as exactly 500khz anyway.
The code worked, I clocked in a full 8-bits of data at 62.5khz, leaving the Arduino CPU hardly utilized. However I wasn’t receiving anything meaningful. At this point I realised I needed to take a closer look at the actual data coming out of the floppy drive. So I purchased a cheap old oscilloscope from eBay (Gould OS300 20Mhz Oscilloscope) to check out what was going on.
Whilst waiting for the oscilloscope to arrive I decided to try something else.
A fragment of code used to read the data from the shift registers:
void readTrackData() {
byte op;
for (int a=0; a<5632; a++) {
// We'll wait for the "byte" start marker
while (digitalRead(PIN_BYTE_READ_SIGNAL)==LOW) {};
// Read the byte
op=0;
if (digitalRead(DATA_LOWER_NIBBLE_PB0)==HIGH) op|=1;
if (digitalRead(DATA_LOWER_NIBBLE_PB1)==HIGH) op|=2;
if (digitalRead(DATA_LOWER_NIBBLE_PB2)==HIGH) op|=4;
if (digitalRead(DATA_LOWER_NIBBLE_PB3)==HIGH) op|=8;
if (digitalRead(DATA_UPPER_NIBBLE_A0)==HIGH) op|=16;
if (digitalRead(DATA_UPPER_NIBBLE_A1)==HIGH) op|=32;
if (digitalRead(DATA_UPPER_NIBBLE_A2)==HIGH) op|=64;
if (digitalRead(DATA_UPPER_NIBBLE_A3)==HIGH) op|=128;
writeByteToUART(op);
// Wait for high to drop again
while (digitalRead(PIN_BYTE_READ_SIGNAL)==HIGH) {};
}
}
I decided that the shift registers, whilst a nice idea probably weren’t helping. I was able to easily read 8 bits in one go, but it occurred to me that I couldn’t be sure that all of the bits were clocked in correctly in the first place. Reading the documentation it suggested that the data were more of short pulses rather than highs and lows.
I removed the shift registers and wondered what would happen if I tried to check for a pulse from the drive in an Interrupt (ISR) using the previously setup 500Khz signal. I reconfigured the Arduino to generate the ISR, and after I got passed the issues of the Arduino libraries getting in the way (using the ISR I wanted) I moved to Timer 2.
I wrote a short ISR that would shift left a global single byte by one bit and then if the pin connected to the floppy drive data line was LOW (the pulses are low-going) I would OR a 1 onto it. Every 8 times I did this I wrote the completed byte to the USART.
This didn't go as expected! The Arduino started to behave very erratically and strange. I soon realised the ISR was taking more time to execute than than the time between calls to it. I could receive a pulse every 2µSec and based on the speed of the Arduino, and making a wild assumption that every C instruction translated to 1 clock machine code cycle, I realised I could at most have 32 instructions. Sadly most would be more than one instruction, and after Googling I realised the overhead on starting an ISR was massive anyway; not to mention the digitalRead functions being very slow.
I ditched the digitalRead function in favour of accessing the port pins directly! This still didn’t help and wasn’t fast enough. Not prepared to give up, I shelved this approach and decided to move on and try something else.
At this point the oscilloscope that I purchased arrived, and it worked! A crusty old Oscilloscope that was probably older than me! But still did the job perfectly. (If you don’t know what an Oscilloscope is check out EEVblog #926 - Introduction To The Oscilloscope, and if you're into electronics then I suggest watching a few more and having a browse around the EEVBlog website.
My newly purchased crusty old Oscilloscope (Gould OS300 20Mhz):
After connecting the 500Khz signal to one channel and the output from the floppy drive to another it was obvious something wasn’t right. The 500Khz signal was a perfect square wave using it as a trigger, the floppy data was all over the place. I could see the pulses, but it was more of a blur.Likewise if I triggered from the floppy drive signal, the 500Khz signal square wave signal was all over the place and not in sync with it.
Photos of the traces on the oscilloscope triggering off of the two channels. You cant quite see it, but on the channel not being triggered is thousands of faint ghostly lines:
Individually I could measure pulses from both signals at 500Khz, which didn’t make sense, as if they were both running at the same speed but won’t trigger so you can see both signals properly then something must be wrong.
After a lot of playing with the trigger levels I managed to work out what was going on. My signal was a perfect 500Khz, but looking at the floppy drive signal, well they were spaced correctly, but not all the time. Between groups of pulses there was an error drift, ans also gaps in the data that put the signal totally out of sync.
