




Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
In a highly urbanized city like Singapore, human-wildlife conflict (HWC) has been increasingly prevalent. Detection of wildlife crossing into urban boundaries is key for the management and study of wildlife. The traditional approach is manual and labor-heavy, and as such, automation using computer vision (CV) at the edge could enhance detection and study. Xilinx Kria KV260 is a development platform built for advanced vision application and in this project, we demonstrated its use for the detection of wildlife at boundaries between the urban city and the natural conservations. The initial focus is set on the detection of Macaques as their presence is more high-profile and common, especially in Nanyang Technological University (NTU), Singapore.
Xilinx Kria KV260 is a development platform built for advanced vision application and in this project, we demonstrated its use for the detection of wildlife at boundaries between the urban city and the natural conservations.Proposed Solution
Using CV at the edge, animals such as wild boars, macaques, and even pythons could be detected in urban areas quickly. With the ubiquity of smartphones in Singapore, early warnings could be sent to people in the vicinity with guidance to avoid interaction and conflicts between them and the community. Such early detection would also allow a better understanding of urban-wildlife interfaces in the city, providing insights on the locations, and characteristics of the interfaces which will enable authorities to design mitigation strategies. While current solutions such as GPS collars for macaques tracking and studies on the population ecology of biodiversity in Singapore allow us to better understand the presence and behavior of macaques, these studies are limited to macaques at areas near the nature reserve and the conflict avoidance is done post-study. Having automation of the study and an early detection system would enhance preventive measures for HWC.
Therefore, Kria KV260 was used as an ideal platform to develop and deploy scalable CV solutions for HWC management quickly. With Zynq® UltraScale+™ MPSoC (Multiprocessor System-on-Chip) as the core, an accelerated application can be created without requiring in-depth hardware knowledge when Vitis Video Analytics SDK is used. The availability of different object detection models (e.g., single-shot detection/SSD, YOLO) and support for customized models (Tensorflow, PyTorch, and Caffe) allow for flexible and scalable solutions. With multiple internet connectivity options, the Kria KV260 can be paired with simple Telegram bots to send warnings of wildlife sightings. This serves to reduce HWC and allow for sightings to be logged for further analysis.
With the general idea and focus decided, the overall project was segmented to better track progress and set smaller milestones. As the core of the project relies on computer vision, the project was structured similar to a machine learning project. The main 8 segments consists of:
- Problem Understanding - Researching about the problem and reviewing the idea
- Device Understanding and Familiarising - Getting to know how to use the Kria KV260
- Data Acquisition - Finding data that is best suited for the task and doing data analysis and cleaning
- Model - Building - Building the CV model and checking the performance
- Model - Deployment - Deploying the CV model onto the hardware and testing
- Solution Features Fulfilment - Addition of supporting features
- Evaluation - Validating the capability of the solution
- Project Documentation and Submission - Documentation
With the problem defined and the milestones set, the first step is to understand how to use Kria KV260 by first setting up the hardware. Within the Kria KV260 Vision Starter Kit, most of the hardware required for basic deployment are already available, namely the cables for power, data transfer (USB), display (HDMI), and connectivity of an SD card, and lastly, a small camera module. However, as the small camera module is not of sufficiently high quality, a separate camera was used instead, namely the Logitech C920 webcam. For the full list of supported peripherals that have been tested for maximum platform performance, visit the "Supported Peripherals" Section in the User guide.
For the initial phase of learning about the Kria KV260, the smart camera app can be implemented following the tutorial on the Getting Started page (Or the NLP-SmartVision). It consists of:
a) Flashing the Vitis AI Starter Kit SD Card Image using Balena Etcher (Choice of either Ubuntu or Petalinux).
b) Connecting up the power supplies, SD card, ethernet cable, etc.
c) Booting up the kit using your terminal (e.g. Teraterm, PuTTy) based on the configuration based on the Getting Started page.
d) Launch the smart camera app (or the NLP-SmartVIsion app).
