


Hardware components | ||||||
 |
| × | 2 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 10 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
In my first year at college, I was inspired by a senior of mine who back in 2016 showed a demo of a self-driving car. I was inspired by him. Even I wanted to make something like that. I started with image processing and progressed to deep learning. In my third year at college, I thought of making a self-driving car(prototype). At that point in time, I thought if I could put the entire mechanism on top of a blind's head, it can help him navigate. That is when I started working on the idea.
I thought I will use convolutional neural networks. But I didn't have data available online according to my needs. So I used to go for a run around my college, and record videos while moving in the left, right and center lane. I converted the video into images using OpenCV, and I had labeled data.
Example of images of left, center and right lane are:
I had a laptop with an Nvidia graphics card. So I used to train my model on different architectures with different hyperparameters. I got a model that gave good accuracy.
The loss vs iterations curve is as follows:
The model is very accurate and works for both roads and off roads.
Then I plugged in a pair of earphones (the earphones gave me pre-recorded instructions) and used to run my trained model on my laptop. But I found out that it was very annoying that I was instructed for my direction every second. So I thought of giving haptic feedback.
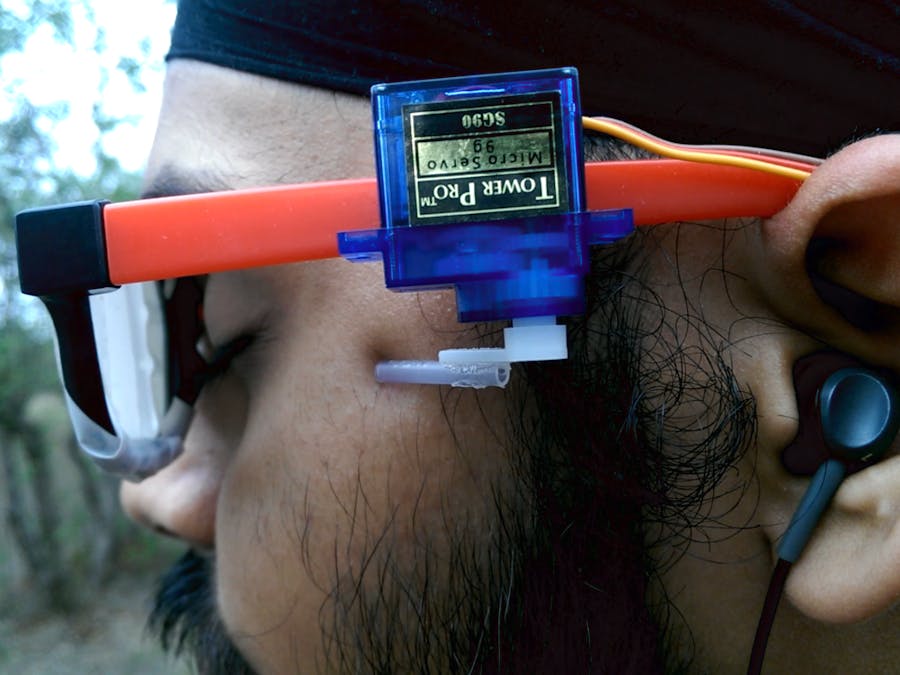
I connected a pair of servo motors to spectacles. They would instruct me on the direction to move in by poking into my head. Now through earphones, I could make the blind person aware of his surroundings, like telling him/her about the faces recognized by the system.
There is a big problem though, I have to carry my laptop with me for navigation. I thought of solving this using cloud services, but latency was a problem there. Raspberry pi would often crash. So I was thinking of buying something which is small in size and can run deep neural networks. There was nothing available apart from Nvidia high end embedded solutions like Jetson TX1, TX2. But they were expensive for me.
Everything till now version 1.
But then I got JETSON NANO (Thanks to NVIDIA).
DeepWay Version 2The main problems with the previous version were
1. I had to carry my laptop for computation, now I have Jetson Nano.
2. The solution was implemented in Keras, which I thought was beginner-friendly but the control it gave was not enough, so I switched to Pytorch.
3. The information from the Lane detection model was very abstract, I wanted more information. So I have trained a road segmentation model.
4. It assumed there was nobody on the road. Now I have added pedestrian detection.
It's been almost 1.5 years since I started this project. The development pace has reduced because I had been learning about new things like motion planning to further improve my project. The 1.5 months have been awesome, I have implemented a lot of things for this project.
I have explained version 2 in detail in my GitHub repository (ReadMe) linked down below, with a demo video.Here is a video of version 1.
_6ijVPVbHCB.png)
_6ijVPVbHCB.png){kind=link}

Comments