Remembering the previous research, the drive was supposed to rotate at 300rpm, but it might not actually be exactly 300rpm, plus the drive that wrote the data might also not be at exactly 300rpm. Then there is the spacing between sectors and sector gaps. Clearly there was a synchronisation issue, and synchronising the 500Khz signal to the floppy drive at the start of a read wasn’t going to work.
I also discovered that the pulse from the floppy drive was extremely short, although you could modify this by changing the pullup resistor, and if the timing was not exactly right then the Arduino might miss a pulse all together.
When I was at university (University of Leicester) I took a module called embedded system. We studied the Atmel 8051 microcontrollers. One of the projects involved counting pulses from a simulated weather station (rotary encoder). Back then I sampled the pin at regular intervals, but this wasn't very accurate.
The module lecturer, Prof Pont suggested that I should have used the hardware counter features of the device (I didn’t even know it had one the time.)
I checked the datasheet for the ATMega328 and sure enough each of the three timers could be configured to count pulses triggered from an external input. This meant speed was no longer an issue. All I actually needed to know was if a pulse had occured within a 2µSec time window.
Attempt 3:I adjusted the Arduino sketch to reset the 500khz timer when the first pulse was detected and eack time the 500khz timer overflowed I checked the counter value to see if a pulse had been detected. I then performed the same bit-shifting sequence and every 8 bits wrote out a byte to the USART.
Data was coming in and I started to analyse it on the PC. In the data I started to see what looked like valid data. The odd sync word would appear, or groups of 0xAAAA sequences, but nothing reliable. I knew I was on to something, but was still missing something.
Attempt 4:I realised that as the data was being read, the data from the drive was probably going out of sync/phase with my 500khz signal. I confirmed this by just reading 20 bytes each time I started reading.
Reading up about how to handle this sync issue I stumbled across the phrase Phase Locked Loop or PLL. In very simple terms, for what we are doing, the phase locked loop would dynamically adjusts the clock frequency (the 500khz) to compensate for frequency drift and variance in the signal.
The resolution on the timer wasn't high enough to vary it by smal enough amounts (e.g. 444khz, 470khz, 500khz, 533khz, 571khz etc.) and to perform this properly, I would probably need the code to run a whole lot faster.
The Arduino timers work by counting up to a predefined number (in this case 16 for 500khz) then they set an overflow register and start again from 0. The actual counter value can be read and written to at any point.
I adjusted the sketch to wait in a loop until the timer overflowed, and when it overflowed I checked for a pulse as before. The difference this time was that when a pulse was detected inside the loop, I reset the timer counter value to a pre-defined phase position, effectively resynchronising the timer with each pulse.
I chose the value I wrote to the timer counter such that it would overflow at 1µSec from the detection pulse (half way) so that next time the timer overflowed the pulse would have been 2µSec apart.
This worked! I was now reading almost perfect data from the disk. I was still getting a lot of checksum errors which was annoying. I resolved most of these by continuously re-reading the same track on the drive until I had all 11 sectors with valid header and data checksums.
I was curious at this point, so I hooked it all back up to the oscilloscope again to see what was going on now, and as I guessed, I could now see both traces as they were both staying in sync with each other:
I would love to see this a little clearer, if anyone wants to donate me a lovely top of the range digital oscilloscope (e.g. one of them Keysight ones!) I would really appreciate it!
Attempt 5:I wondered if I could improve on this. Looking at the code, specifically the inner reading loop (see below) I had a while loop waiting for the overflow and then an inner if looking for a pulse to sync to.
A fragment of code used to read the data and sync to it:
register bool done = false;
// Wait for 500khz overflow
while (!(TIFR2&_BV(TOV2))) {
// falling edge detected while waiting for the 500khz pulse.
if ((TCNT0) && (!done)) {
// pulse detected, reset the timer counter to sync with the pulse
TCNT2=phase;
// Wait for the pulse to go high again
while (!(PIN_RAW_FLOPPYDATA_PORT & PIN_RAW_FLOPPYDATA_MASK)) {};
done = true;
}
}
// Reset the overflow flag
TIFR2|=_BV(TOV2);
// Did we detect a pulse from the drive?
if (TCNT0) {
DataOutputByte|=1;
TCNT0=0;
}
I realised that depending on which instruction was being executed in the above loops, the time between pulse detection and writing TCNT2=phase;
could change by the time taken to execute a few instructions.