For the deployment of other applications or customized models, steps a) - c) remains consistent for the initial setup of the platform. Some useful commands are listed below for setting up Kria KV260 and launching the application.
sudo xmutil getpkgsThe above command allows you to get the list of the available package groups.
sudo dnf install <package group>The above command allows you to install the application package group based on the available package groups. e.g. <package group> = packagegroup-kv260-smartcam.noarch
sudo xmutil listappsThe above command allows you to list the existing application firmware available.
sudo xmutil unloadappThe above command is used to unload the default “kv260-dp” application firmware before you can load other application firmware.
sudo xmutil loadapp kv260-smartcamThe above command is used to load the selected application (e.g. kv260-smartcam in this case) after the default application firmware has been unloaded.
sudo smartcam --mipi -W 1920 -H 1080 -r 30 --target dpTo run the application, the name of the application is first invoked (smartcam) followed by the configuration. If a USB camera is used instead of the original camera module, the command is modified by having --mipi replaced with --usb 0. For more details about the Smart Camera accelerated application and customisation options, visit the GitHub page.
However, the Smart Camera App only works with Caffe SSD object detectors. To deploy custom object detection models (such as YOLOv5) and custom pipelines, the Starter Kit image cannot be used.This DPU image has to be used instead.
In step a) above, instead of using the Starter kit image, this DPU image must be used instead to enable VART (Vitis AI Runtime). With VART, we have direct control over the process of running model inference on the DPU, making writing apps much easier. The image also configures the DPU (Deep Learning Processing Unit) to B4096. For a deeper understanding of the different DPU architecture, please visit the Hardware Accelerator Page of the Xilinx GitHub page or the documentation page for the Zynq DPU product guide.
Step 2 - Data Acquisition and UnderstandingWhile learning more about the problem statement and the hardware platform itself, research was done to acquire a dataset that could fulfil our goal. As mentioned previously, while HWC in Singapore may include wildlife such as wild boar, python, pangolin, and even otters, macaques are the focus of the preliminary solution. As such, our team came across this dataset called MacaquePose (maintained by Jumpei Matsumoto, Tomohiro Shibata, and Ken-Ichi Inoue) which is suitable for training a macaque detection model. The open dataset consists of images of macaques with manually annotated labels that are compatible with the Microsoft COCO Keypoint Dataset. For more details on the dataset, please visit the original article.
While the labels consist of positions of key points selected, the task of object detection will not require as many key points and instead will require a bounding box. For the conversion of the existing keypoint positions to bounding box positions, a simple script involving the finding of both the minimum and maximum x and y coordinates was written. The script can be accessed in this project's repository.
Additionally, several images of macaques were sourced from fellow NTU students who captured the photos of macaques in the vicinity of the halls. These data will serve as a more accurate understanding of the performance especially if we are to deploy and test the proposed solution within NTU. Thus, the model was also trained using the dataset from the NTU.
Vitis AI is a development stack that includes artificial intelligence (AI) model zoo, optimiser, compiler and many other framework and tools for AI deployment on some of Xilinx's hardware. The model zoo offers many different models such as ResNet50, MobileNet, YOLOv4, and VGG in Caffe. TensorFlow and PyTorch. On the other hand, the building of different models and architecture for Xilinx's platforms is made possible using the Vitis AI stack. Multiple tutorials on how to use Vitis AI can also be found here.
To better understand how to use the Vitis AI Runtime (VART) and the Vitis AI stack, the approach we took was to implement different models from the default smart camera app to Kria KV260. This involved mainly downloading the required files and following the instructions on the Github page for the model zoo. The resources available allow you to quickly deploy the model (.xmodel) to the platform or provide you with some libraries and code to process data and train the specific model.
On the other hand, customised models or architectures can be deployed by using the Vitis AI stack to quantise and compile for the target platform (KV260). For PyTorch, the process usually requires 4 main steps
- Calibrate
- Evaluate - Optional, to see performance drop after quantisation
- Export to.xmodel
- Compile quantised.xmodel to KV260 platform
As a practice, we successfully quantised and exported torchvision's ResNet models for deployment on Kria KV260. More details can be found on our GitHub repo.
For the actual object detection task, we use CenterNet, a fast, anchor-free object detector, with Darknet backbone. Darknet was first popularised by the YOLO object detector series. We use the Darknet variant from YOLOv5 family. The code for exporting CenterNet for KV260 can be found here.
We will cover the general steps of converting an existing PyTorch model for deployment to KV260. Before starting, a setup step is required to get the initial quantised model:
from pytorch_nndct.apis import torch_quantizer
model = ... # create your model here
quantizer = torch_quantizer(mode, model, sample_input, output_dir=...)
quant_model = quantizer.quant_model # initial quantised model1) Calibration
This step is the main quantisation step where the quantised weights and parameters are obtained from the original model. Quantisation is commonly used to quantise models to lower precision (e.g. float-32 to int-8) such that the model can be deployed to embedded devices with limited precision and resources. Different quantisation methods such as post-training quantisation (PTQ), Quantization-aware training (QAT), and fast-finetuning are available.
To start calibration, the mode in the setup step has to be specified to 'calib'. The example below shows the setup and the optional finetuning approach. The final quantised model is then exported to a specified directory, which includes "Model.py", "Quant_info.json", and "bias_corr.pth".
from pytorch_nndct.apis import torch_quantizer
model = ...
quantizer = torch_quantizer(mode='calib', model, sample_input, output_dir=...)
quant_model = quantizer.quant_model
# you need to prepare a calibration dataset
# the images can be from your validation set during training
dataloader = ...
# do forward passes on your sample data
# you don't need to return anything
# quantisation parameters are updated in the background
with torch.no_grad():
for data in dataloader:
quant_model(data)
# export quantization data
# “Model.py”,“Quant_info.json”, and “bias_corr.pth”
quantizer.export_quant_config()Sample terminal output can be looked like this (CUDA is not found since we use Vitis AI CPU Docker Image)
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
[VAIQ_NOTE]: Loading NNDCT kernels...
[VAIQ_WARN]: CUDA is not available, change device to CPU
[VAIQ_NOTE]: Quantization calibration process start up...
[VAIQ_NOTE]: =>Quant Module is in 'cpu'.
[VAIQ_NOTE]: =>Parsing CenterNet...
[VAIQ_NOTE]: =>Doing weights equalization...
[VAIQ_NOTE]: =>Quantizable module is generated.(centernet_quantize/CenterNet.py)
[VAIQ_NOTE]: =>Get module with quantization.
Discovered 13083 images
100%|##############################################################################| 25/25 [08:58<00:00, 21.52s/it]
[VAIQ_NOTE]: =>Exporting quant config.(centernet_quantize/quant_info.json)2) Evaluation
In the setup step with mode='test' and the same output directory in 1) Calibration, the evaluation metrics can be obtained with the quantised model with comparison to the original non-quantised model. For image classification, the metric can be classification accuracy. For object detection, the metric is mAP (mean Average Precision).
3) Export
In the setup step with mode='test' and the same output directory in 1) Calibration, the.xmodel file can be obtained as shown in the example below:
# do 1 forward pass
with torch.no_grad():
quant_model(data)
# export xmodel
quantizer.export_xmodel(output_dir=...)4) Compilation
Once the.xmodel is obtained and set in the correct directory, the model can be compiled before running the model. The compilation can be done as followed:
vai_c_xir -x CenterNet_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.json -o compile-a specifies the DPU architecture target to compile to. These architecture fingerprints are stored within the Vitis AI Docker images. Since we are targeting KV260, the path to its architecture file is as above.
This is the output for compiling our CenterNet model
**************************************************
* VITIS_AI Compilation - Xilinx Inc.
**************************************************
[UNILOG][INFO] Target architecture: DPUCZDX8G_ISA0_B4096_MAX_BG2
[UNILOG][INFO] Compile mode: dpu
[UNILOG][INFO] Debug mode: function
[UNILOG][INFO] Target architecture: DPUCZDX8G_ISA0_B4096_MAX_BG2
[UNILOG][INFO] Graph name: CenterNet, with op num: 443
[UNILOG][INFO] Begin to compile...