Realising that this may be causing some errors/jitter in the data and also with the above loop it is possible I might actually miss the pulse from the drive (thus missing a re-sync bit) I decided to take trick from one of my earlier attempts, the ISR (interrupt).
I wired the data pulse to a second pin on the Arduino. The data was now connected to the COUNTER0 trigger and now also the INT0 pin. INT0 is one of the highest interrupt priorities so should minimise the delays between trigger and the ISR being called, and as this is the only interrupt I am actually interested in al of the others are disabled.
All the interrupt needed to do was perform the re-sync code above, this changed the code to look like this:
// Wait for 500khz overflow
while (!(TIFR2&_BV(TOV2))) {}
// Reset the overflow flag
TIFR2|=_BV(TOV2);
// Did we detect a pulse from the drive?
if (TCNT0) {
DataOutputByte|=1;
TCNT0=0;
}
The ISR looked like this: (note I didnt use attachInterrupt as this also adds overhead to the call).
volatile byte targetPhase;
ISR (INT0_vect) {
TCNT2=targetPhase;
}
Compiling this produced far too much code to execute fast enough. In fact disassembling the above produced:
push r1
push r0
in r0, 0x3f ; 63
push r0
eor r1, r1
push r24
lds r24, 0x0102 ; 0x800102
sts 0x00B2, r24 ; 0x8000b2
pop r24
pop r0
out 0x3f, r0 ; 63
pop r0
pop r1
reti
By analysing the code I realised there were only a few instructions I actually needed. Noting that the compiler would keep track of any registers I bashed, I changed the ISR as follows:
volatile byte targetPhase asm ("targetPhase");
ISR (INT0_vect) {
asm volatile("lds __tmp_reg__, targetPhase");
asm volatile("sts %0, __tmp_reg__" : : "M" (_SFR_MEM_ADDR(TCNT2)));
}
Which disassembled, produced the following instructions:
push r1
push r0
in r0, 0x3f ; 63
push r0
eor r1, r1
lds r0, 0x0102 ; 0x800102
sts 0x00B2, r0 ; 0x8000b2
pop r0
out 0x3f, r0 ; 63
pop r0
pop r1
reti
Still too many instructions. I noticed that the compiler was adding a lot of extra instructions, that for my application really didnt need to be there. So I looked up the ISR() and stumbled upon a second parameter ISR_NAKED. Adding this would prevent the compiler from adding any special code, but then I would be responsible for maintaining registers, the stack and returning from the interrupt correctly. I also would need to maintain the SREG register, but as none of the commands I needed to call modified it I didn't need to worry about it.
This changed the ISR code to become:
ISR (INT0_vect, ISR_NAKED) {
asm volatile("push __tmp_reg__"); // Preserve the tmp_register
asm volatile("lds __tmp_reg__, targetPhase"); // Copy the phase value into the tmp_register
asm volatile("sts %0, __tmp_reg__" : : "M" (_SFR_MEM_ADDR(TCNT2))); // Copy the tmp_register into the memory location where TCNT2 is
asm volatile("pop __tmp_reg__"); // Restore the tmp_register
asm volatile("reti"); // And exit the ISR
}
Which the compiler converted to:
push r0
lds r0, 0x0102 ; 0x800102
sts 0x00B2, r0 ; 0x8000b2
pop r0
reti
Five instructions! Perfect, or at least as fast as it was going to be, theoritically taking 0.3125µSec to execute! This should now mean the re-sync should happen at time-consistant periods after the pulse. Below is a timing diagram of what is going on. This is how you recover data from a serial data feed that doesnt have a clock signal:
This improved the results a little. It’s still not perfect. Some disks read perfectly every time, some disks it takes ages and has to keep retrying. I am unsure if this is because some of the disks have been sitting there for so long that the magnetism has degraded to such a low level that the drives amplifiers can't cope with it. I wondered if this was something to do with the PC floppy disk drive, so I connected this up to an external Amiga floppy disk drive I had, but the results were identical.
Attempt 6:I wondered if there was anything else that could be done. Perhaps the signal from the drive was more noisy than I thought it had been. After reading further information I discovered that a 1KOhm pullup resistor was the norm, fed into a Schmitt trigger.
After installing an SN74HCT14N Hex Schmitt Trigger and reconfiguring the sketch to trigger on rising edges instead of falling edges I gave it a try, but it didn't really make any noticeable difference. I guess as I was looking for one or more pulses each time this probably absorbed any noise anyway. So we'll stick method Attempt 5!