[UNILOG][INFO] Total device subgraph number 4, DPU subgraph number 1
[UNILOG][INFO] Compile done.
[UNILOG][INFO] The meta json is saved to "/macaque-detection/kv260_centernet/centernet_darknet/compile/meta.json"
[UNILOG][INFO] The compiled xmodel is saved to "/macaque-detection/kv260_centernet/centernet_darknet/compile/deploy.xmodel"
[UNILOG][INFO] The compiled xmodel's md5sum is ab61a01c5248d5ffe8d59f3fb0ecc50e, and has been saved to "/macaque-detection/kv260_centernet/centernet_darknet/compile/md5sum.txt"The subgraph number allows users to check validity of the model, as it specifies which are the parts of the network which are accelerated on DPU.
Deployment
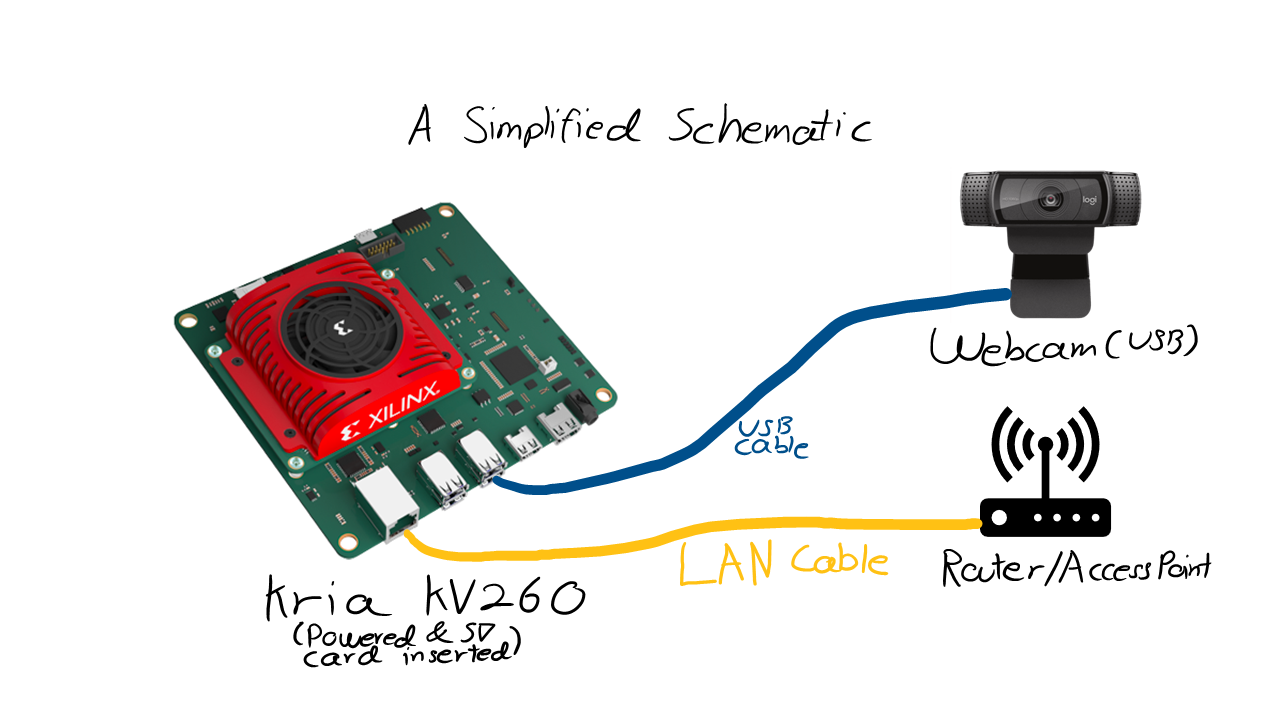
The image above shows the hardware schematic for the setup with the router, Logitech C290 (Image source) and Kria KV260 (Image source). The overall model building and deployment to Kria KV260 may be challenging especially for beginner, but here are some resources which were helpful in our journey:
- Vitis AI User Guide (PDF / Interactive Web)
- GitHub repo and tutorials for Vitis AI
- Our GitHub repo
- VITIS AI VART Programming API
Once the model is exported to Kria KV260 itself, the model can then be deployed as part of an application. Vitis AI offers APIs for application creation which are available in both C and Python. In this project, we used the python's API to create the application.py (available in our GitHub repo) where we ran the model, obtain the result, do some post-processing to draw the drawing box, and finally send the detected macaque image to the telegram bot, which will be further explained in the next step.