My final breadboard solution looked line this:
Note the wiring on the above is slightly different to the live sketch. I re-ordered some of the Arduino pins to make the circuit diagram easier.
Attempt 7:I was a little dissatisfied with some of the disks I had not reading. Some times the disks just didn't sit correctly in the floppy drive. I guess the spring on the shutter wasn't helping.
I started looking at detecting if there were any errors in the actual received MFM data from the disk.
From the rules of how MFM encoding works, I realised that a few simple rules could be applied as follows:
- There cannot be two '1' bits next to each other
- There cannot be more than three '0' bits next to each other
Firstly when decoding MFM data I looked to see if there were two '1's in a row. If they were I assumed that the data had got a little blured over time and ignored the second '1'.
With this rule applied, there are literally three situations of 5 bits where errors are left to occur. This would be a new area where I could look to improve the data.
Mostly though, I was suprised there really weren't that many MFM errors detected. I am a little confused why some of the disks won't read when no errors are found.
This is an area for further investigation.
DecodingAfter reading how MFM worked, I wasn’t entirely sure how it aligned correctly.
At first I thought that the drive output 1s and 0s for the on and off bits. This wasn’t the case. The drive outputs a pulse for every phase transition, ie: every time the data went from 0 to 1, or 1 to 0.
After reading this I wondered if I needed to convert this back into 1’s and 0s by feeding it into a flip-flop toggle, or read the data, search for sectors, and if none were found then invert the data and try again!
It turns out this isn’t the case and it’s much simpler. The pulses are actually the RAW MFM data and can be fed straight into the decoding algorithms. Now I understood this I started writing code to scan a buffer from the drive and search for the sync word 0x4489. Surprisingly I found it!
From the research I had conducted, I realised I needed to actually search for 0xAAAAAAAA44894489 (a note from the research also suggested that there were some bugs in early Amiga code that meant that the above sequence wasn’t found. So instead I searched for 0x2AAAAAAA44894489 after ANDing the data with 0x7FFFFFFFFFFFFFFF).
As expected I found up to 11 of these on each track corresponding to the actual start of the 11 Amiga sectors. I then started to read the bytes that followed to see if I could decode the sector information.
I took a snippit of code from one of the above references to help with MFM decoding. No point in re-inventing the wheel eh?
After reading the header and data, I tried writing it to disk as an ADF file. The standard ADF file format is very simple. It is literally just the 512 bytes from each sector (from both sides of the disk) written in order. After writing it and trying to open it with ADFOpus and got mixed results, sometimes it opened the file, sometimes it failed. There were obviously errors in the data. I started to look at the checksum fields in the header, rejecting sectors with invalid checksums and repeating reading until I had 11 valid ones.
For some disks this was all 11 on the first read, some took several attempts and different phase values too.
Finally I managed to write valid ADF files. Some disks would take ages, some literally the speed the Amiga would have read them. Not having a working Amiga anymore I couldn’t actually check if these disks read properly normally, they’ve been stored in a box in the attic for years so may well have degraded.
So What's Next?Next has already happened - V2 is available here and has improved reading and writing support!
Well, firstly, I have made the entire project free and open source under GNU General Public Licence V3. If we want to have any hope of preserving the Amiga then we shouldn't be ripping each other off for the privilege, and besides, I want to give back to the best platform I ever worked on. I’m also hoping people will develop this and take it further and keep sharing.
I'm next want to look at other formats. ADF files are good, but they only work for AmigaDOS formatted disks. There are lots of titles with custom copy protection and non-standard sector formats that simply cannot be supported by this format.
According to Wikipedia there’s another disk file format, the FDI format. A universal format that’s well documented. The advantage of this format is it tries to store the track data as close to the original as possible so hopefully will fix the above issues!
I also came across the Software Preservation Society, specifically CAPS (formally the Classic Amiga Preservation Society) and their IPF format. After a little bit of reading I was very disappointed, its all closed, and it felt like they were just using this format to sell their disk reading hardware.
So my focus will be on the FDI! format. My only concern here is with data integrity. There won't be any checksums for me to check against to see if the read was valid, but I have a few ideas to resolve that!
And finally I will also be looking it adding a write disk option (possibly supporting FDI as well as ADF), as it really shouldn’t be that difficult to add.


_3u05Tpwasz.png?auto=compress%2Cformat&w=40&h=40&fit=fillmax&bg=fff&dpr=2)
{kind=link}
{kind=link}
Comments