The flowchart below shows the basic logic behind the application (app.py) which will run on KV260 and the actual app.py can be accessed in our GitHub repository as mentioned above.
In addition to being just a detector, by connecting the Kria KV260 to the internet via a LAN cable, the device can act as a host for the telegram bot for logging and warning of users in the telegram channel. In this project, the telegram bot was configured using pyTelegramBotAPI. The creation of the telegram bot was first done via the @BotFather before obtaining the API key for the specific bot. The API key was used by the pyTelegramBotAPI to configure the messages to be sent when a macaque is detected. To detect macaques, warn people in the vicinity, and enhance logging of macaque for further HWC studies, a telegram channel for the different areas/locations can be created for the messages to be sent when a macaque is detected using the KV260.
To initialize the bot in the application, the command below can be used, with the API_KEY being the key to the bot created.
import telebot #telebot is the telegram bot api
BOT = telebot.TeleBot(API_KEY)As each Kria KV260 will cover an area specifically, the location of the device should be unique to each device, and will be included in a simple message when a macaque is detected. To send the message to the channel, the command below can be used, with the CHANNEL_ID referring to the ID of the channel :
BOT.send_message(CHANNEL_ID, message)For an in-depth tutorial on how to create a telegram bot using the API, visit the official documentation page for pyTelegramBotAPI.
Step 6 - EvaluationOn MacaquePose dataset, we achieved 68.25 mAP on the validation set.
The actual macaque detection scenarios in NTU are much more challenging.
Our model was trained in 2 steps: (1) pre-training on the MacaquePose dataset, then (2) fine-tuning on NTU data. Pre-training helps with model generalisation as the MacaquePose dataset covers more diverse images of macaques, in many different scenarios.
On MacaquePose dataset, we achieved 68.25 mAP on the validation set.
The actual macaque detection scenarios in NTU are much more challenging. Usually the macaques are far away from the camera: the model must be able to detect accurately small objects. Although our model still performs reasonably well after fine-tuning, we could only achieve 15.86 mAP on our NTU dataset.
A short demonstration of the overall solution in action can be seen below:
The Kria KV260 has been demonstrated to be capable of detecting macaques and warning humans of wildlife to reduce human-wildlife conflicts (HWC). The use of Kria KV260 helped to allow accelerated macaque detection on the edge while hosting a telegram bot to aid in communication after detection. With telegram bot and telegram channel as the main channel of communication, it allows for both large-scale dissemination of macaque detection warnings and facilitates the automatic logging of detections for future HWC studies.
The use of Kria KV260 helped to allow accelerated macaque detection on the edge while hosting a telegram bot to aid in communication after detection.
Currently, the demonstrated solution in the project has limited performance in terms of model accuracy, and completeness of telegram bot (additional options and features to aid in warnings, logging, and improvement of user experience). Moreover, the solution is currently limited to macaques and other wildlife animals can also benefit from this solution. Further experimentation, and study with domain experts will be required for the successful deployment of the wildlife detector using Kria KV260 in HWC management.
Nonetheless, the Kria KV260 implementation as a macaque detector serves as a starting point for improved HWC communication and management experiments in the future. The characteristics of Kria KV260 with the plethora of supporting tools allow for flexible and scalable approaches which could potentially help in HWC communication and management.




{kind=link}
Comments
Please log in or sign up to comment.